
- 비슷한 특성을 지닌 데이터들끼리 묶어 K개의 군집으로 군집화
- 각 군집의 평균(mean)을 활용하여 K개의 군집으로 묶음
- 군집의 중심점을 centroid라고 함
K-Means 알고리즘 원리1
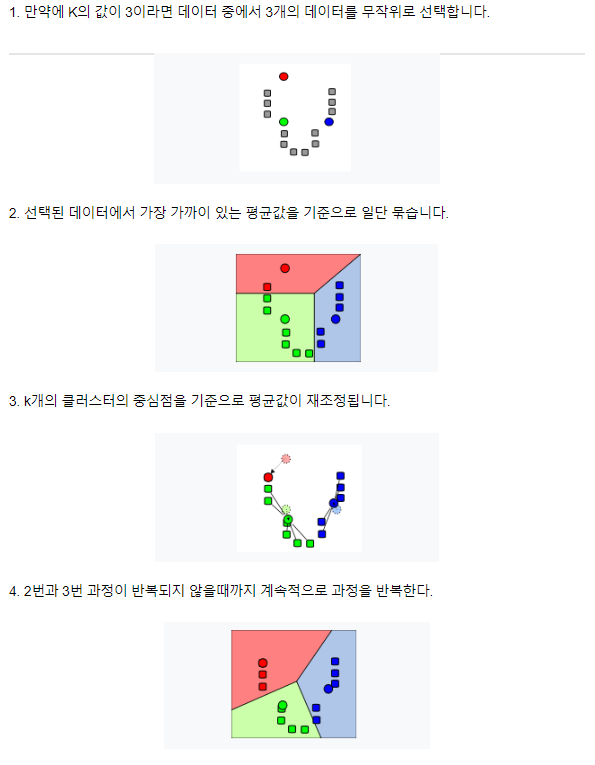
K-Means 알고리즘 원리2
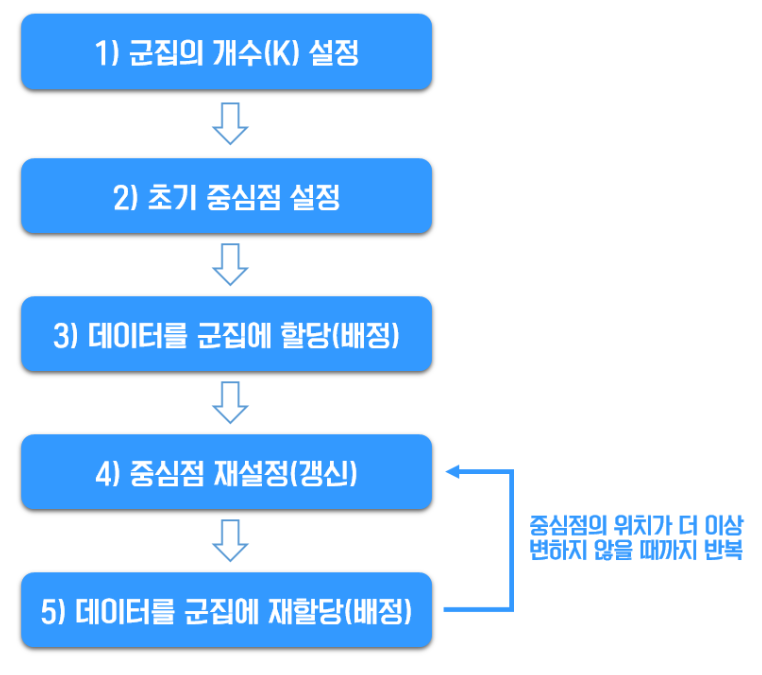
1) 군집수 K 설정하기
- K-Menas 알고리즘의 한계점 중 하나는 군집의 개수 설정을 어떻게 하느냐에 따라 결과가 크게 달라지며 터무니 없는 결과가 나올 수도 있다는 것
- 군집의 개수를 설정하는 방법 : Rule of thumb, Elbow Method, 정보 기준 접근법(Information Criterion Approach)
2) 초기 중심점(Center of Cluster, Centroid) 설정하기 - K-Means 알고리즘은 초기 중심점으로 어떤 값을 선택하는가에 따라 성능이 크게 달라지는 성질을 가지고 있음, 따라서 초기 중심값을 잘 설정해야 함
- 중심값 설정하는 방법 : Randomly select, Manually assign, K-Means++
(+) 랜덤하게 설정하거나 사람이 임의로 값을 설정해도 되지만 K-Means 알고리즘에서 실제 사용되는 초기 중심값 설정 방법은 K-Means++ 기법이라고 함
3) 데이터를 군집에 할당/배정하기 - 거리 상 가장 가까운 군집(중심점)으로 주어진 모든 데이터를 할당/배정함
4) 중심점 재설정/갱신하기 - 모든 주어진 데이터의 군집 배정이 끝나면 군집의 중심점(Centroid)을 그 군집에 속하는 데이터들의 가장 중간(평균)에 위치한 지점으로 재설정
5) 데이터를 군집에 재할당/배정하기 - 3)에서 했던 방법과 똑같이 시행하며, 더 이상 중심점의 이동이 없을 때까지 4)-5) 반복
