1. 서론

- 패키지 테스트를 거치고도 제품에 결함이 발견되는 경우 있음.
- 이러한 문제를 보완하기 위해 최종 단계에서 각 로트(lot)로부터 표본을 추출하여 패키지 품질 보증 검사(package quality assurance)를 진행함.
- 패키지 품질 보증 검사는 고객의 요구에 따라 다양한 검사를 진행하며, 불량으로 판정된 로트는 제조 공정에서 재검사됨.
- 이 과정에서 불량률이 증가하면 비용이 증가하게 되고 근래에 제품의 대용량화로 인해 이러한 문제는 더욱 심화됨.
-> 이러한 문제 해결을 위해, 품질 보증 검사 시 공정의 합격로트와 불량로트를 예측하는 모델을 만들어 실제 공정에 적용하려는 시도 진행중
-> BUT 품질 보증 검사 공정의 예측 모델은 2가지 이유로 예측 성능을 유지하기 힘듦.
1. 변수의 수가 많아 변동의 시점과 원인을 직접 파악하기 어려움
2. 반도체 산업 특성상 품질 향상을 위한 변경과 함께 수익을 극대화하기 위한 양산성 향상 작업이 동시에 진행되어 데이터 분포가 지속적으로 변화함.
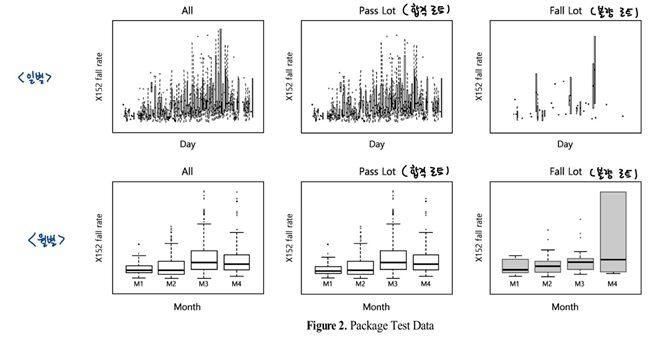
=> 따라서, 효과적인 모델은 이러한 변화를 신속하게 추적하고 대응할 수 있어야 함.
=> 본 연구에서는 예측 모델의 성능 저하를 방지하기 위해 데이터 변화 탐지에 따른 예측 모델의 갱신 시점을 제안하고자 함.
2. 데이터 변화 감지
2.1. 패키지 품질 보증 검사
- DRAM 패키지의 제조와 테스트 단계에서 진행된 모든 검사를 거쳐 합격된 로트가 들어오는 공정임
- 신뢰성 검사, 전기적 특성 검사, 실장 검사, 외관 검사로 이루어짐.
- 제한적인 시간과 비용으로 로트로부터 표본을 추출하여 조사하고 합격여부를 판정함.
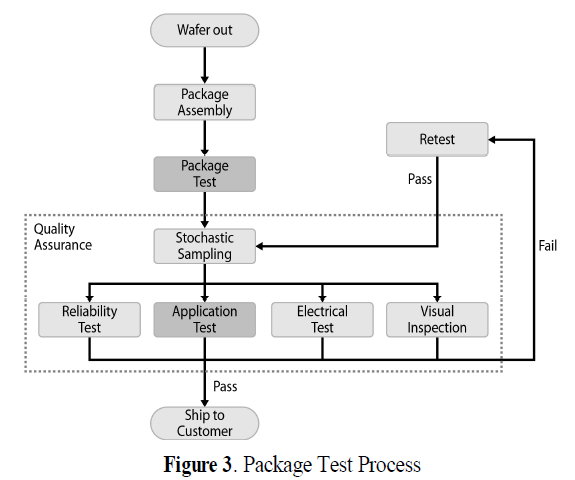
- (입력변수: 패키지 테스트 공정의 센서 데이터 / 출력 변수: 품질 보증 검사 중 실장 검사의 결과) 학습을 통해 합격로트와 불량 로트 예측 및 분류
- 이러한 분류 모델은 사후 확률 P(y|x)에 영향을 미치는 변화가 발생하게 되면 분류 모델의 성능이 저하되며, 이를 방지하기 위해서는 실제 변화에 대한 정확한 탐지와 적절한 모델의 갱신이 필요함
2.2. 개념 변화 (Concept Drift)
- 시간 t의 각 시점에서 모든 예는 동시확률분포(joint probability) Pt(x,y)를 갖는 데이터에 의해 생성됨.
- 하지만 만약 t와 t+a 두 개별 시점에 존재하는 x에 대해 동시확률분포가 달라진다면 데이터의 분포가 시간에 따라 달라진다고 볼 수 있음.
- 이는 예측 모델의 성능을 크게 저하시킴.
- 개념 변화는 사후 확률에 변화를 주는 실제 변화(real drift)와 결정 경계에 영향을 주지 않는 가상 변화(virtual drift)로 구분됨.
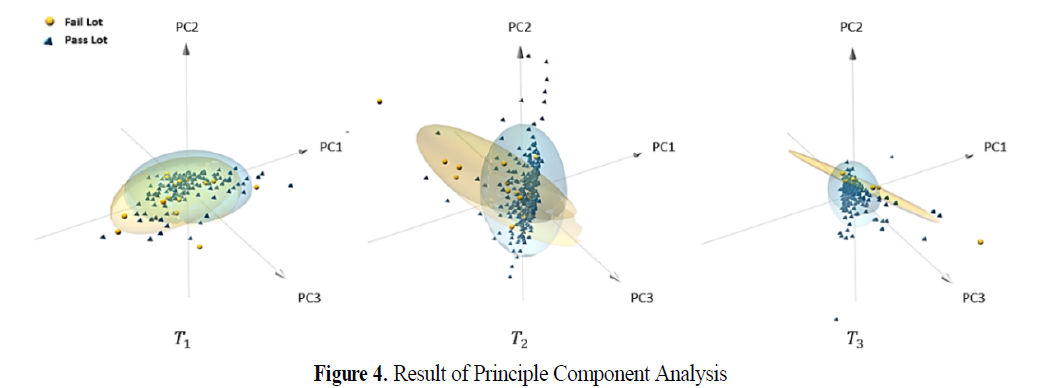
: T3 시점으로 진행될수록 합격로트와 불량로트가 잘 구분되는 것을 확인할 수 있음.
-> 따라서 본 연구는 개념 변화의 실제 변화를 탐지함으로써 예측 모델의 갱신 시점을 결정하는 방법을 제안하고자 함.
2.3. 관련 연구
<개념 변화 탐지 방법>
(1) 통계적 절차 제어를 기반으로 하는 탐지
(2) 순차적 분석에 기초한 탐지
(3) 두 개의 다른 시 구간의 분포를 모니터링
(4) 상황별 접근 방법
<개념 변화 탐지의 기본 개념>
: 예측 모델의 온라인 오류율을 제어하는 것 (분포가 안정적일수록 오류 줄어듬)
<개념 변화 탐지 종류>
- DDM(drift detection method): 오류율의 신뢰도 구간을 추정하고 그 수준을 경고(warning level)와 개념 변화(drift level)로 나누어 오류율의 변화를 추적하여 개념 변화 탐지함.
(-)데이터의 변화가 천천히 진행되면 탐지가 어려운 단점 있음 - EDDM(exponentially weighted moving average charts for detecting concept drift): 오류율의 급격한 변화를 탐지하기 위해 지수 가중 이동 평균을 이용하였으며, 오탐지율 제어 간으함
-> 하지만 기존 방법들은 예측 결과를 0과 1로 묘사하여 개념 변화를 탐지하기 때문에 데이터의 변화 패턴을 판단할 수 있는 고유 속성 정보의 손실 발생
=> 따라서 본 연구에서는 예측 결과 대신 입력 변수의 변수 중요도(variable importance)를 사용하여 데이터의 특징 표현하고자 함.
(입력 변수의 중요도가 시간에 따라 변화하는 것은 결국 입력 변수가 출력 변수에 미치는 영향이 달라지는 것을 의미하기 때문에)
3. 불량 예측 모델의 갱신
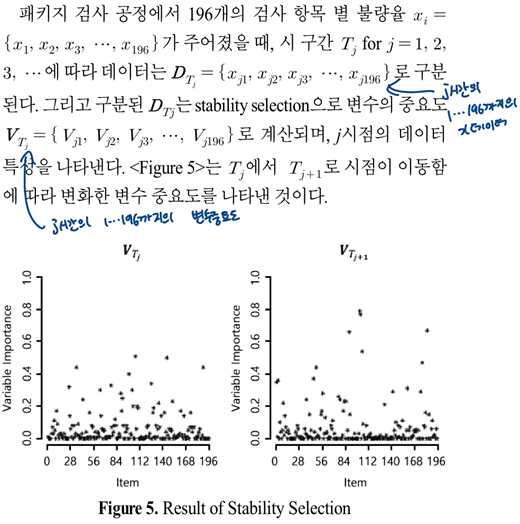
3.1. 시 구간별 데이터의 특질 추출
- 고차원 데이터에 적합한 변수 선택법으로 stability selection 방법을 사용함.
- stability selection은 lasso와 서브 샘플링을 결합한 방법으로, 산출되는 값은 데이터에서 무작위로 리샘플링할 때 각 변수가 선택될 확률임.
- 전진 선택법 등과 같은 방법은 최적의 변수 조합을 구하지 못하는 지역 최적화(local optimal)문제가 있음
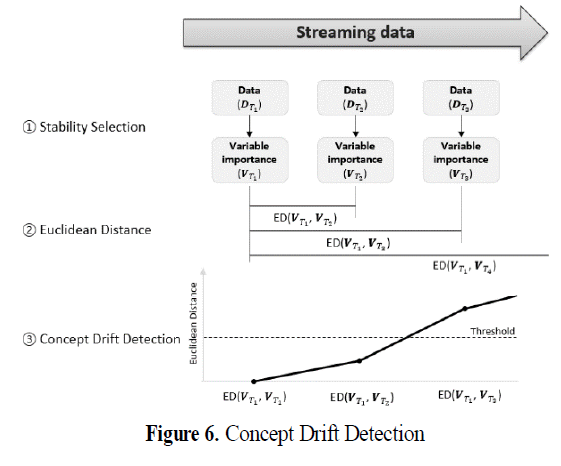
3.2. 시 구간별 거리 측정
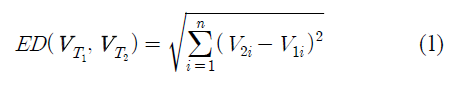
- 두 시점 T1과 T2간 데이터 변화의 크기는 유클리드 거리를 사용함
3.3. 예측 모델의 갱신
- 검사 시점에 따라 D 형태로 만들고 이를 stability selection을 통해 각 시점에 해당하는 n개의 변수의 변수 중요도 V를 계산함.
- 이 변수 중요도 V는 초기값 Vt1을 기준으로 이후 시점과 유클리드 거리 ED(Vt1, Vt2), ED(Vt1, Vt3),...를 측정해 나감.
- 이렇게 측정된 유클리드 거리는 데이터 분포의 변화를 대변하는 척도임.
- 이후 임계값을 설정해 모델을 갱신하는 트리거로 사용함.
4. 실험 계획 및 결과
4.1. 대상 데이터
4.2. 실험 환경
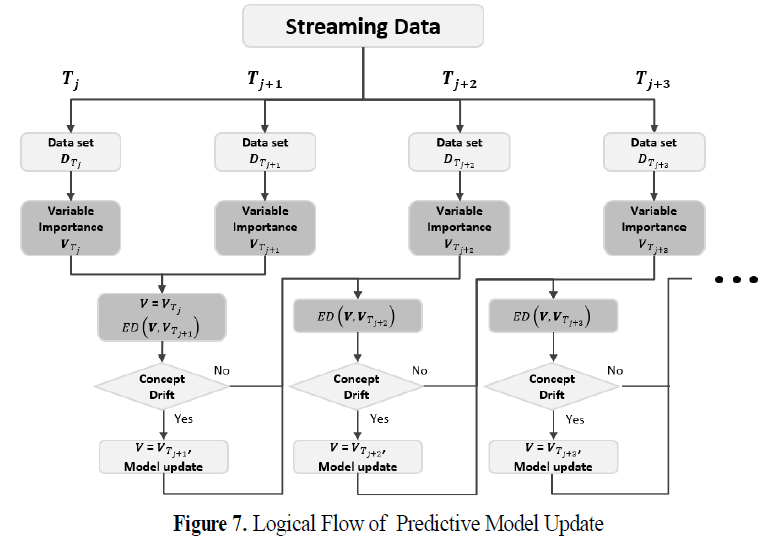
- 거리 측정의 기준점 V는 변화가 감지된 시점 Tj의 변수 중요도 Vtj로 바뀜
- 그리고 변화가 탐지될 때까지 다시 반복적으로 거리를 측정하여 변화 크기를 모니터링하게 됨.
4.3. 성능 평가 및 결과
- 분류기의 평균 예측 성능 평가보다는, 데이터의 흐름에서 모델의 작업 특성을 추적하는데 더 관심을 두어야 함.
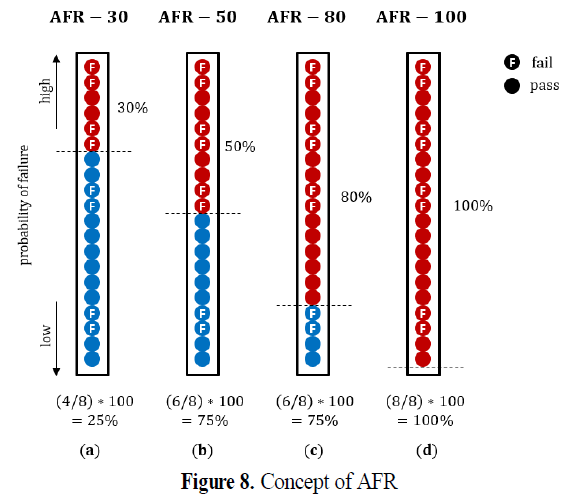
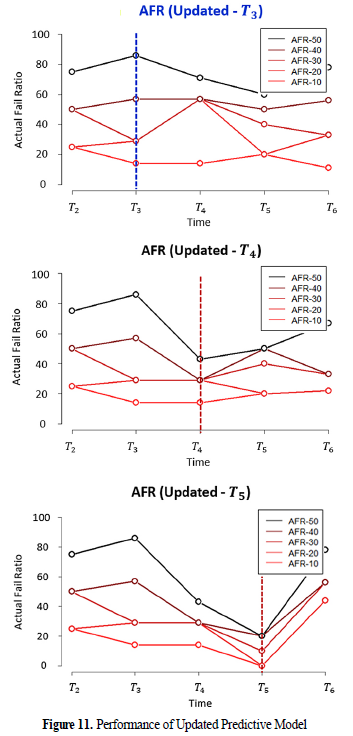
- Fig8은 현업에서 예측 모델의 성능 및 작업 특성을 평가할 때 사용하는 AFR(actual fail ratio)-a
- AFR-a는 불량으로 판정될 확률이 높은 a%의 로트에 포함된 실제 불량의 비율임.
- 불량으로 판정될 확률이 높게 예측된 로트들이 가능한 많은 수의 실제 불량을 포함하기를 기대함
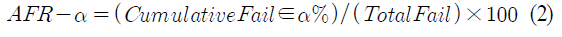
- 현업에서는 AFR-50을 예측 모델의 성능을 평가하는데 사용함.
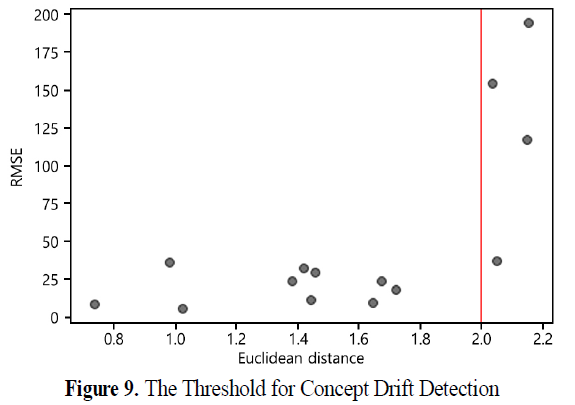
-> 본 연구에서는 기존에 수집된 데이터를 기반으로 선행 지표에 대한 평가를 진행하고 그 결과에 따라 실험적으로 임계점 설정함.
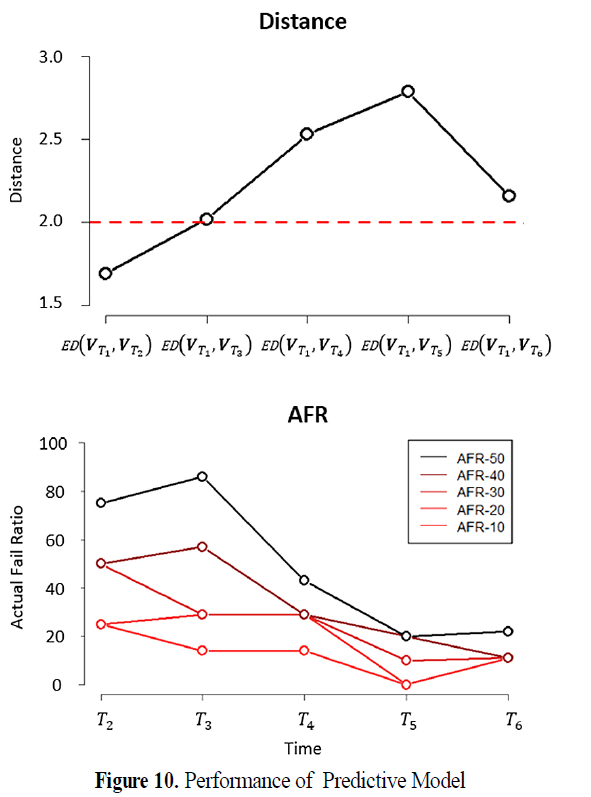
-> 예측 모델이 성능은 각 시점 간 유클리드 거리의 크기에 대체적으로 반비례하는 경향을 보임.
(+) 모델을 갱신하지 않을 경우 임계점을 넘어선 시점부터 예측 성능이 급격히 저하됨.
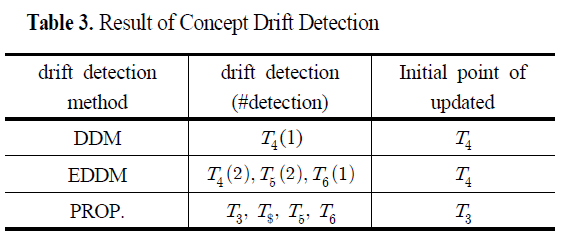
-> 본 논문에서 제안한 방법(PROP.)이 예측 모델의 급격한 성능 저하가 발생하기 전인 T3에서 개념 변화가 탐지되었으며, 이에 따라 기존의 방법들보다 빠른 T3에 예측 모델이 갱신됨.
5. 결론 및 추후 연구
- 예측 성능이 지속적으로 유지될 수 있음
- 현업에서 실시간으로 적용될 수 있음
- 불량이 발생할 확률이 높은 로트에 대해 선별적으로 검사 강화할 수 있음
- 비용의 증가 없이 합격된 로트가 고객에서 품질 문제를 발생시킬 확률을 낮출 수 있을 것으로 기대함.
[한계점]
- threshold를 정하는 논리적 근거가 더 필요할 것으로 보임.
