
8.1 성능 최적화
데이터를 사용한 성능 최적화
- 최대한 많은 데이터 수집: 데이터의 양이 많을수록 성능이 좋음
- 데이터 생성
- 데이터 범위 조정
- 시그모이드 활성화 함수: 0~1의 값을 갖도록 조정
- 하이퍼볼릭 탄젠트 활성화 함수: -1~1의 값을 갖도록 조정
- 정규화, 규제화, 표준화
알고리즘을 이용한 성능 최적화
유사한 용도의 알고리즘들을 선택하여 모델을 훈련시켜보고 최적의 성능을 보이는 알고리즘 선택
ex. SVM, KNN
ex. RNN, LSTM, GRU
알고리즘 튜닝을 위한 성능 최적화
하이퍼파라미터
- 진단: 모델에 대한 평가 결과를 바탕으로 과적합 또는 다른 원인에 대한 인사이트 얻음
- 훈련 성능이 검증 성늠보다 눈에 띄게 좋다면 과적합 -> 규제화로 해결
- 훈련과 검증 결과의 성능이 모두 좋지 않으면 과소적합 의심 -> 네트워크 구조 변경, 에포크 수 조정
- 훈련 성능이 검증을 넘어서는 변곡점이 존재 -> 조기 종료 고려
- 가중치: 초깃값으로 작은 난수 사용. 작은 난수 값이 애매하면 오토인코더 같은 비지도 학습을 이용하여 사전 훈련 후 지도 학습 진행
- 학습률: 임의의 난수를 선택하여 학습 결과를 보고 변경
- 네트워크의 계층이 많으면, 학습률이 높아야 함
- 활성화 함수: 데이터 유형과 데이터로 얻을 결과에 대한 이해를 바탕으로 선택
- 활성화 함수 변경은 손실 함수 변경과 같이 이루어지는 경우가 대부분
- 활성화 함수: 시그모이드, 하이퍼볼릭 탄젠트 -> 출력층: 소프트맥스, 시그모이드
- 배치와 에포크: 일반적으로 큰 에포크와 작은 배치 사용
- 적절한 배치 크기를 위해 훈련 데이터셋의 크기와 동일하거나 하나의 배치로 훈련 시켜봄
- 옵티마이저 및 손실함수: 옵티마이저로 확률적 경사하강법 많이 사용, Adam, RMSProp 등도 좋은 성능
- 네트워크 구성: 네트워크 토폴로지
- 하나의 은닉층에 뉴런 여러 개 포함(네트워크 넓음)
- 네트워크 계층을 늘리되 뉴런 개수는 줄임(네트워크가 깊음)
- 위 방법 결합
앙상블을 이용한 성능 최적화
: 두 개 이상의 모델을 섞어서 사용
8.2 하드웨어를 이용한 성능 최적화
CPU
: 명령어가 입력되는 순서대로 데이터를 처리하는 직렬 처리 방식(한 번에 하나의 명령어만 처리하기 때문에 ALU가 많을 필요가 없음)
- ALU: 연산 담당
- 컨트롤: 명령어 해석, 실행
- 캐시: 데이터 담아둠
GPU
: 서로 다른 명령어를 동시에 병렬적으로 처리
- 캐시 메모리 비중 낮음
- ALU 개수 많음 -> 병렬 처리 방식에 특화
- 하나의 코어에 ALU가 수백~수천 개 -> 3D 그래픽 작업 등을 빠르게 처리
CPU, GPU 비교
- 개별 코어 속도는 CPU가 훨씬 빠름
- 파이썬이나 매트랩처럼 행렬 연산을 많이 사용하는 재귀 연산 -> 직렬 연산 -> CPU
- 역전파처럼 복잡한 미적분 -> 병렬 연산 -> GPU
- 복잡한 연산이 수반되는 딥러닝에서 속도와 성능을 높여주는 주요 요인
8.3 하이퍼파라미터를 이용한 성능 최적화
정규화
: 데이터 범위를 사용자가 원하는 범위로 제한
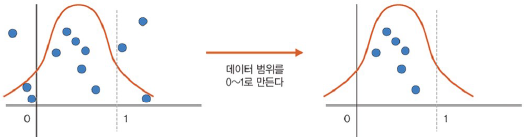
- 특성 스케일링: 각 특성 범위를 조절함
- MinMaxScaler()

규제화
: 모델 복잡도를 줄이기 위해 제약을 두는 방법
- 제약: 필터 적용
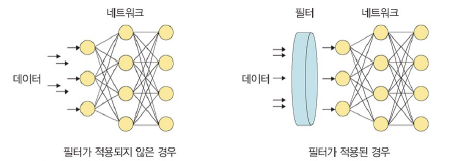
- 필터 적용을 통해 걸러진 데이터만 네트워크에 투입되어 빠르고 정확한 결과 얻음
- 드롭아웃, 조기 종료
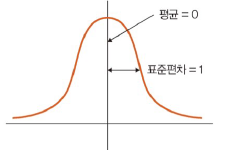
표준화
: 평균 0, 표준편차 1인 형태의 데이터로 만드는 방법
- 스칼라, z-스코어 정규화
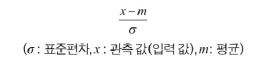
배치 정규화
: 기울기 소멸이나 기울기 폭발 등의 문제를 해결하기 위한 방법
기울기 소멸과 기울기 폭발
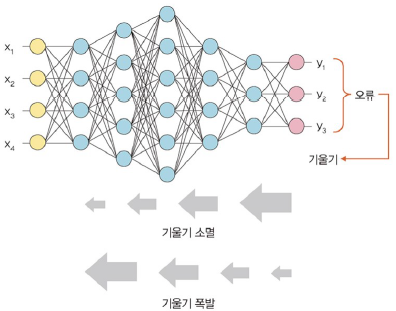
- 기울기 소멸: 오차 정보를 역전파시키는 과정에서 기울기가 급격히 0에 가까워져 학습이 되지 않는 현상
- 기울기 폭발: 학습 과정에서 기울기가 급격히 커지는 현상
- 원인: 내부 공변량 변화
- 네트워크의 각 층마다 활성화 함수가 적용되면서 입력 값들의 분포가 계속 바뀌는 현상
-> 배치 정규화를 통해 분산된 분포를 정규 분포로 만들기 위해 표준화와 유사한 방식을 미니 배치에 적용
- 네트워크의 각 층마다 활성화 함수가 적용되면서 입력 값들의 분포가 계속 바뀌는 현상
배치 정규화를 이용한 성능 최적화
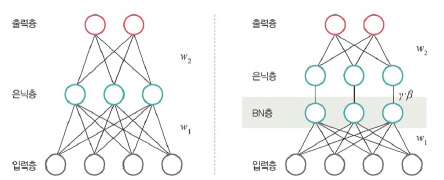
- 데이터 분포가 안정되어 학습 속도 증가
- 손실함수로 렐루 사용, 초깃값 튜닝, 학습률 조정
- 배치 정규화 식

- ① 미니 배치 평균
- ② 미니 배치 분산과 표준편차
- ③ 정규화 수행
- ④ 스케일 조정(데이터 분포 조정)
- 매 단계마다 활성화 함수를 거치면서 데이터셋 분포가 일정해져 속도 향상
- 단점
- 배치 크기가 작으면 정규화 값이 기존 값과 다른 방향으로 훈련될 수 잇음
ex. 분산이 0인 경우, 정규화 자체가 안 됨 - RNN은 네트워크 계층별로 미니 정규화를 적용 -> 모델 복잡, 비효율적
- 배치 크기가 작으면 정규화 값이 기존 값과 다른 방향으로 훈련될 수 잇음
- But, 적용했을 때의 성능이 좋아지기 때문에 많이 사용 됨
구현
# 배치 정규화가 적용되지 않은 모델 생성
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, BatchNormalization
# 입력층 (4,0) 형태, 유닛 64개
# 밀집층 유닛 128개, 64개 각 2개씩, 렐루 활성화함수
# 출력층 유닛 3개, 소프트맥스 활성화함수
model1 = Sequential([
Dense(64, input_shape=(4,), activation="relu"),
Dense(128, activation='relu'),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(3, activation='softmax')
]);
model1.summary()
model1.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
history1 = model1.fit(
X_train,
y_train,
epochs=1000,
validation_split=0.25,
batch_size=40,
verbose=2
)
# 손실과 정확도 평가
loss_and_metrics = model1.evaluate(X_test, y_test)
print('## 손실과 정확도 평가 ##')
print(loss_and_metrics) # [0.5316773653030396, 0.9333333373069763]
# 정확도 시각화
%matplotlib inline
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(history1.history['loss'], 'y', label='train loss')
loss_ax.plot(history1.history['val_loss'], 'r', label='val loss')
acc_ax.plot(history1.history['accuracy'], 'b', label='train acc')
acc_ax.plot(history1.history['val_accuracy'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuray')
loss_ax.legend(loc='lower right')
acc_ax.legend(loc='upper right')
plt.show()
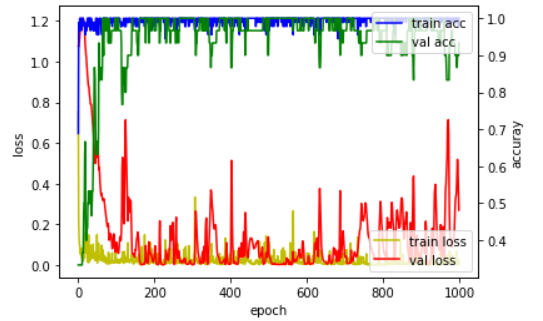
validation loss는 시간이 흐를수록 감소해야하지만 증가함. 훈련 정확도가 100%에 가깝고 훈련 손실값이 0에 가까움.
-> 훈련 데이터에 대한 정확도는 높지만, 검증 데이터에 대한 정확도는 낮음(과적합)
-> 배치 정규화를 적용하여 해결(신경망의 층이 깊어질수록 학습할 때 가정했던 입력 분포가 변화하여 엉뚱한 학습이 진행되는 것을 입력 분포를 고르게 맞추어 해결)
# 배치 정규화가 적용된 모델 생성
from tensorflow.keras.initializers import RandomNormal, Constant
model2 = Sequential([
Dense(64, input_shape=(4,), activation="relu"),
BatchNormalization(),
Dense(128, activation='relu'),
BatchNormalization(),
Dense(128, activation='relu'),
BatchNormalization(),
Dense(64, activation='relu'),
BatchNormalization(),
Dense(64, activation='relu'),
BatchNormalization(
momentum=0.95,
epsilon=0.005,
beta_initializer=RandomNormal(mean=0.0, stddev=0.05),
gamma_initializer=Constant(value=0.9)
),
Dense(3, activation='softmax')
]);
model2.summary()
model2.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
history2 = model2.fit(
X_train,
y_train,
epochs=1000,
validation_split=0.25,
batch_size=40,
verbose=2
)
# 손실과 정확도 평가
loss_and_metrics = model2.evaluate(X_test, y_test)
print('## 손실과 정확도 평가 ##')
print(loss_and_metrics) # [0.07776810228824615, 0.9666666388511658]BatchNormalization
- momentum: 미니 배치마다 평균과 표준편차를 구해서 전체 훈련 데이터셋의 평균과 표준편차로 대체
- 이동 평균법(지수 감소 이용)을 사용하여 구함
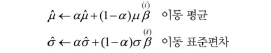
- 일반저그로 1에 가깝게 설정
- 이동 평균법(지수 감소 이용)을 사용하여 구함
- epsilon: 분산이 0으로 계산되는 것을 방지하기 위해 분산에 추가되는 작은 실수
- beta_initializer: 베타 가중치 초기값
- gamma_initializer: 감마 가중치 초기값
드롭아웃을 이용한 성능 최적화
드롭아웃
: 훈련할 때 일정 비율의 뉴런만 사용, 나머지 뉴런에 해당하는 가중치는 업데이트하지 않음
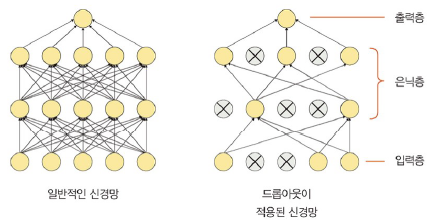
- 신경망 형태
- 비활성화 노드는 학습할 때마다 무작위로 선정
- 검증 데이터로 평가 시에는 노드를 모두 사용하여 출력, 노드 삭제 비율(드롭아웃 비율)을 곱해서 성능 평가
- 훈련 시간이 길어지지만, 모델 성능 향상
구현
#드롭아웃이 적용되지 않은 모델을 생성
encoder = info.features['text'].encoder
model = tf.keras.Sequential([
tf.keras.layers.Embedding(encoder.vocab_size, 64),
tf.keras.layers.LSTM(64),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
#성능 향상을 위해 LSTM 대신 Bidirectional RNN로 바꾸고 드롭아웃을 적용
model = tf.keras.Sequential([
tf.keras.layers.Embedding(encoder.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(1e-4),metrics=['accuracy'])
history = model.fit(train_batches, epochs=5, validation_data=test_batches, validation_steps=30)- 주의할 점: 학습을 할 때만 드롭아웃 사용, 정확도 측정 시에는 모든 노드 사용
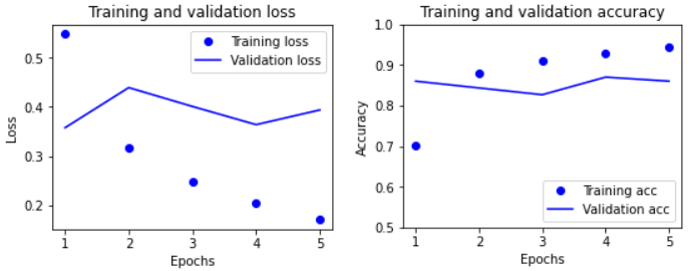
- 검증에 대한 손실이 증가하지만 이전에 비해 좋아
- 정확도 증가
#드롭아웃은 제거하고, Bidirectional RNN만 적용했을 때
model = tf.keras.Sequential([
tf.keras.layers.Embedding(encoder.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(1e-4),metrics=['accuracy'])
history = model.fit(train_batches, epochs=5, validation_data=test_batches, validation_steps=30)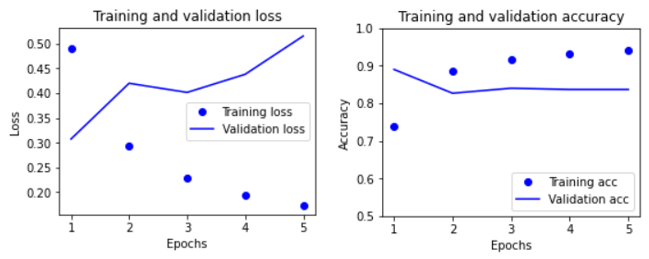
- 검증에 대한 손실이 높아짐
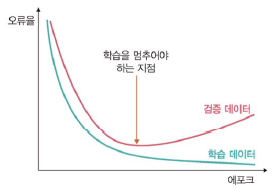
조기 종료를 이용한 성능 최적화
조기 종료
뉴럴 네트워크가 과적합을 회피하는 규제 기법
- 훈련 데이터와 별도로 검증 데이터를 준비하고 매 에포크마다 검증 데이터에 대한 손실을 측정하여 모델의 종료 시점 제어
- 검증에 대한 손실이 증가하는 시점에서 훈련 조기 종료
# 조기종료를 적용하지 않은 모델
model = Sequential()
model.add(Embedding(max_features,
embedding_dims,
input_length=maxlen))
model.add(Dropout(0.2))
model.add(Conv1D(filters,
kernel_size,
padding='valid',
activation='relu',
strides=1))
model.add(GlobalMaxPooling1D())
model.add(Dense(hidden_dims))
model.add(Dropout(0.2))
model.add(Activation('relu'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()- Embedding()
- max_features: 단어 종류 개수(단어 사전의 크기)
- embedding_dims: 단어 인코딩 후 벡터 크기
- input_length: 문장의 길이. 임베딩층 다음에 플래튼(flatten) 층이 오면 반디스 지정해줘야 1차원으로 만들어서 밀집층에 전달할 수 있음
- Conv1D(합성곱층)
- 위치를 무시하고 지역적인 특성
- 전후 문맥 고려하여 특성 추출
- GlobalMaxPooling1D()
- 합성곱층이 문장을 훑어 가면서 뽑아낸 특성 벡터 중 가장 큰 벡터 선택
- 문맥을 보면서 추출된 주요 특성 중 가장 두드러지는 특성 선택
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
callbacks=[cp_callback])
from tensorflow.keras.models import load_model
model = load_model(checkpoint_path)
scores = model.evaluate(x_test, y_test, verbose=1)
print(f'Score: {model.metrics_names[0]} of {scores[0]}; {model.metrics_names[1]} of {scores[1]*100}%')
# Score: loss of 1.9403566122055054; accuracy of 87.11199760437012%#조기 종료를 적용한 모델
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
keras_callbacks = [
EarlyStopping(monitor='val_loss', patience=30, mode='min', min_delta=0.0001),
ModelCheckpoint(checkpoint_path, monitor='val_loss', save_best_only=True, mode='min')
]
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
callbacks=keras_callbacks)
# Score: loss of 1.5000197887420654; accuracy of 86.9599997997284%- EarlyStopping()
- monitor: 관찰하고자 하는 항목. 주로 'val_loss', 'val_acc'
- patience: 개선이 없다고 바로 종료하지 않고 얼마나 기다려줄지 결정. 5이면 개선이 없는 에포크가 5번째 지속될 경우 학습 종료
- mode: 개선이 없다고 판단하기 위한 기준. ex. 관찰항목이 'val_loss'이면 'min'으로 설정
- min_delta: 개선되고 있다고 판단하기 위한 최소 변화량. 이보다 적으면 개선이 없다고 판단
- 조기 종료는 성능 최적화를 보장 x, 단지 훈련 종료 시점 알 수 있도록 도와줌
- 하지만, 학습 횟수가 크면 어느 정도 성능이 향상될 수 있음

Data Analyst | Statistics