[2020 NeurlPS] Time series Anomaly Detection using Temporal Hierarchical One-Class Network
Paper review
목록 보기
16/21
THOC : Deep SVDD와 Dilated RNN을 기반으로 timeseries anomaly detection에서 SOTA 성능을 도출한 모델
- Dilated RNN을 기반으로 short/long term 정보를 포함한 multiscale temporal features를 추출함.
- 이후 differentiable hierarchical clustering을 통해 multiscale temporal features를 통합하고, 이를 기반으로 이상치를 탐지함.
- THOC 모델과 더불어 end-to-end로 학습할 수 있는 multiscale vector data description(MVDD)를 제안함.
[Motivation]
- 변수간의 복잡한 상관관계, 이상치의 수가 적음
- Fixed dimensional input data
ex) sliding window, LSTM(error accumulation 문제), GAN(D와 G의 균형 맞춰야 하는 문제)
[Proposed Method]
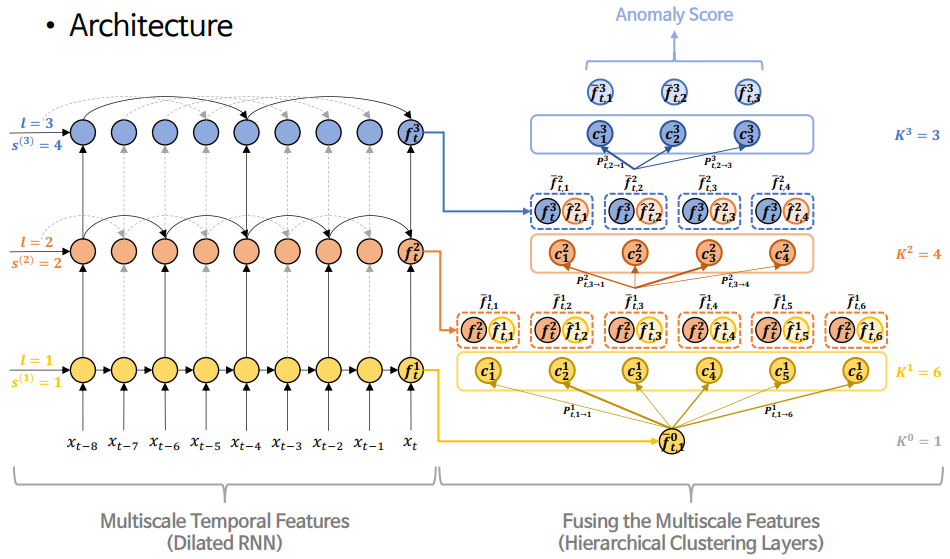
1. Multiscale Temporal Features
- dilated RNN을 사용하여 highest resolution에서부터 lowest resolution까지의 정보를 뽑아냄
- 즉, short-term dependency부터 long-term dependency까지 고려할 수 있음
2. Fusing Multiscale Features
-
각 층에서 추출한 multiscale temporal features를 통합하는 differentiable hierarchical clustering procedure를 제안함.
(각 layer의 클러스터 개수 = K^l)Step 1 (Assignment)
: 이전 layer의 feature와 현재 layer의 클러스터 중심들의 similarity를 계산한 후, 이를 기반으로 각 feature가 각 클러스터 중심에 할당될 확률을 구함.
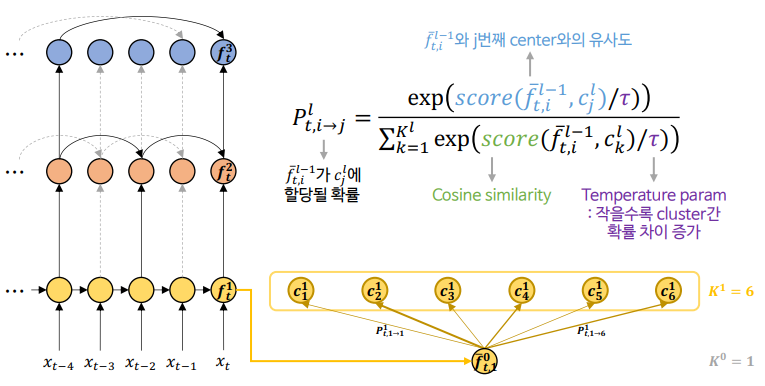
Step 2-1 (Update)
: 각 클러스터의 중심에 대해 위에서 구한 확률값을 기반으로, 이전 layer의 features를 통합 및 변환하여 updated feature을 도출함.

Step 2-2 (Update)
: 위에서 구한 updated feature와 dilated RNN의 다음 layer의 feature를 concatenate한 후, MLP를 통해 fused feature를 도출함.
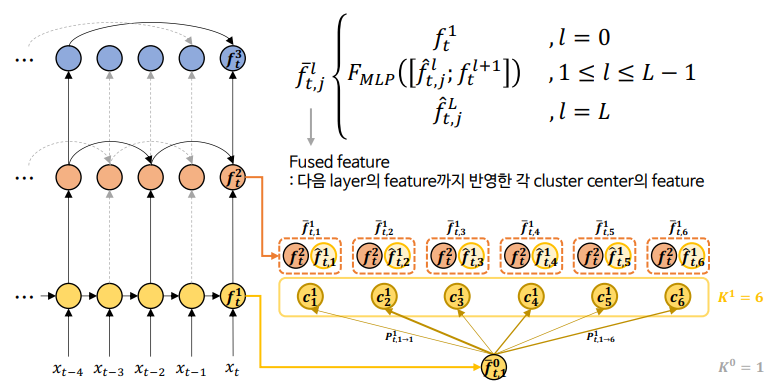
<최종적인 fused feature>

3. Multiscale Support Vector Data Description (MVDD)
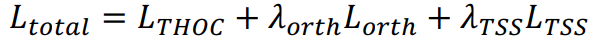
- Deep SVDD 관점에서 THOC 네트워크의 최종 feature 3개를 center와의 거리가 최소화되도록 모델을 학습해야 함.

- 거리 식에 가중치를 설정해서, 연관성 반영하고자 함.

-
L_orth는 각 중심을 orthogonal하게 만들어, cluster center의 다양성을 확보함.
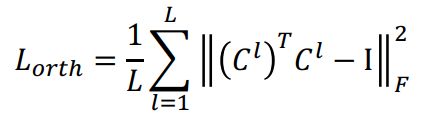
-
L_TSS는 multi-step-ahead prediction을 auxiliary task로 수행하는 temporal self-supervision을 통해 더 좋은 timeseries representation을 도출하도록 함. (= 예측 잘 했는지 본다는 말)
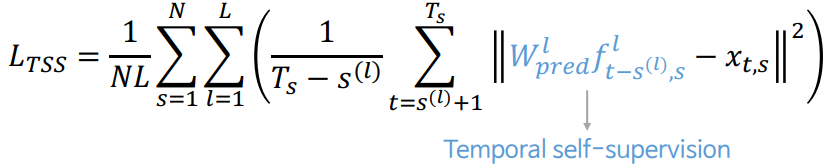
😀 "결론"
1. Cluster 활용
- Unsupervised Learning에서 One-Class Classification을 사용하는 것은 정상과 이상을 구분하며 학습할 수 있을 것임.
2. Dilated RNN 활용
- Window size로 잘라서 temporal 고려 없이 표현 추출하는 것보다 dilated RNN을 사용하는 게 시계열에 더 적합해 보임.
3. 3개의 loss 사용
- 제안 네트워크 관련 (특징 추출) + 다양성 관련 + 성능 관련 (예측)
- 각각의 Loss에 역할을 부여하고 Ablation Study로 필요성 검증
🤔 "생각해볼 것"
1. Fusing process
- Dilated RNN 구조 자체가 이전 layer의 정보를 다음 layer로 넘겨주는데 왜 매 layer마다 cluster 계산을 할까
-> 최종 layer에서만 해도 되지 않을까?
-> 근데 실험에서는 hierarchical 구조가 가장 성능이 좋음을 입증함. (특정 데이터 2D-gesture에서만 그런지 확인 필요)2. L_orth 사용
- 최종적인 클러스터를 3개 사용했다는 점과 각 중심의 다양성을 확보하려 한 점이 정상성이 여러개인 데이터를 타겟으로 했다고 판단됨.
-> 정상성이 하나라면, 또는 3개 이상이라면 최종적인 클러스터를 3개로 사용하는게 적합할까? (클러스터 개수에 대한 실험은 x)
-> 최적의 클러스터 수를 도출해내는 모듈을 추가하는게 어떨까?
참고문헌
http://dsba.korea.ac.kr/seminar/?mod=document&uid=1388
*코드 없음

to be data scientist