[2022 CVPR] Selective-Supervised Contrastive Learning with Noisy Labels (52회 인용)
Paper review
Abstract
- 고품질의 라벨을 획득하는 것은 비용이 많이 듬
- 노이즈가 있는 라벨은 잘못된 표현을 학습할 수 있고, 일반화 성능이 하락함.
- 따라서 robust한 표현을 학습하고 노이즈가 있는 라벨을 다루기 위해서 Selective-Supervised Contrastive Learning을 제안함.
1. Introduction
- 딥러닝의 성능은 양질의 라벨을 가진 대규모의 데이터를 필요로 함
- 노이즈가 있는 라벨은 딥러닝의 일반화 성능을 하락시킴
- pair-wise로 접근하는 최근 연구들은 Contrastive Learning이 좋은 latent representation을 가져온다고 보여줌.
(특히 라벨을 사용하는 Supervised contrastive learning(Sup-CL)이 더 나은 repsentation을 학습함)
(단, 양질의 라벨일 경우)

[제안 방법]
(1) noisy pairs에서 confident pairs를 선별함
(2) robust latent representation을 학습하기 위해 confident pairs를 이용함
**representation learning에서 confident pairs를 식별하는 것은 어려움
-> confident examples를 사용하여 각 epoch마다 신뢰할 수 있는 집합을 구성함
-> confident pairs의 표현 유사성 분포를 기반으로 동적 임계값을 설정하여 모든 noisy pairs중에 더 confident한 쌍을 선택함
[Contribution]
(1) 노이즈 레이블을 사용한 선택적 지도 대조 학습 제안하는데, 이는 Sup-CL을 수행하기 위한 신뢰할 수 있는 쌍을 효과적으로 선택함으로써 강력한 사전 훈련 표현을 얻을 수 있음.
(2) 식별된 신뢰할 수 있는 샘플에 의해 구축된 쌍과 유사성이 높은 샘플에 의해 구축된 쌍을 선택함. 이는 신뢰할 수 있는 쌍이 더 나은 표현을 제공하고 더 나은 표현이 더 나은 신뢰할 수 있는 쌍을 식별할 수 있게 함.
(3) 합성 및 실제 노이즈가 많은 데이터 세트에 대한 실험을 수행하며, 이는 우리의 접근 방식이 최첨단 방법에 비해 더 나은 성능을 달성한다는 것을 입증함.
2. Related Works
2.1. Learning with Noisy Labels
- noise transition matrix
- reweighting examples
- selecting confident examples
- robust loss functions
- regularization
- pseudo labels
- DivideMix
- ELR+
2.2. Contrastive Learning
- Uns-CL
- Sup-CL
- MOIT+, MoPro
- ProtoMix, NGC
3. Selective Supervised Contrastive Learning
(1) A deep encoder f (a convolutional neural network backbone)
(2) A classifier head (a fully-connected layer followed by the softmax function)
(3) A linear or non-linear projection
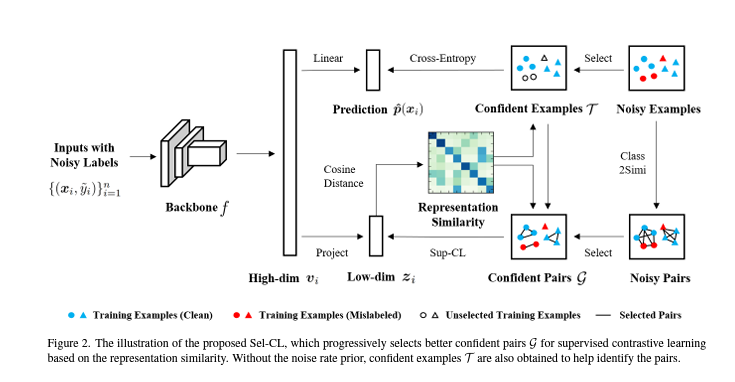
3.1.Selecting Confident Examples
-
표현 유사도는 코사인 유사도를 활용함.
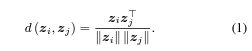
-
top-K neighbors의 original 라벨과 dominant class를 사용해 맞는 y_i를 계산함
-
이를 통해서 mislabeled 샘플의 탐지 성능을 향상시킴.
-
clean 클래스 사후 확률을 근사하기 위해 pseudo-labels을 사용함
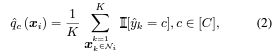
-
아래 수식은 c-th 클래스에 속하는 confident 샘플들의 집합을 의미함.
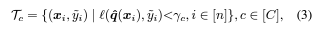
3.2. Selecting Confident Pairs
- 확인된 신뢰할 수 있는 예를 관련 신뢰할 수 있는 쌍으로 변환함.
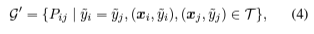
- 제안된 방법에서는, 한 쌍 안의 두 예제의 클래스 레이블이 잘못되었더라도, 예제들이 동일한 클래스로 잘못 분류되었을 때 유사성 레이블은 여전히 올바름.
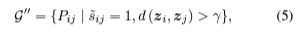
- 최종적인 confident pair는 다음과 같음.
3.3. Representation Learning with Selected Pairs
[Contrasive Loss]
- 선택된 confident positive pairs로 supervised 대조학습을 수행함
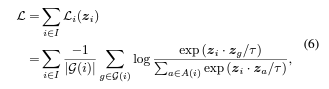
[MixUP]
- MOIT 모델에서 사용된 Mixup 기법 사용함
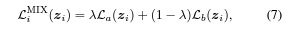
[Classification Learning]
-
수렴을 안정화하고 더 좋은 표현을 뽑을 수 있게 함.
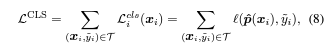
-
class-fier 예측을 사용해 유사성 레이블로부터 학습하는 것을 추가함.
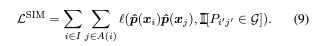
-
최종적인 목적 함수 식은 아래와 같음
: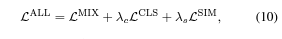
4. Experiments
4.1. Datasets and Implementation Details
- CIFAR-10/CIFAR-100
- Symmetric noise
: 일정 비율의 학습 데이터 라벨을 replace함 - Asymmetric noise
: 특정 레이블을 바꿈 ex) 트럭-> 오토바이
- Symmetric noise
- WebWision
- 노이즈가 라벨이 있는 데이터셋
- 웹에서 크롤링한 240만개의 이미지
- ILSVRC12
- 1000개의 클래스, 각 클래스당 1000개의 이미지
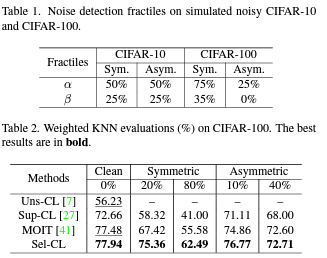
4.2. Representation Learning Evaluations
- noisy labels가 존재하는 상태에서, 서로 다른 대조학습 기법으로 비교한 실험
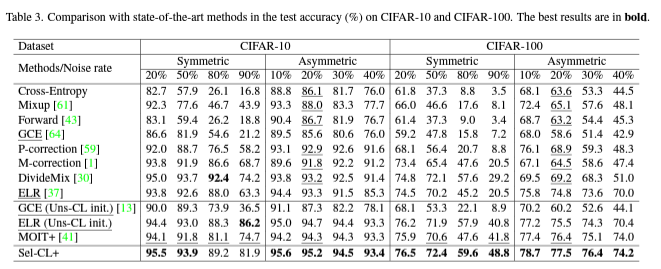
4.3. Results on Simulated Noisy Datasets
- Uns-CL에 의해 사전 훈련된 방법이 원래 방법인 GCEvs를 능가할 수 있다는 것을 보여줌.
- 특히, 노이즈 수준이 높은 경우(예: 80% 및 90%) 더 높은 성능 향상이 됨.
- 정규화를 추가하여 Sup-CL을 사용하는 MOIT+도 성능이 좋음.
- Symmetric 노이즈에 대해서는 MOIT+가 다른 최첨단 알고리즘(예: ELR 및 DivideMix)과 비교하여 더 좋은 성능을 보임.
- Asymmetric 노이즈의 경우, Sel-CL+는 대부분의 경우에서 더 나은 성능을 보임.
- Sel-CL+는 노이즈에 강건한 표현 학습을 달성하는 데 효과적인 방법임!
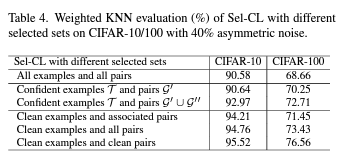
5. Limiatations
- 대조 학습을 활용하고 있으므로, 우리의 접근 방식의 성능이 적절한 데이터 증강과 많은 양의 부정적인 샘플에 의존함.
- 더 큰 배치 크기나 메모리 벵크가 필요하며 이는 컴퓨팅 장치의 더 높은 저장 공간을 요구함.
- KNN 알고리즘의 사용은 더 많은 계산 비용을 요구함.
6. Conclusion
- 본 논문은 노이즈가 있는 레이블을 처리하기 위해 신뢰할 수 있는 사전 훈련된 표현을 학습함으로써 Selective-Supervised Contrastive Learning(Sel-CL)이라는 새로운 방법을 제안함.
- 대조 학습의 쌍별 특성을 활용하여 네트워크의 견고성을 더욱 향상시킴.
- 노이즈 비율 사전 정보 없이, 우리는 노이즈가 있는 쌍에서 신뢰 있는 쌍을 선택하여 지도 대조 학습을 수행함.
