Vision을 위한 Quantization
1.딥러닝을 가볍게 만드는 기술, Quantization

양자화(Quantization)란, 연속적인 실수 값을 더 적은 비트 수로 표현되는 정수 값으로 근사하는 과정이다.딥러닝 모델에서는 보통 FP32 부동소수점을 사용하지만, 이를 INT8, INT4와 같은 저비트 정수로 변환하여 모델을 더 작고, 빠르고, 효율적으로 만드
2.CNN 8-bit Quantization: Jacob et al. (2018)
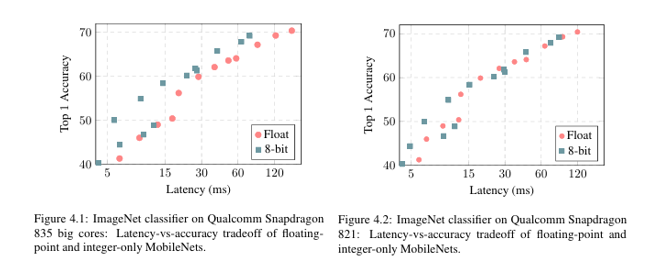
딥러닝 모델은 일반적으로 FP32(32비트 부동소수점) 연산을 사용한다. 이는 정확도는 높지만 연산량이 크고 메모리 사용량도 많다. 반면, 모바일$\cdot$엣지 디바이스에서는 저지연$\cdot$저전력 실행이 중요하다. 따라서 정수 기반 연산(INT8)으로 모델을 변환
3.CNN 8-bit Quantization: Jacob et al. (2018) 구현해보기

CNN 8-bit Quantization: Jacob et al. (2018)를 직접 Python 코드로 구현을 해보자.양자화 수식은 아래와 같다.$$r = S(q-Z)$$$$q = \\text{round}(\\frac{r}{S} + Z)$$이를 구현하려면 가장 먼저
4.HAWQ: Hessian AWare Quantization of Neural Networks with Mixed-Precision (2019) Paper Review
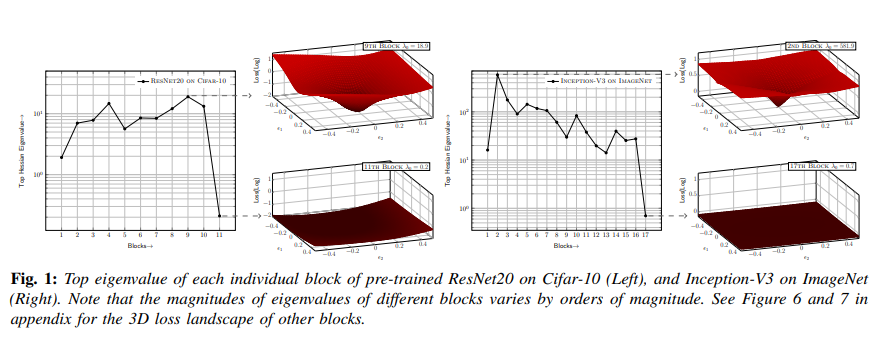
딥러닝 모델은 점점 더 커지고 입력 데이터의 해상도도 높아지고 있다. 예를 들어, 1998년 LeNet-5는 MNIST 28x28 이미지를 처리했지만, 20년 후 ImageNet은 그보다 200배 큰 해상도를 다루고 있으며, 모델 크기와 메모리 사용량도 수십 배 증가하
5.HAQ: Hardware-Aware Automated Quantization (2019) Paper Review
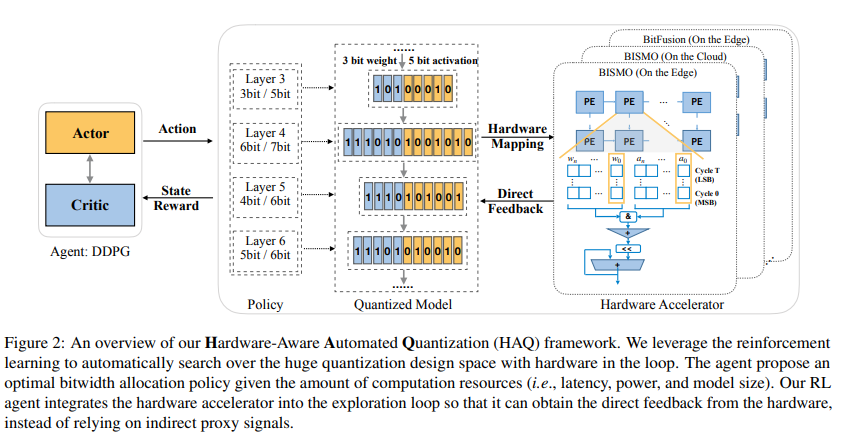
딥러닝 모델은 모바일, 자율주행, VR/AR 등에서 실시간 추론을 요구받는다. 그러나 하드웨어 자원은 제한적이며, 기존의 고정 비트 양자화(예: 전 레이어 8-bit) 방식은 효율성이 떨어진다.특히 각 레이어는 민감도와 연산 특성이 다르기 때문에 mixed precis
6.Up or Down? Adaptive Rounding for Post-Training Quantization(2020) Paper Review
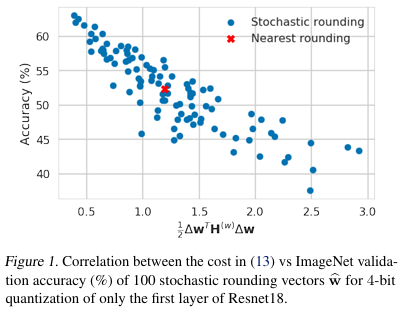
딥러닝 모델은 이제 이미지 분류, 번역, 음성 인식, 추천 시스템 등 다양한 분야에서 표준 도구처럼 쓰이고 있다. 하지만 이러한 성능 뒤에는 높은 연산량과 메모리 사용량이라는 부담이 따라온다. 대규모 모델을 클라우드에서 실행하면 인프라 비용이 커지고, 모바일이나 IoT
7.LSQ, Learned Step Size Quantization(ICLR, 2020) paper review
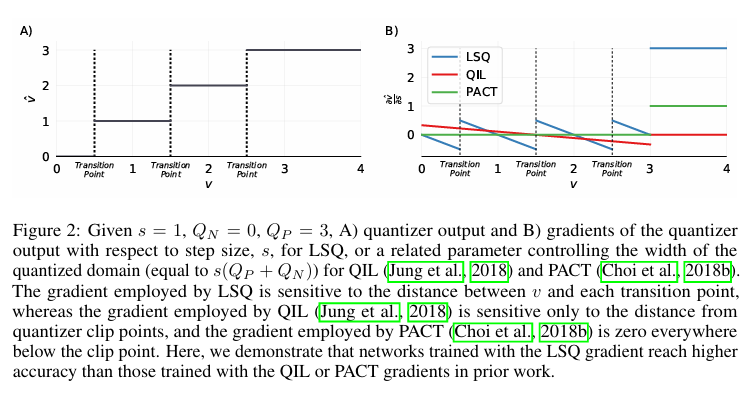
딥러닝 모델은 이미지 분류, 음성 인식, 자율 주행 등 다양한 분야에서 뛰어난 성능을 보여주지만, 연산량과 메모리 사용량이 매우 크다는 단점이 있다.이를 줄이기 위해 양자화(Quantization), 즉 가중치와 활성값을 낮은 정밀도의 정수(예: 8bit, 4bit)로
8.ZeroQ: A Novel Zero Shot Quantization Framework(CVPR, 2020) paper review
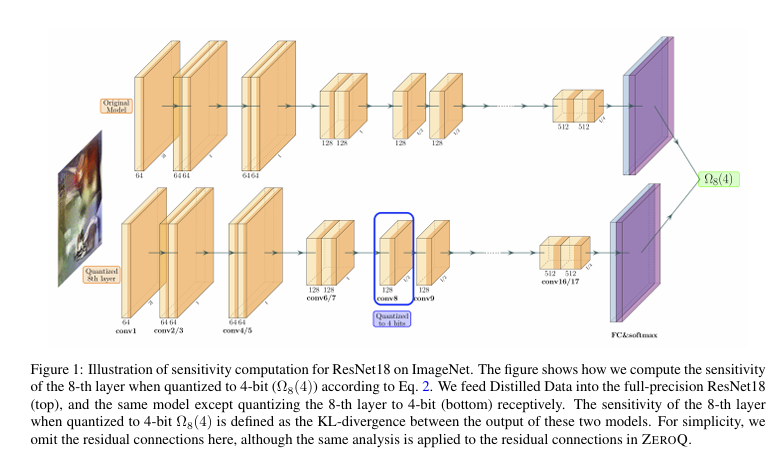
딥러닝 모델은 이미지 분류, 객체 탐지, 자연어 처리 등 다양한 분야에서 뛰어난 성능을 보이고 있다. 그러나 이런 모델들은 일반적으로 수백 MB에 이르는 큰 크기와 막대한 연산량을 필요로 한다. 실제로 스마트폰, IoT 기기, 자율주행 센서처럼 자원이 제한된 환경에 배
9.BRECQ: PUSHING THE LIMIT OF POST-TRAINING QUANTIZATION BY BLOCK RECONSTRUCTION(ICLR, 2021) paper review
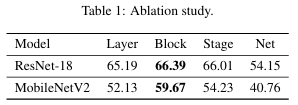
양자화는 부동소수점 연산을 정수 연산으로 변환하여 메모리 사용량을 줄이고 연산 속도를 높이는 방법이다. 일반적으로 Quantization-Aware Training(QAT)과 Post-Training Quantization(PTQ) 두 가지 접근법이 존재한다. 하지만
10.Q-ViT: Accurate and Fully Quantized Low-bit Vision Transformer(NeurlPS, 2022) paper review

트랜스포머(Transformer)는 원래 자연어 처리 분야에서 큰 성공을 거둔 모델 구조이다. 이 구조는 Self-Attention 메커니즘을 통해 입력 간의 장거리 의존성을 효과적으로 학습할 수 있다는 장점을 가지고 있다. 이러한 강점 덕분에 컴퓨터 비전 분야에도 빠