
7.5 LSTM
RNN의 단점
: 가중치가 업데이트되는 과정에서 1보다 작은 값이 곱해져서 기울기가 사라지는 기울기 소멸 문제 발생
-> 해결을 위해 LSTM, GRU 같은 확장된 RNN 방식 사용
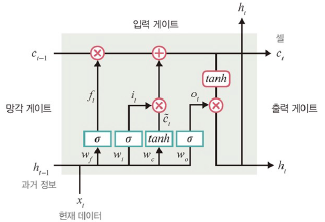
LSTM 구조
LSTM 순전파
: 기울기 소멸 문제 해결을 위해 망각 게이트, 입력 게이트, 출력 게이트를 은닉층의 각 뉴런에 추가
망각 게이트
: 과거 정보를 어느 정도 기억할지 결정
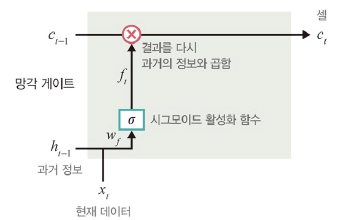
- 과거 정보와 현재 데이터를 입력받아 시그모이드 취함
- 시그모이드 출력이 1이면 보존, 0이면 과거 정보 폐기
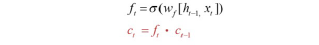
입력 게이트
: 현재 정보를 기억하기 위함. 새로운 정보를 반영할지 결정.
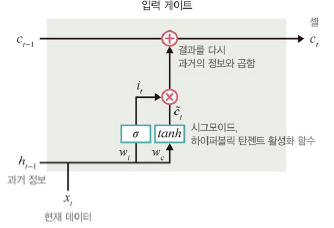
- 과거 정보와 현재 데이터를 입력받아 시그모이드, 하이퍼볼릭 탄젠트 함수 취함
- 출력이 1이면 새로운 입력 허용, 0이면 차단
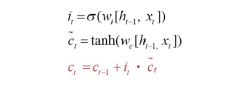
셀
- 메모리 셀: 각 단계에 대한 은닉 노드
- 총합을 사용하여 셀 값 반영
- 기울기 소멸 문제 해결
- 업데이트 방식
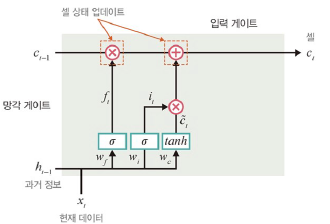
- 망각 게이트와 입력 게이트의 이전 단계 셀 정보를 계산하여 현재 단계 셀 상태 업데이트
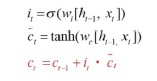
- 망각 게이트와 입력 게이트의 이전 단계 셀 정보를 계산하여 현재 단계 셀 상태 업데이트
출력 게이트
: 과거 정보와 현재 데이터를 사용하여 뉴런의 출력 결정
- 이전 은닉 상태와 t번째 입력을 고려하여 다음 은닉 상태 계산
- 이 은닉 상태가 그 시점에서의 출력
- 계산 값이 1이면 의미있는 결과로 최종 출력, 0이면 출력x
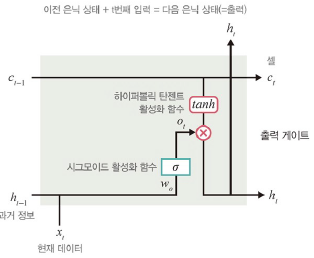
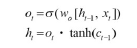
전체 과정
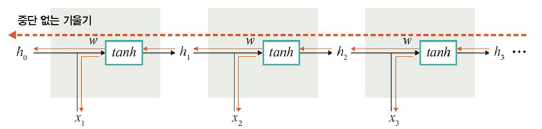
LSTM 역전파
: 셀을 통해서 역전파 수행. 중단없는 기울기
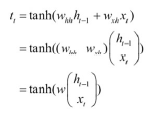
- 입력 방향으로도 오차가 전파(셀 내부적으로는 오차가 입력(xt)으로 전파)
LSTM 셀 구현
########## 네트워크 생성
class LSTM_Build(tf.keras.Model):
def __init__(self, units):
super(LSTM_Build, self).__init__()
self.state0 = [tf.zeros([batch_size, units]), tf.zeros([batch_size, units])]
self.state1 = [tf.zeros([batch_size, units]), tf.zeros([batch_size, units])]
self.embedding = tf.keras.layers.Embedding(total_words, embedding_len, input_length=max_review_len)
self.RNNCell0 = tf.keras.layers.LSTMCell(units, dropout=0.5) # units: 메모리 셀 개수, dropout: 전체 가중치 중 50% 값을 0으로 설정하여 사용x
self.RNNCell1 = tf.keras.layers.LSTMCell(units, dropout=0.5)
self.outlayer = tf.keras.layers.Dense(1)
def call(self, inputs, training=None):
x = inputs
x = self.embedding(x)
state0 = self.state0
state1 = self.state1
for word in tf.unstack(x, axis=1):
out0, state0 = self.RNNCell0(word, state0, training)
# train 매개변수 추가
out1, state1 = self.RNNCell1(out0, state1, training)
x = self.outlayer(out1)
prob = tf.sigmoid(x)
return prob
########## 모델 훈련
import time
units = 64
epochs = 4
t0 = time.time()
model = LSTM_Build(units)
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.losses.BinaryCrossentropy(),
metrics=['accuracy'],
experimental_run_tf_function=False)
model.fit(train_data, epochs=epochs, validation_data=test_data, validation_freq=2)
########## 모델 평가
print("훈련 데이터셋 평가...")
(loss, accuracy) = model.evaluate(train_data, verbose=0)
print("loss={:.4f}, accuracy: {:.4f}%".format(loss,accuracy * 100))
print("테스트 데이터셋 평가...")
(loss, accuracy) = model.evaluate(test_data, verbose=0)
print("loss={:.4f}, accuracy: {:.4f}%".format(loss,accuracy * 100))
t1 = time.time()
print('시간:', t1-t0)LSTM 계층 구현
class LSTM_Build(tf.keras.Model):
def __init__(self, units):
super(LSTM_Build, self).__init__()
self.embedding = tf.keras.layers.Embedding(total_words, embedding_len, input_length=max_review_len)
self.rnn = tf.keras.Sequential([
tf.keras.layers.LSTM(units, dropout=0.5, return_sequences=True, unroll=True),
tf.keras.layers.LSTM(units, dropout=0.5, unroll=True)
])
self.outlayer = tf.keras.layers.Dense(1)
def call(self, inputs, training=None):
x = inputs
x = self.embedding(x)
x = self.rnn(x)
x = self.outlayer(x)
prob = tf.sigmoid(x)
return prob
########## 이후 과정 동일LSTM(units, dropout return_sequences, unroll)
- units: 네트워크의 층 수(출력 공간의 차원)
- dropout: 전체 가중치 중 50%를 0으로 설정하여 사용x
- return_sequences: False면 마지막 출력 반환, True면 전체 순서 반환
- unroll: 시간 순서에 따라 입력층과 은닉층에 대한 네트워크를 펼치겠다는 의미
LSTMCell과 LSTM
# LSTMCell: 셀 단위로 수행되므로 다수 셀을 수행하려면 for문으로 반복적 수행 필요
for word in tf.unstack(x, axis=1):
out0, state0 = self.RNNCell0(word, state0, training)
out1, state1 = self.RNNCell1(out0, state1, training)
# LSTM
x = self.rnn(x)7.6 GRU(게이트 순환 신경망)
: 게이트 메커니즘이 적용된 RNN 프레임워크의 한 종류
- LSTM의 게이트를 사용한다는 개념은 유지, 매개 변수를 줄여 계산 시간 감소시킴
- LSTM보다 구조가 간단
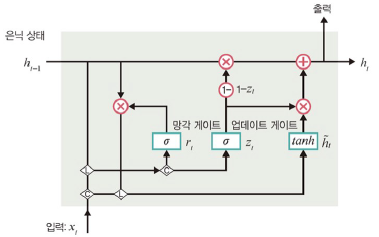
GRU 구조
- 망각 게이트 + 입력 게이트, 별도의 업데이트 게이트
- 하나의 게이트 컨트롤러가 망각 게이트와 입력 게이트 모두 제어
- 1 출력: 망각 열리고(보존) 입력 닫힘
- 0 출력: 망각 닫히고(삭제) 입력 열림
- 이전 기억이 저장될 때마다 단계별 입력은 삭제
망각 게이트
: 과거 정보를 적당히 초기화시키는 목적
- 시그모이드 함수를 출력으로 사용
- 0, 1 값을 이전 은닉층에 곱
- 이전 시점의 은닉층 값에 현시점의 정보에 대한 가중치를 곱한 것
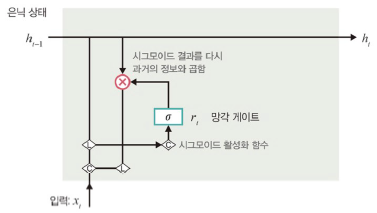
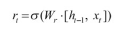
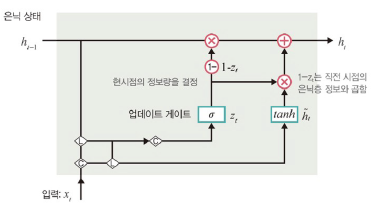
업데이트 게이트
: 과거와 현재 정보의 최신화 비율 결정
- 시그모이드로 출력된 결과(zt): 현시점의 정보량 결정
- 1-zt과 직전 시점의 은닉층 정보와 곱
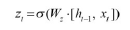
후보군
: 현시점의 정보에 대한 후보군 계산
- 망각 게이트의 결과를 이용
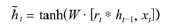
은닉층 계산
: 업데이트 게이트 결과와 후보군 결과 결합하여 현시점의 은닉층 계산
- 시그모이드로 출력된 결과(zt): 현시점의 정보량 결정
- 1-zt: 과거의 정보량
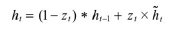
전체 구조
GRU 셀 구현
########## 네트워크 생성
class GRU_Build(tf.keras.Model):
def __init__(self, units):
super(GRU_Build, self).__init__()
self.state0 = [tf.zeros([batch_size, units])]
self.state1 = [tf.zeros([batch_size, units])]
self.embedding = tf.keras.layers.Embedding(total_words, embedding_len, input_length=max_review_len)
self.RNNCell0 = tf.keras.layers.GRUCell(units, dropout=0.5)
self.RNNCell1 = tf.keras.layers.GRUCell(units, dropout=0.5)
self.outlayer = tf.keras.layers.Dense(1)
def call(self, inputs, training=None):
x = inputs
x = self.embedding(x)
state0 = self.state0
state1 = self.state1
for word in tf.unstack(x, axis=1):
out0, state0 = self.RNNCell0(word, state0, training)
out1, state1 = self.RNNCell1(out0, state1, training)
x = self.outlayer(out1)
prob = tf.sigmoid(x)
return prob
########## 이후 과정 동일 GRU 계층 구현
########## 네트워크 생성
class GRU_Build(tf.keras.Model):
def __init__(self, units):
super(GRU_Build, self).__init__()
self.embedding = tf.keras.layers.Embedding(total_words, embedding_len, input_length=max_review_len)
self.rnn = tf.keras.Sequential([
tf.keras.layers.GRU(units, dropout=0.5, return_sequences=True, unroll=True),
tf.keras.layers.GRU(units, dropout=0.5, unroll=True)
])
self.outlayer = tf.keras.layers.Dense(1)
def call(self, inputs, training=None):
x = inputs
x = self.embedding(x)
x = self.rnn(x)
x = self.outlayer(x)
prob = tf.sigmoid(x)
return prob
########## 이후 과정 동일7.7 성능 비교
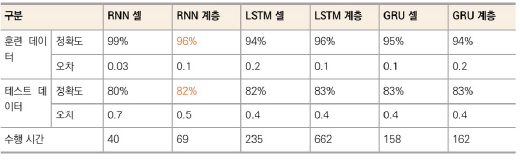
- 전체적으로 RNN 계층의 성능이 가장 좋음
- 수행 시간이 중요하지 않으면 GRU 선택
- 정확도 차이가 크지 않아 모든 모델을 실행하여 하이퍼 파라미터 값을 제일 빨리 찾는 모델 사용 권장
7.8 양방향 RNN
: 이전 시점의 데이터 뿐만 아니라, 이후 시점의 데이터도 함께 활용하여 출력 값을 예측
양방향 RNN 구조
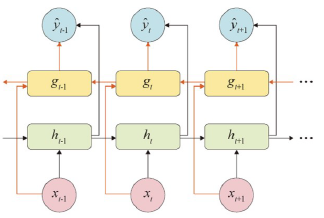
- 2개의 메모리 셀
- 첫 번째: 이전 시점의 은닉 상태를 전달 받아 현재의 은닉 상태 계산(초록)
- 두 번째: 다음 시점의 은닉 상태를 전달 받아 현재의 은닉 상태를 계산(노랑)
- 2개의 메모리 셀 모두 출력층에서 출력 값을 예측하는 데 사용
양방향 RNN 구현
########## 모델 생성
import numpy as np
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Embedding, LSTM, Bidirectional
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import imdb
n_unique_words = 10000
maxlen = 200
batch_size = 128
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=n_unique_words)
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
y_train = np.array(y_train)
y_test = np.array(y_test)
model = Sequential()
model.add(Embedding(n_unique_words, 128, input_length=maxlen))
model.add(Bidirectional(LSTM(64))) # LSTM에 양방향 RNN 적용
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
########## 모델 훈련
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=4,
validation_data=[x_test, y_test])
model.summary()
########## 모델 평가
loss, acc = model.evaluate(x_train, y_train, batch_size=384, verbose=1)
print ('Training accuracy', model.metrics_names, acc)
print ('Training accuracy', model.metrics_names, loss)
loss, acc = model.evaluate(x_test, y_test, batch_size=384, verbose=1)
print ('Testing accuracy', model.metrics_names, acc)
print ('Testing accuracy', model.metrics_names, loss)
# train 정확도: 97%, test 정확도: 86%
Data Analyst | Statistics