[2022 PMLR] Domain Adaptation for Time Series Forecasting via Attention Sharing (8회 인용)
Paper review
😎 Abstract
- 시계열 예측 모델의 효과는 충분한 양의 데이터가 있는 경우에만 나타남.
- 따라서 데이터 부족 문제에 대처하기 위해 새로운 Domain Adaptation 프레임워크인 DAF(Domain Adaptation Forecast)를 제안함.
- DAF는 풍부한 데이터 샘플(Source)이 있는 관련 도메인의 통계적 강점을 활용하여 제한된 데이터(Target)로 관심 영역의 성능을 향상시킴.
- Attention기반 공유 모듈과 개별 도메인에 대한 개인 모듈 사용함.
- Source domain과 Target domain에 대한 Predictor의 공동 훈련을 가능하게 하기 위해 도메인 불변 잠재 기능 (Query&Key)과 도메인별 기능(Value)을 동시에 재교육함.
1. Introduction
- 도메인 적응(DA) 방법은 소스 도메인과 대상 도메인 간에 추출된 기능을 정렬하여 도메인 이동의 유해한 영향을 완화하려고 함.
[2가지 Challenges]
- 시계열의 시간적 특성으로 인해 시계열 내에서 진화하는 패턴은 전체 흐름 표현에 의해 포착되지 않을 것임.
- 미래의 예측은 서로 다른 기간 내의 로컬 패턴에 따라 달라질 수 있으며, 일련의 로컬 표현은 대부분의 기존 접근 방식에서 수행한 것처럼 전체 흐름을 사용하는 것보다 더 적절할 수 있음.
- 예측 작업의 출력 공간은 일반적으로 도메인에 따라 고정되지 않는데, 이는 예를 들어, 전기 소스 데이터의 kW 대 스톡 대상 데이터의 단위 수와 같은 도메인 종속적인 시계열을 생성하기 때문임.
- 각 도메인의 데이터 분포가 적절하게 근사되도록 도메인 종속 속성을 모델링하기 위해 도메인 불변 및 도메인별 특성을 추출하고 예측에 통합해야 함.
-> 즉, 서로 다른 도메인에서 공유하거나 공유하지 않을 기능 유형을 신중하게 설계하고 시계열 예측 모델에 적합한 아키텍처를 선택해야 함.
[Attention 활용 이유]
-
진화하는 패턴의 경우, Attention은 시간 의존 쿼리 키 정렬에 의해 가중치가 부여된 값의 조합을 기반으로 동적 예측을 할 수 있음.
-
Attention 정렬이 특정 패턴과 독립적이기 때문에 Q와 K는 도메인 불변으로 유도되는 반면, V은 모델이 도메인 의존적 예측을 하기 위해 도메인별로 유지될 수 있음.
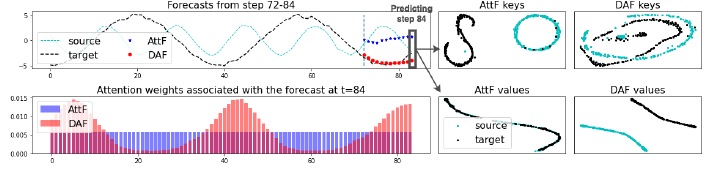
<Sine 신호가 있는 합성 데이터 세트에 대한 기존의 주의 기반 예측기(AtF)와 도메인 적응 전략(DAF)이 결합된 대응기 사이의 비교 예시>
-
AtF는 제한된 대상 데이터를 사용하여 훈련되지만, DAF는 두 도메인에서 공동으로 훈련됨.
-
오른쪽 상단 그림에서 보이듯이, 도메인 간에 키를 정렬함으로써, 소스 도메인에서 학습된 컨텍스트 일치는 DAF가 왼쪽 하단 그림의 AtF에 의해 생성된 균일한 가중치보다 이전 대상 데이터 기간의 동일한 단계에 초점을 맞춘 보다 합리적인 주의 가중치를 생성하는 데 도움이 됨.
-
오른쪽 아래 그림은 단일 도메인 AtF가 입력이 매우 중첩되어 두 도메인에 대해 동일한 값을 생성하는 반면 DAF는 각 도메인에 대해 고유한 값을 생성할 수 있음을 보여줌.
-> 결과적으로 왼쪽 상단 그림은 DAF가 AtF보다 더 정확한 도메인별 예측을 생성한다는 것을 보여줌.
-
[제안하는 방법]
1. Shared Attention Module을 통해 Source/Target에 대한 multi-horizon 예측을 하기 위해 domain-invariant/specific 기능을 적절하게 사용.
2. Cold-Start 및 Few-Shot 예측 문제를 해결하는 광범위한 합성 및 실제 실험을 통해 DAF가 데이터 부족 대상 도메인에서 높은 성능을 보임.
3. Discriminator에 의해 유도된 domain-invariant 기능과 DAF 모델에서 재교육된 domain-specific 기능의 중요성을 보여줌.
3. Domain Adaptation in Forecasting
Time Series Forecasting
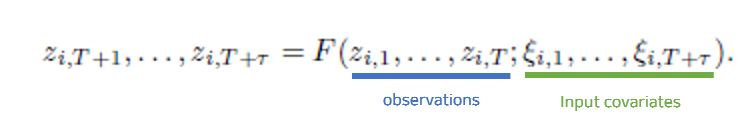
Adversarial Domain Adaptation in Forecasting
: 원하는 target prediction을 계산하기 위해, min-max problem 사용
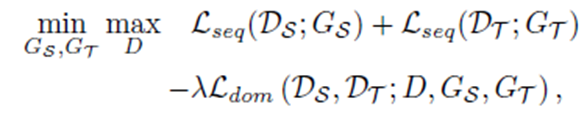
[생성자 G를 통해 판별자 D의 estimation error]
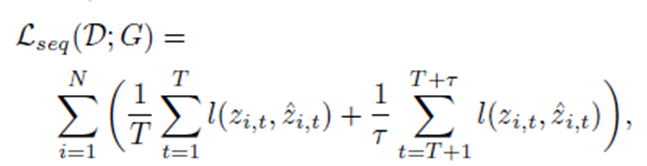
[Domain Classification Error]
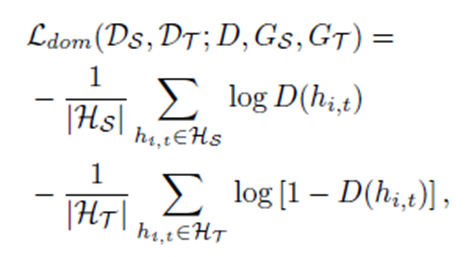
4. The Domain Adaptation Forecaster (DAF)
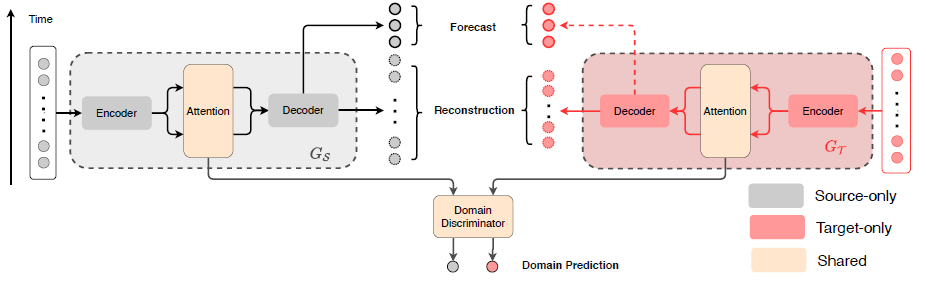
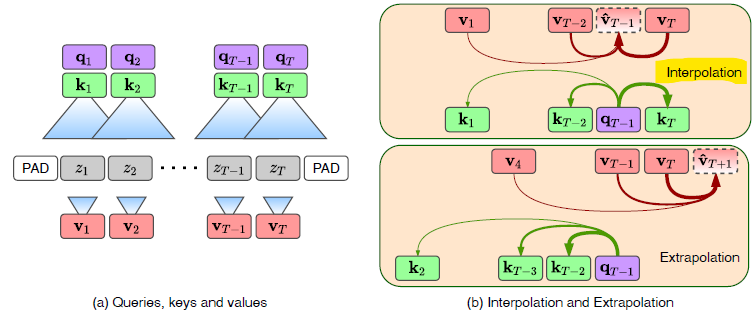
4_1. Sequence Generators
Private Encoders
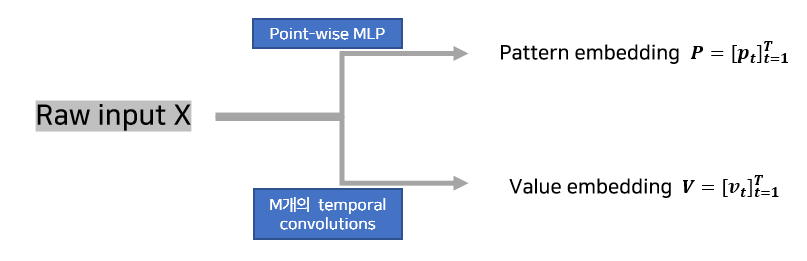
Shared Attention Module

1. MLP가 두 도메인 중 하나의 Pattern 및 value 임베딩을 처리함.
2. kernel function이 pattern embedding을 shared latent space로 인코딩함.
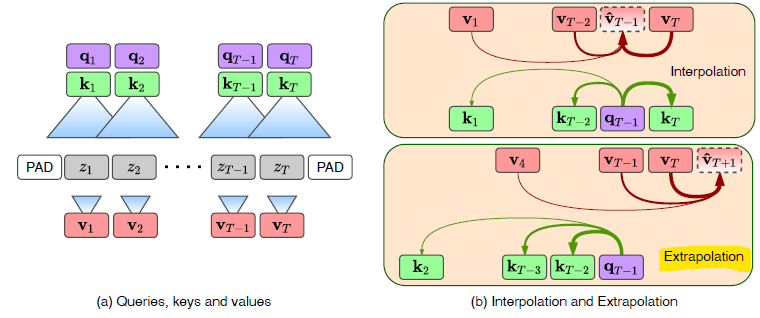
3. reconstruction을 위해 interpolation 사용하고, forecast를 위해 extrapolation 사용함.

Interpolation: Input Reconstruction
- 을 사용해 을 추정함.
Extrapolation: Future Predictions
- 을 사용해 을 추정함.
Private Decoders
- Position-wise MLP: 를 활용
- 이를 통해 reconstruction 값과 one-step prediction 값을 내놓음.
- Prediction 값은 다시 다음 step을 예측하기 위해 encoder와 attention model로 들어감.
4.2. Domain Discriminator
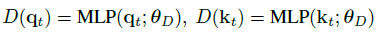
- 모든 과정은 source와 target domain 각각에서 계산됨.
4.3. Adversarial Training
"Generator G"
- Source domain의 generator와 Target domain의 generator는 private encoder/decoder와 shared attention module로 구성됨.
"Discriminator D"
- domain에 걸쳐 latent features keys K와 queries Q의 invariance를 유도하는 역할
"Adversarial Training"
- D는 source와 target 사이의 domain을 분류하기 위해 힘쓰지만, 와 는 D를 혼란시키기 위해 힘씀.
5. Experiments
실험 #1
Single domain forecasts only on the target domain

Cross domain forecasts both source and target doamin

실험 #2
cold-start forecasting
: 신호가 상당히 짧고 미래 예측에 제한된 과거 정보를 사용할 수 있는 대상 도메인에서 예측하는 것을 목표로 함.
few-shot forecasting
: 잘 훈련된 예측자에 대해 대상 도메인에 시계열의 수가 부족할 때 발생함.
실험 결과
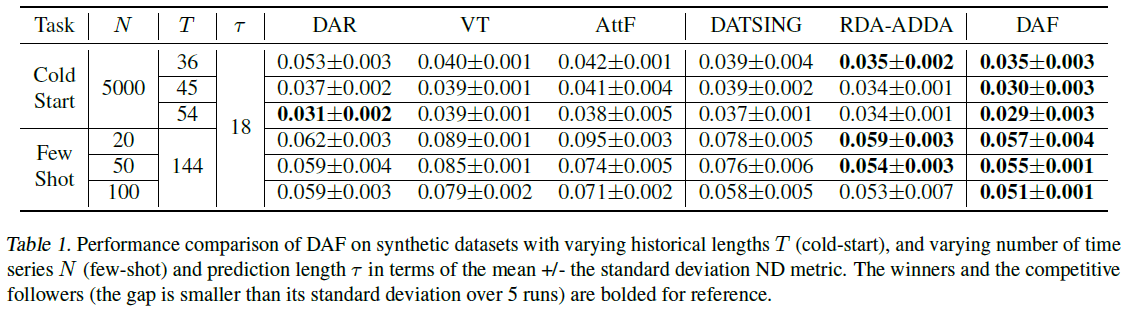
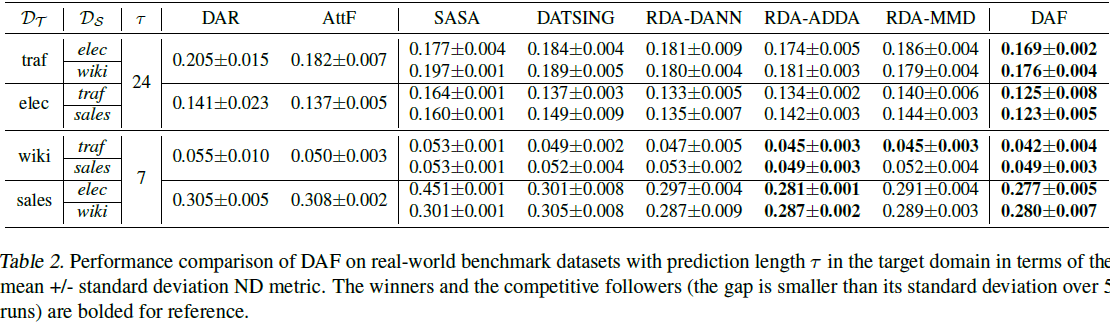
- Source 및 Target 데이터를 모두 사용하여 end-to-end로 공동으로 훈련된 교차 도메인 예측기 RDA 및 DAF가 단일 도메인 예측기보다 전반적으로 더 정확하다는 것을 알 수 있음.
- 교차 도메인 예측자 중 DATSING은 RDA와 DAF가 능가하여 두 도메인 모두에서 공동 훈련의 중요성을 보여줌.
- 대부분의 실험에서 우리의 주의 기반 DAF 모델은 RNN 기반 DA(RDA) 방법보다 정확하거나 경쟁력이 있음.
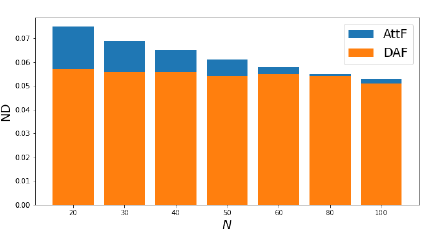
- 마지막으로, 아래 그림을 통해 훈련 샘플의 수가 줄어들수록 DAF가 더 크게 개선된다는 것을 알 수 있음.