딥러닝 모델은 일반적으로 FP32(32비트 부동소수점) 연산을 사용한다. 이는 정확도는 높지만 연산량이 크고 메모리 사용량도 많다. 반면, 모바일엣지 디바이스에서는 저지연저전력 실행이 중요하다. 따라서 정수 기반 연산(INT8)으로 모델을 변환하면 메모리 절약 + 연산 속도 향상을 동시에 얻을 수 있다.
Google은 2018년, CNN을 정수 전용 연산(integer-arithmetic-only)으로 구현하는 8-bit 양자화 스킴을 제안했다. 이 연구는 이후 TensorFlow Lite의 기본이 되었으며, CNN 양자화 연구의 실질적 출발점이라 할 수 있다.(Jacob et al., 2018)
CNN 8비트 양자화의 핵심 이해
딥러닝 모델을 모바일이나 임베디드 환경에서 실행할 때는 속도와 메모리 효율성이 무엇보다 중요하다. 하지만 우리가 흔히 사용하는 딥러닝 모델은 FP32(32비트 실수) 연산을 기반으로 동작한다. 이는 정확도는 높지만, 계산량이 많고 전력 소모도 크다.
그래서 연구자들은 모델을 정수(INT8) 로 바꾸어도 정확도를 크게 잃지 않으면서, 더 빠르고 가볍게 만들 수 있는 방법을 고민했다. 이때 등장하는 것이 바로 CNN 8비트 양자화이다.
양자화의 핵심 공식
CNN 양자화의 원리는 다음 공식 하나로 요약된다:
여기서
- : 원래 모델의 실수 값 (FP32)
- : 양자화된 정수 값 (INT8, 예: −128
127 또는 0255) - (Scale) : 정수 한 칸이 얼마만큼의 실수 크기를 의미하는지 나타내는 눈금 간격
- (Zero-point) : 실수 0이 정수 눈금 어디에 놓일지를 정하는 기준점
즉, 이 공식은 정수 값과 실수 값을 잇는 변환 다리다.
정수로 바꾸는 과정(Quantization)은 다음과 같이 표현된다:
(단, 정수 범위를 넘는 값은 clamp 처리하여 잘라낸다.)
아래 그림은 실수 값과 정수 값이 어떻게 매핑되는지를 직관적으로 보여준다.
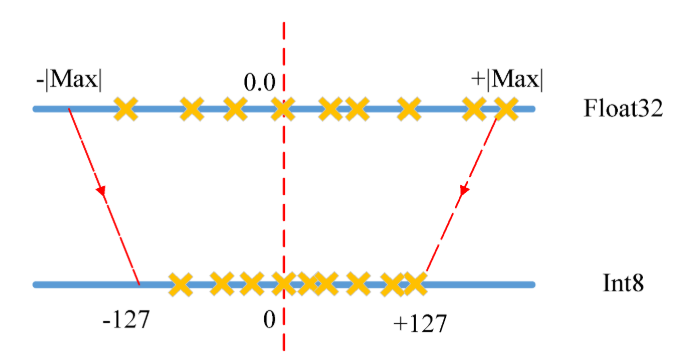
- 위쪽 Float32 축은 실수 값 범위(예: )
- 아래쪽 Int8 축은 정수 값 범위(−127 ~ +127)
- 빨간 화살표는 실수가 정수로 매핑되는 과정
- 노란색 X는 여러 실수 값이 가장 가까운 정수 값으로 이동한 모습
정리하면, S는 눈금자의 간격, Z는 0의 위치, q는 정수 눈금 위 값, r은 다시 환산된 실수 값이라고 할 수 있다.
즉, CNN 8비트 양자화란 “실수 축을 정수 눈금자로 바꾸어 연산하는 과정”이다. 계산은 조금 거칠어지지만, 훨씬 가볍고 빠르게 실행할 수 있다.
Zero-Point는 왜 필요할까?
만약 단순히 스케일만 적용한다면, 실수의 0.0이 정수에서 정확히 표현되지 않을 수 있다.
그렇게 되면 CNN에서 자주 쓰이는 패딩(0 채우기) 이나 Skip 연결 같은 연산이 꼬이게 된다.
이를 막기 위해 Zero-Point 가 필요하다.
제로포인트는 실수의 0을 특정 정수 값(보통 0)에 정확히 맞춰주는 역할을 한다.
Zero-Point가 0이 아닌 경우
보통 가중치(Weights) 는 분포가 대칭적이어서 으로 두지만, 항상 그런 것은 아니다.
-
데이터 분포가 한쪽으로 치우친 경우
예: ReLU 출력 범위 .
이때는 음수 구간에 눈금을 낭비하지 않도록 비대칭 양자화(asymmetric quantization)를 적용한다. -
출력이 음수 범위에만 있는 경우
예: 어떤 정규화 레이어가 범위를 가질 때.
이때도 0을 표현해야 하므로 Zero-Point가 정수 축 어딘가로 이동한다. -
실제 예시
범위가 라면,즉, 실수 0은 정수 171에 매핑된다.
따라서 Zero-Point가 0이 아닌 경우는 주로 비대칭 양자화에서 발생하며, 특히 활성화(activation) 양자화에서 자주 나타난다.
CNN 연산에서의 스케일 결합
CNN 연산은 기본적으로 곱셈과 덧셈의 반복이다.
양자화된 두 텐서가 각각 스케일 , 출력 스케일이 라면,
라는 값을 미리 계산해 두고, 정수 곱셈 결과(int8 × int8 → int32)에 한 번의 스케일 조정만 적용하면 된다.
즉, CNN의 무거운 연산은 모두 정수 전용 연산으로 수행하고, 마지막에만 스케일 보정을 해주는 것이다.
정리
- CNN 8비트 양자화는 실수를 정수 눈금자 위로 올려 연산하는 방식이다.
- 핵심 공식은
- Scale은 눈금 간격, Zero-Point는 0의 위치를 정한다.
- 대칭 양자화는 보통 가중치, 비대칭 양자화는 활성화에 쓰인다.
- CNN 연산은 “정수 곱셈 → 정수 누산 → 마지막에 스케일 보정”으로 효율적으로 구현된다.
결론적으로, CNN 8비트 양자화는 정수 연산만으로도 정확도를 크게 잃지 않고 모델을 구동할 수 있게 만든 핵심 기술이다.
특히 Google의 Jacob et al. (2018) 논문은 이 과정을 정립하며, TensorFlow Lite의 기반이 되었다.
훈련 방법: 시뮬레이션 기반 QAT
양자화를 가장 단순하게 적용하는 방식은 PTQ(Post-Training Quantization)이다.
학습이 끝난 모델을 그대로 정수 값으로 변환하는 방식인데, 문제는 작은 모델일수록 정확도가 크게 떨어진다는 점이다.
이를 해결하기 위해 논문에서는 QAT(Quantization-Aware Training)방법을 제안했다.
QAT의 핵심 아이디어는 훈련 과정에서부터 양자화를 시뮬레이션하는 것이다.
- Forward pass 단계에서는 가짜 양자화(fake quantization) 연산을 삽입해, 마치 INT8 환경에서 연산하는 것처럼 흉내를 낸다.
- Backward pass는 여전히 FP32로 진행되므로, 미세한 파라미터 업데이트가 가능하다.
이렇게 하면 모델이 학습 과정에서 양자화로 인한 손실에 적응하게 되고, 최종적으로 INT8 모델도 FP32로 진행되므로, 미세한 파라미터 업데이터가 가능하다.
즉, QAT는 "양자화 환경을 훈련 중에 미리 경험시켜서, 모델이 적응하도록 만드는 과정"이라고 이해할 수 있다.
실험 결과(Jacob et al., 2018)
ResNet(ImageNet)

ResNet-50 기준, 정확도 손실은 약 1.5%에 불과하였다.
Inception v3(ImageNet)
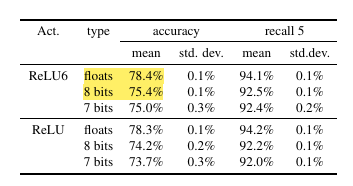
ReLU6 활성화를 사용할 경우 양자화에 더 강건하게 동작했다.
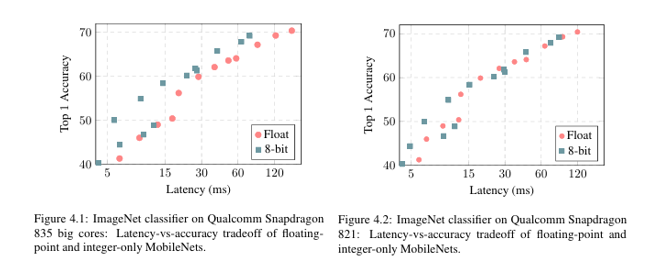
MobileNet (ImageNet/COCO)
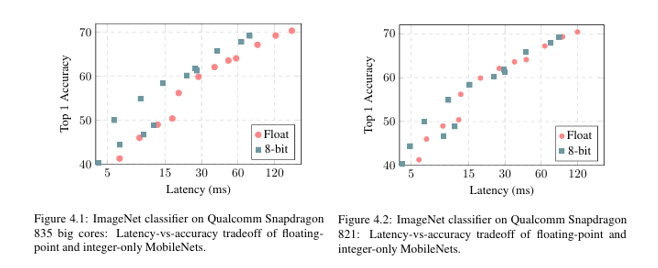
Snapdragon 835 LITTLE Core에서 실시간 30fps 실행이 가능하며, FP32 대비 최대 50% 속도 향상이 되었고, 정확도 손실은 약 1~2%**에 불과했다.
Object Detection(MobileNet SSD, COCO)
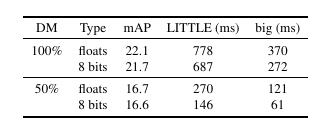
추론 속도는 약 2배 증가, 정확도 손실은 2% 미만, 모바일 환경에서 실시간 탐지 가능성을 입증했다.
CNN 8비트 양자화 연구의 의의와 한계
Jacob et al. (2018)의 연구는 CNN을 정수 전용 연산으로 안정적으로 실행할 수 있었음을 최초로 실증한 중요한 성과였다.
이전까지 양자화는 실험적인 수준에 머물렀지만, 이 논문은 실제로 ResNet, Inception, MobileNet 같은 널리 쓰이는 모델에 적용하여, FP32 대비 정확도 손실을 최소화하면서도 추론 속도를 크게 향상시킬 수 있음을 보여주었다.
특히 이 연구는 Google의 TensorFlow Lite 프레임워크에 직접 반영되었고, 이후 모바일 기기와 IoT 환경에서 활용되는 경량화 AI 모델의 기반 기술로 자리 잡았다.
즉, 단순한 이론적 제안이 아니라, 실제 제품과 서비스에 적용 가능한 수준으로 CNN 양자화를 끌어올린 것이다.
물론 한계도 분명히 존재했다.
첫째, 제안된 방법은 8비트 정수 범위에 국한되어 있었다. 이보다 더 낮은 정밀도(예: 4비트 이하)로 줄이면 정확도가 급격히 떨어져, 당시에는 초저비트 양자화까지는 적용하기 어려웠다.
둘째, 단순 PTQ(Post-Training Quantization) 방식만으로는 작은 모델에서 성능 저하가 뚜렷했다. 특히 MobileNet 같은 경량 모델은 PTQ 적용 시 정확도가 크게 떨어졌고, 이를 극복하기 위해서는 QAT(Quantization-Aware Training)이 필수적임이 강조되었다.
즉, Jacob et al. (2018)의 연구는 CNN 8비트 양자화를 실제 환경에서 가능하게 만든 "시작점"이지만, 동시에 더 낮은 비트 수로 확장하거나 PTQ만으로 정확도를 유지하는 문제는 여전히 해결 과제로 남아 있었다.
References
Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., … Kalenichenko, D. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. arXiv preprint arXiv:1712.05877.
