과적합
과적합이란 개념이 등장한다
일단 머신 러닝의 일반적인 절차는,
- 학습 대상이 되는 데이터에 정답(label)을 붙여서 학습 시키고,
- 모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 “답”을 얻고자 하는 것
일단 우리는 DecisionTreeClassifier를 통해 accuracy가 매우 좋은 모델을 얻어냈었다.
그 Decision Tree를 출력해보기
import matplotlib.pyplot as plt
from sklearn import tree
fig = plt.figure(figsize=(10, 6))
_ = tree.plot_tree(iris_tree, feature_names=['length', 'width']
class_names=list(iris.target_names), filled=True)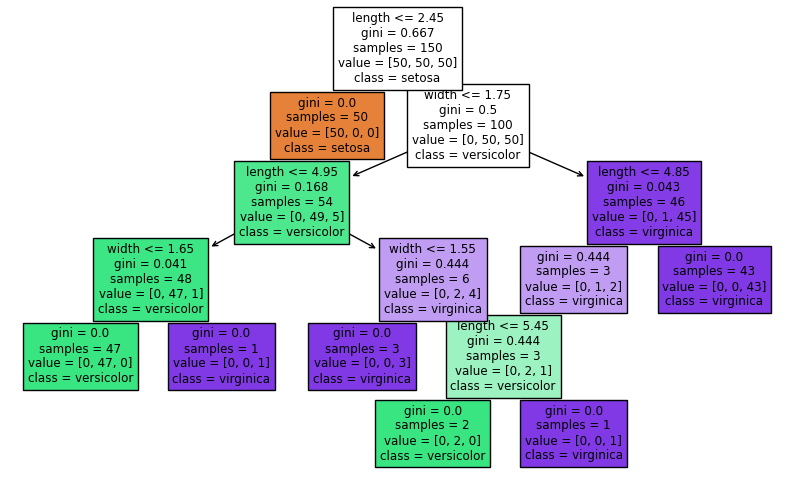
그리고, sklearn에 없는 몇몇 기능을 갖고 있는 mlxtend를 활용해볼 예정
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(10,6))
plot_decision_regions(X = iris.data[:, 2:], y=iris.target,
clf=iris_tree, legend=2
);plot_decision_regions에 clf 인자로 학습을 완료된 모델을 넘겨준다.
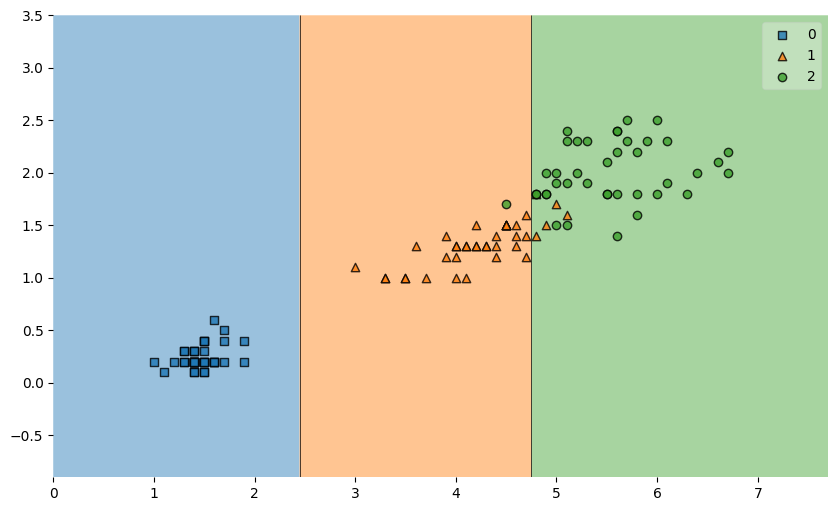
그럼 우리의 결정나무 모델이 데이터를 이렇게 분류했다는 것을 알 수 있다.
단순하게 분류된 0번 품종을 제외하고, 1과 2의 경계면이 올바르게 분류된 것인지에 대해서 생각이 필요하다. 새로운 데이터가 주어졌을 때, 저 경계면으로 일반화를 해도 될 것인지?에 대한 고민. 복잡한 경계면은 모델의 성능을 떨어트린다고 한다.
이렇게 모델이 복잡하게 학습 데이터에 너무 찰싹 달라붙은 것을 과적합(overfitting)이라고 한다. 이런 모델은 학습 데이터는 완벽하게 맞추지만, 처음 보는 데이터에서는 성능이 떨어진다고
아무튼 그래서, 훈련(training) 데이터와 테스트(test)에 쓰일 데이터를 분리하는 것이 필요함. 모델을 평가할 때 학습에 사용되지 않고 빼둔 데이터를 갖고 모델을 테스흐한다.
데이터의 분리
from sklearn.model_selection import train_test_split
features = iris.data[:, 2:]
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(
features, labels, test_size=0.2,
stratify=labels, # labels의 구조를 그대로 따라가라고 지정
random_state=13
)
이렇게.. 4개의 값을 반환하는 함수인 train_test_split을 통해 특성(features)과 정답(labels)을 분리해서 train 데이터와 test 데이터를 나눠준다.
- X_train: train 데이터 중 특성 데이터
- X_test: test 데이터 중 특성 데이터
- y_train: train 데이터에 대한 정답
- y_test: test 데이터에 대한 정답
*test_size=0.2는 < 훈련용:테스트용 = 8:2 >로 나눈다는 뜻
import numpy as np
np.unique(y_test, return_counts=True)
이렇게 잘 나뉜 것을 확인할 수 있다.
train 데이터만 대상으로 다시 결정나무 모델을 만들기!
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)max_depth=2는 2번만 나누라는 뜻 (과적합 방지, 모델을 복잡하게 하지 않고 단순화하기 위함)
train 데이터에 대한 accuracy score 확인
y_pred_tr = iris_tree.predict(X_train)
accuracy_score(y_train, y_pred_tr) 
0.95가 나온다. iris 데이터가 단순해서 accuaracy가 높게 나타나는거라고 함
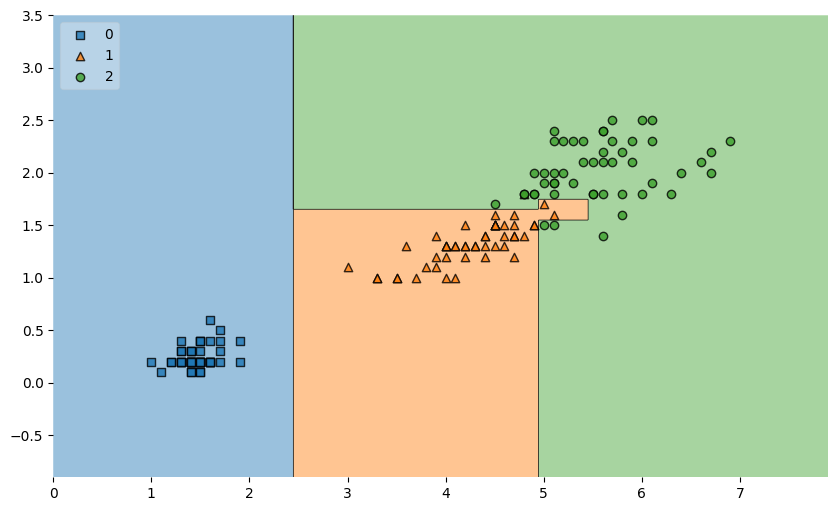
결정나무 모델도 다시 확인해보면.. 모델은 데이터를 이렇게 분류했음

plot decision regions로 결정경계를 다시 확인해보면 이전보다 단순해졌다.
성능평가
그럼 이제 test 데이터에 대한 성능을 확인해보면!
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)y_pred_test는 test 데이터의 예측 결과를 담을 변수
(학습을 완료한 iris_tree 모델한테 X_test 데이터를 주면서 예측하라고 시킨 것)
accuracy_score에 y_test(테스트 데이터의 정답), y_pred_test(모델이 예측한 데이터)를 넘겨준다.

0.96이라는 수치가 나온다. train 데이터의 accuracy와 약 1.6% 차이로, 이것을 다음과 같이 설명할 수 있다고 한다.
-> Iris 데이터는 train , test 데이터로 나누었을 때, max_depth 2로 선정한 decision tree에 대해서 차이가 없음
(이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.)
