1. Introduction
- 클라우드 제공자는 다음 시간대의 workload를 조정하기 위해 computing resources를 예측하는 것이 중요함
- 따라서 시계열 분석을 하면 클라우드의 traffic data의 패턴을 파악할 수 있음
- 시계열 분석은 다양한 분야에서 쓰이지만, 가장 중요한 분야 중 하나는 internet traffic 분야임.
- Internet traffic 예측은 클라우드에서 real workload를 운영하기 위한 효과적인 resource provisioning에서 사용될 수 있음 - 클라우드 서비스에서는 elasticity가 중요함. elasticity는 피크 타임에 workload의 변동을 조절할 수 있는 능력을 의미함. (=Quality of service(QoS))
- Elasticity는 실시간으로 자동 조정가능해야 하고 불필요한 소비와 over/under-provisioning을 감소시킬 수 있어야 함. - 따라서 Service elasticity는 auto-scaling mechanism으로 실행되며 reactive와 proactive로 분류됨.
- Reactive mechanism은 rule-based로 모니터링과 정해진 임계치 활용
- Proactive mechanism은 과거데이터 이용해서 Next 예측
-> Deep Learning을 사용해 시계열의 pattern과 structure of data 파악 가능 - 따라서 본 논문에서는 network trafficc을 예측하기 위해 LSTM을 도입함
- 다양한 타입의 컴퓨팅 자원을 조정하기 위해 피크 타임에서의 work-load를 조정해야 함.
- Workload 변동을 예측하는 것은 response time을 최소화할 뿐만 아니라 resource활용에 효과적임.
2. Background approaches for Workload Prediction
A. Simple Moving Average(SMA)
: 과거 데이터 p개의 평균을 다음시점의 값으로 예측

B. Autoregressive Moving Average(ARMA)

[AR모델]
: 자기자신을 종속변수 y_t로 하고, 이전 시점의 시계열(Lag) [y_t-1,...,y_t-p]를 독립변수로 갖는 모델을 의미함.
[MA모델]
: 자기가신을 종속변수 y_t로 하고, 해당 시점과 그 과거의 white noise distribution error들을 독립변수로 갖는 모델을 의미함.
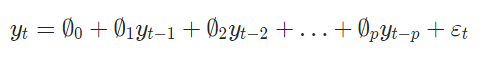
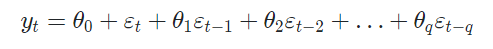
C. Autoregressive Integrated Moving Average(ARIMA)
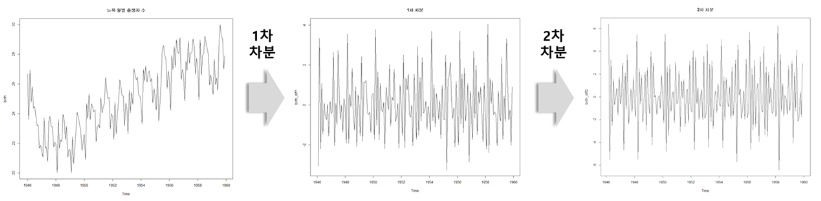
: AR, MA, ARMA 모델의 경우 데이터가 정상(Stationary)이어야 함으로 비정상(Nonstationary)인 경우는 차분(differencing)을 통해 데이터를 정상으로 변형해주어야 함. 즉, ARIMA는 ARMA 모형에 차분을 d회 수행해준 모델임.
3. Related Work
- 기존 Control-based approaches는 매개변수가 적절하지 않을 경우 시스템의 불안정성을 유발할 수 있기 때문에 적절한 parameter를 선택하기 어려움.
- 그외
- ARIMAX method- ARIMA model
- auto-scaling policy
- using a priority-based approach
- auto-scaling algorithm that is dynamic
- Reinforcement Learning
- LSTM-ED (Long Short-Term Memory Encoder-Decoder)
- DES (double exponential smoothing)
4. Description of Long Short-Term Memory (LSTM)
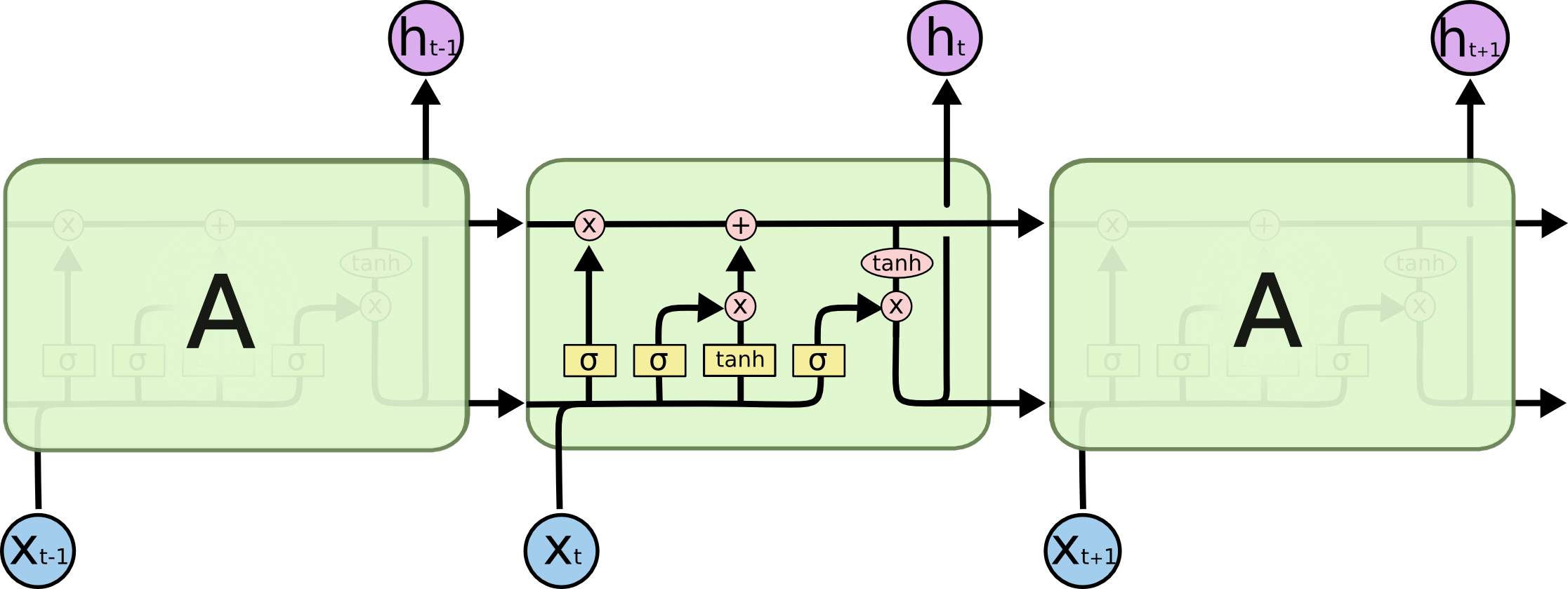
1. Cell state
: 정보가 바뀌지 않고 그대로 흐르도록 하는 역할
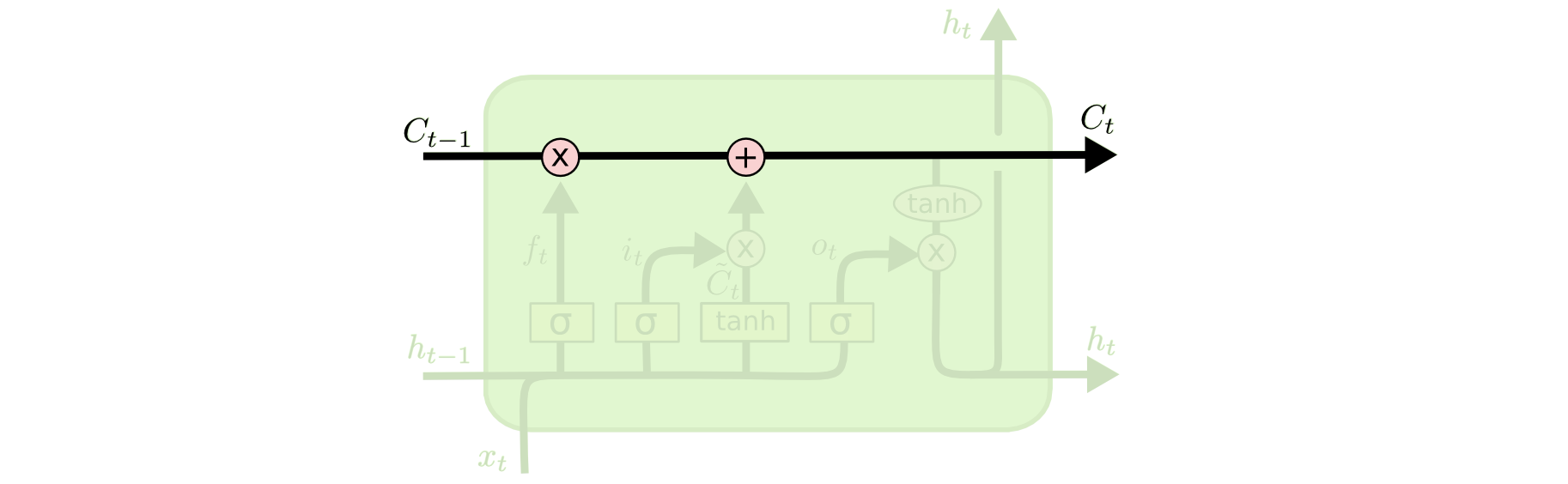
2. Forget gate
: cell state에서 sigmoid layer를 거쳐 어떤 정보를 버릴 것인지 정하는 역할
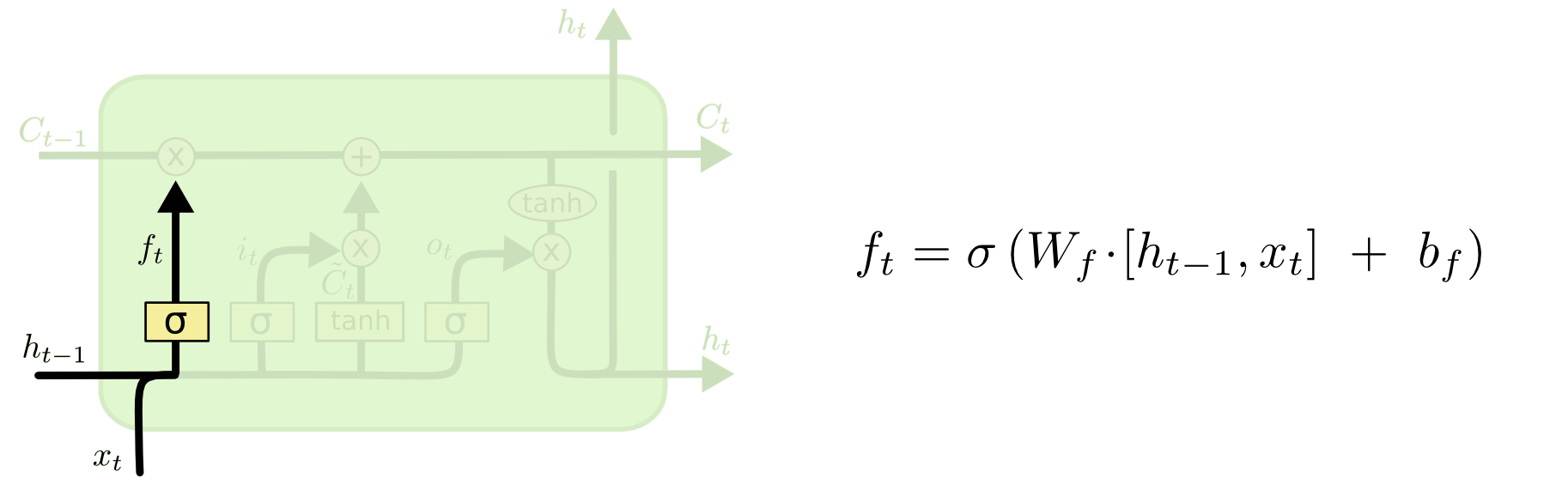
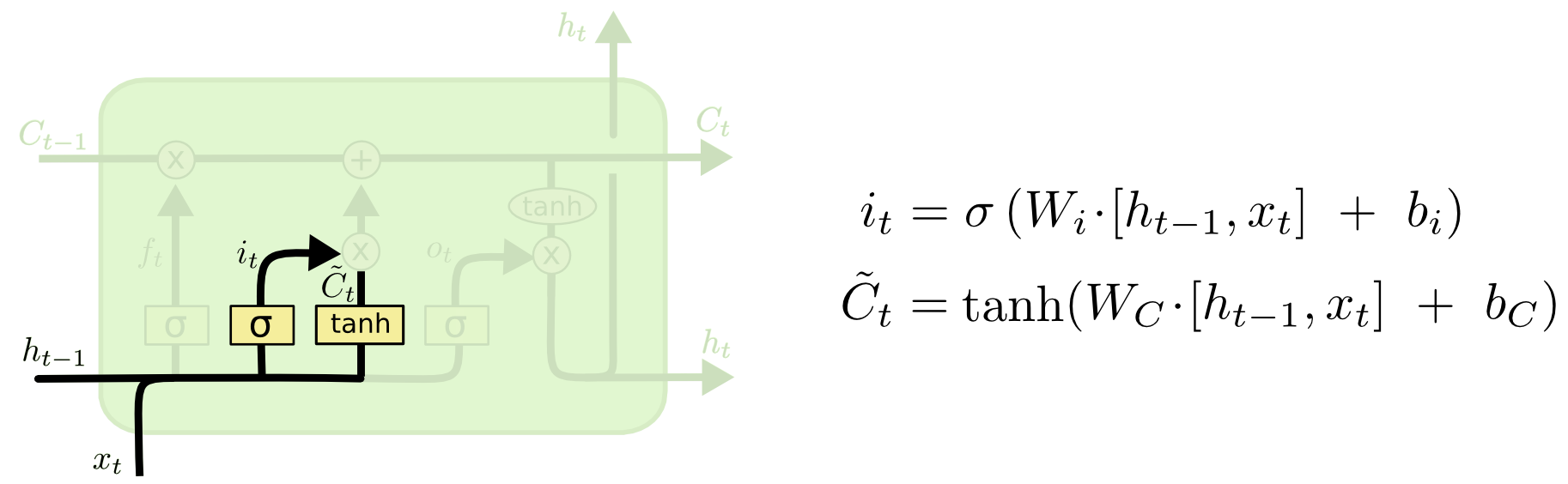
3. Input gate
: 앞으로 들어오는 새로운 정보 중 어떤 것을 cell state에 저장할 것인지 정하는 역할. 먼저 sigmoid layer를 거쳐 어떤 값을 업데이트 할 것인지를 정한 후 tanh layer에서 새로운 후보 Vector를 만듦
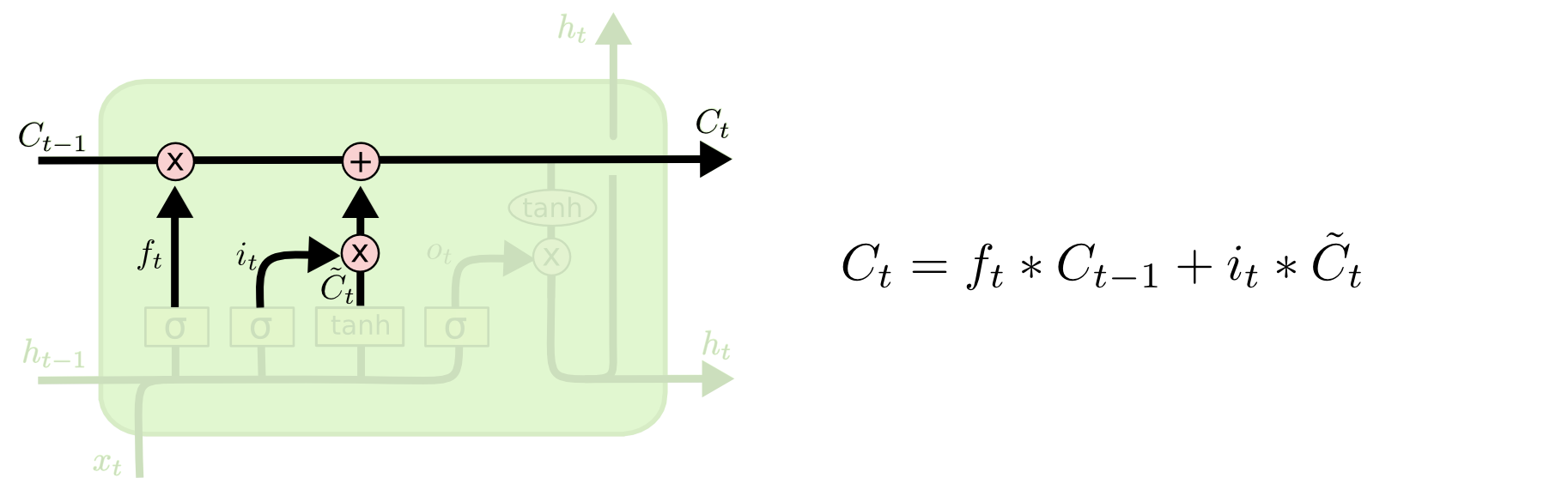
4. Cell state update
: 이전 gate에서 버릴 정보들과 업데이트할 정보들을 정했다면, Cell state update 과정에서 업데이트를 진행함.
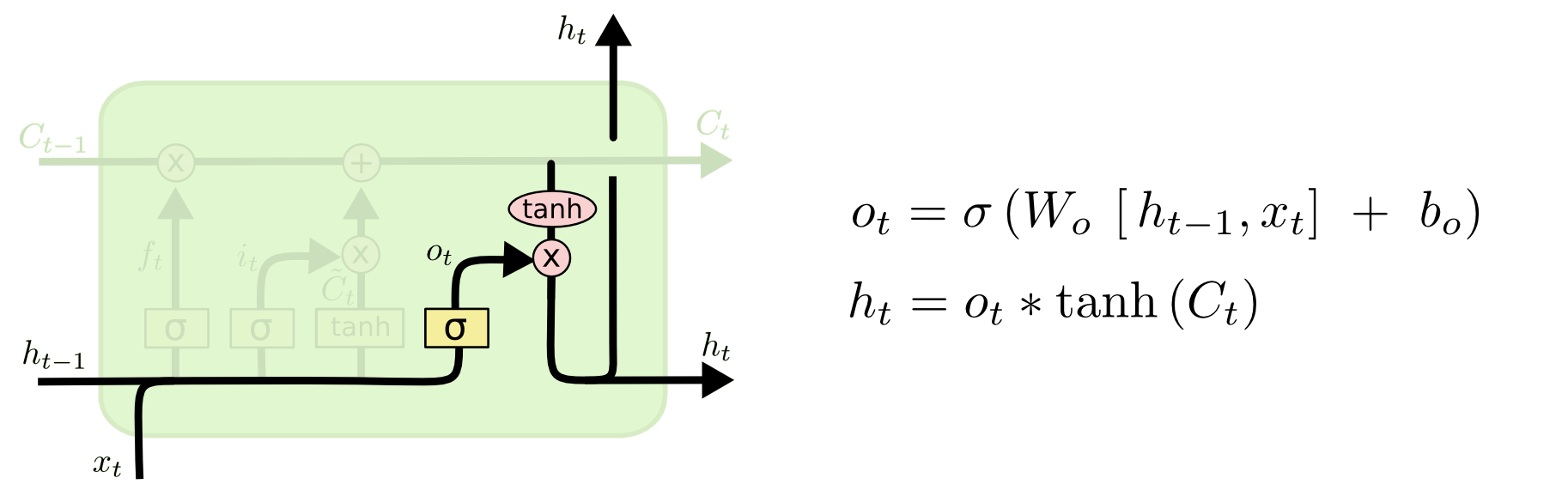
5. Output gate
: 어떤 정보를 output으로 내보낼지 정하는 역할. 먼저 sigmoid layer에 input data를 넣어 output 정보를 정한 후 Cell state를 tanh layer에 넣어 sigmoid layer의 output과 곱하여 output으로 내보냄.
5. Experimental setup and Result analysis
A. dataset
- 분산 서버의 시간 기준 평균 load 예측
- real web service logs from the Complutense University of Madrid
B. Approach
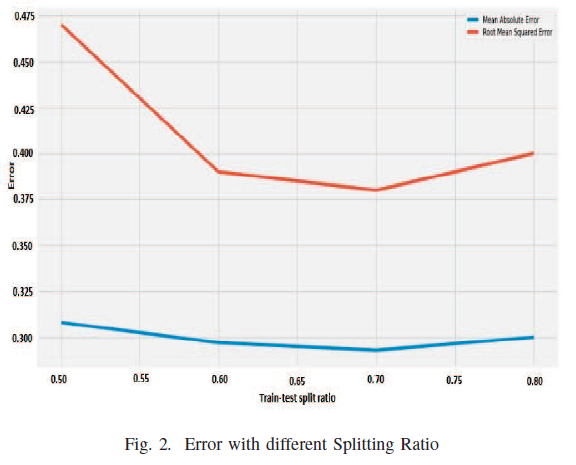
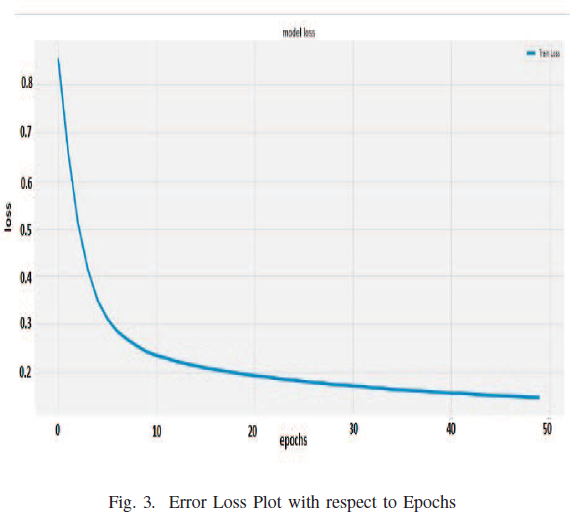
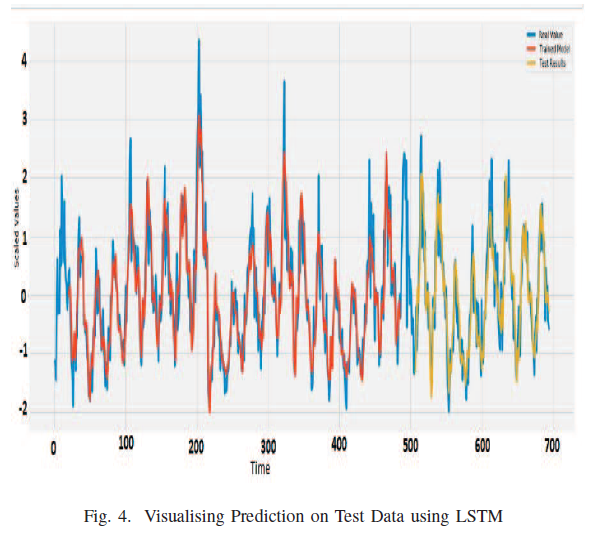
6. Conclusion and Future scope
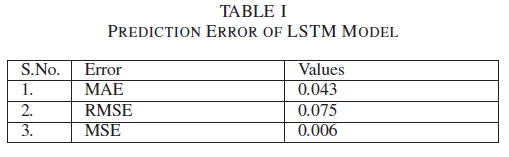
- LSTM으로 미래 workload를 예측하고 MSE, RMSE, MAE로 평가함
[향후 계획] - 다른 모델들과의 비교 필요함
- 몇개의 containers를 할당할 것인지 분석을 통해 정할 것임
- hybrid auto-scaling을 수행할 것임
