[2023 preprint] SimTS: Rethinking Contrastive Representation Learning for Time Series Forecasting (2회 인용)
Paper review
목록 보기
18/21
Abtract
- 대조학습을 시계열 예측에서 사용하고자 함
- 또한 positive pair와 negative pair를 정의하는데 일반화된 기법이 없음
- 본 논문에서는 잠재 공간에서 과거로부터 미래를 예측하는 방법을 학습하여 시계열 예측을 개선하기 위한 간단한 표현 학습 접근법인 SimTS를 제안함.
(Predictive Coding + SimSiam)
1. Introduction
- 대조학습을 시계열 예측에 사용하기에는 한계가 있음.
- 대조학습은 instances간의 discriminating하는 것을 목적으로 하기 때문임.
- 또한, 시계열 예측에서 positive pair와 negative pairs를 정의하는 것은 어려움.
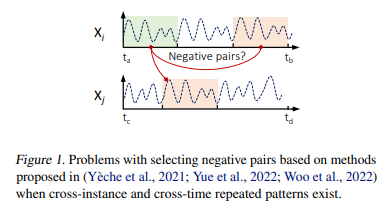
- 시간축에서 거리가 멀수록 negative pair로 간주하기도 하는데, strong periodicity를 가진 경우는 잘못된 pair를 생성함 (Fig 1)- disentanglement와 fusion을 사용하는 경우도 있는데, 이들은 데이터가 trend와 seasonality components로 표현 가능하다는 가정하에 작용함.
- 본 연구에서는 음의 쌍을 사용하지 않고 Siamese 구조를 사용하여 시계열 예측을 위한 새로운 표현학습 방법을 제안함.
What is important for time series forecasting with contrastive learning, and how can we adapt contrastive ideas more effectively to time series forecasting tasks?
-SimTS
2. Related Works
- InfoNCE
- ICA
- TNC
- TS2Vec
- CoST
- BTSF
3. Methods
3.1.Motivation
- 대조 학습을 활용한 시계열 예측에서 고려해야 할 요소
(1) 시계열 내에서 먼 거리에 위치한 반복되는 패턴의 가능성을 무시함.
(2) 서로 다른 시계열이 유사한 패턴을 가질 수 있다는 가능성을 간과함. - 즉, 좋은 표현은 예측 작업에서 과거의 세그먼트와 미래의 예측 사이의 시간적 종속성을 효과적으로 포착해야 함.
- mode collapse를 피하기 위해 stop-gradient 활용 (SimSiam)
- 최신 대조 모델인 CoST보다 더 나은 예측 성능 보임.
3.2. SimTS: Simple Representation Learning for Time Series Forecasting
- Time Series X를 history segment X_h와 future segment X_f로 분할
- history segment X_h와 future segment X_f를 encoder를 거쳐 representation 도출


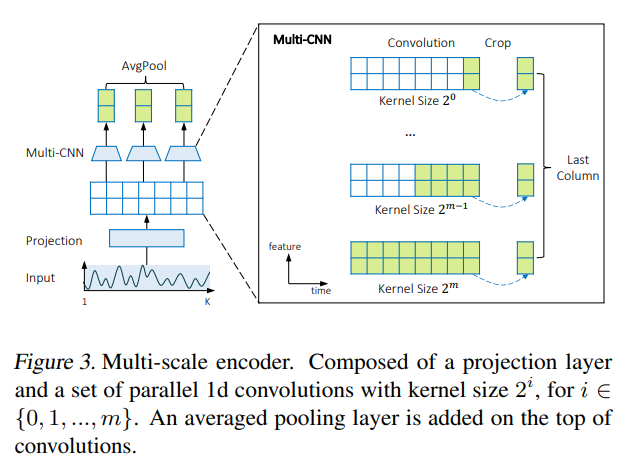
3-3. Multi-Scale Encoder
- 전역적이고 지역적인 패턴을 모두 추출하기 위해, 서로 다른 kernel size를 가진 여러 CNN blocks를 사용함
- 단기 예측의 경우 지역 패턴 학습 필요
- 장기 예측의 경우 전역 패턴 학습 필요
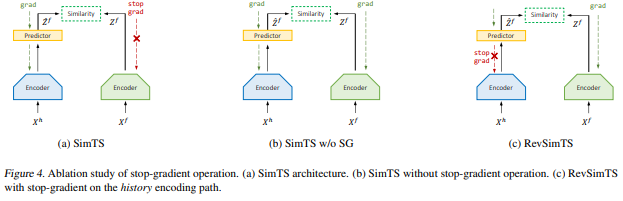
3-4. Stop-gradient Operation
- stop-gradient를 사용하여 인코더는 미래 표현 Z_f로부터 업데이트 받지 못하고 과거의 표현과 그 예측값만을 최적화하는 걸로 제한함.
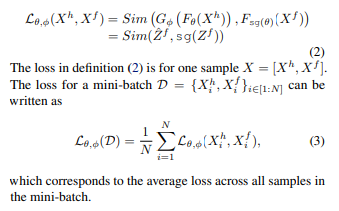
4. Experiments
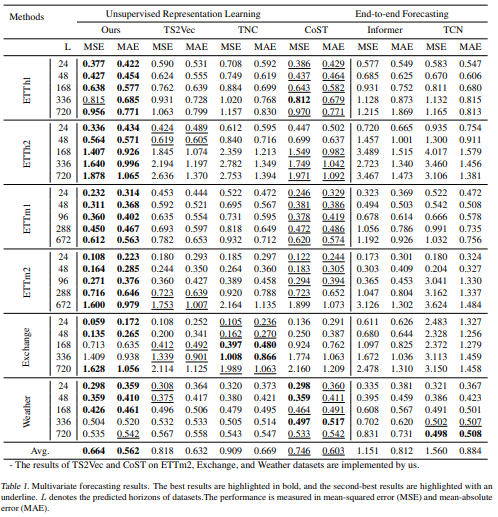
4.1. Datasets and Baseline
<비교모델>
- Representation Learning
: TS2Vec (Yue et al., 2022), CoST (Woo et al., 2022), TNC (Tonekaboni et al., 2021) - end-to-end Model
: Informer (Zhou et al., 2021), LogTrans (Li et al., 2019) - two-stage representation learning
: TS2Vec, CoST, TNC
<데이터>
-
전기 변압기 온도(Electricity Transformer Temperature, ETT) (Zhou et al., 2021)
- 이 데이터셋은 두 개의 시간당 샘플링된 데이터셋 (ETTh)과 두 개의 15분당 샘플링된 데이터셋 (ETTm)으로 구성되어 있음
- 이들은 두 개의 다른 중국 지역에서 2년 동안 수집됨
- ETT 데이터셋은 한 개의 오일 온도 특성과 여섯 개의 전력 부하 특성을 포함함.
- 단변량 예측에서는 오일 온도만 학습 및 예측에 사용하며, 다변량 예측에서는 모든 특성을 우리의 훈련 및 예측에 사용함.
-
환율(Exchange-Rate1) (Lai et al., 2018)
- 1990년부터 2016년까지 8개 외국의 일일 환율을 포함
- 호주, 영국, 캐나다, 스위스, 중국, 일본, 뉴질랜드, 싱가포르가 포함됨.
- 단변량 예측에서는 싱가포르의 값을 고려하고, 다변량 예측에서는 모든 국가의 값을 고려함.
- 날씨(Weather2)
- 약 1,600개의 미국 지역에 대한 4년간의 현지 기후 데이터를 포함
- 이 데이터는 10분마다 수집됨.
- 각 시간 단계에는 11개의 날씨 변수와 한 개의 타겟 특성인 '습구 섭씨'가 포함됨.
- 단변량 예측에서는 '습구 섭씨' 특성만 고려하고, 다변량 예측에서는 모든 특성이 포함됨.
4.2. Experimental setup
- 320-dimensional latent space
- L ∈ {24, 48, 168, 336, 720} for dataset ETTh1, ETTh2, Exchange, and Weather.
- For dataset ETTm1 and ETTm2, we set L ∈ {24, 48, 96, 288, 672}.
5. Ablation Study
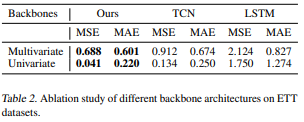
5.1. Backbones
- TCN, LSTM
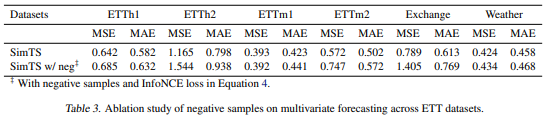
5.2. Negative Samples
- 그러나 부정적인 쌍을 포함하는 것이 전반적으로 유용하지 않다는 것을 의미하는 것이 아님.
- 단지 현재의 부정적인 쌍을 구성하는 방법이 비효율적이라는 것을 의미함.
- 따라서 향후 연구에는 더 나은 방법으로 부정적인 쌍을 구성하는 연구도 필요함.
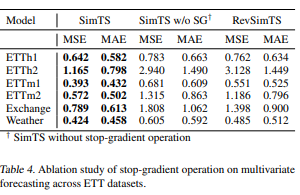
5.3. Stop-Gradient Operation
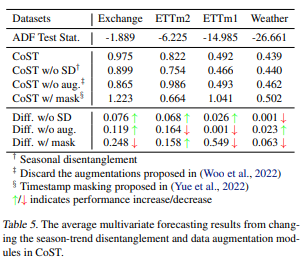
5.4. Disentanglement Assumption
- stationary하지 않은 데이터에서 잘 작동하지 않음을 확인함.
- ETT, ETTms와 같은 stationary하지 않은 데이터에서 예측 성능을 하락시킴
6. Conclusion
- 기존 표현 학습 방법이 다양한 유형의 시계열 데이터에 일괄적으로 적용되지 않음을 보여줌
- 또한 특정 데이터셋에 매우 의존적인 대조학습도 존재함
- 이에 제안 모델은 일부 제한 사항을 해겷하고 단순화하여 견고한 대조학습 모델을 제안함.
- 앞으로도 비규칙적인 시계열과 같은 더 여려운 데이터를 처리할 수 있도록 확장하고, 시계열 예측을 위한 효율적인 데이터 augmentation 기법을 탐구할 계획임.

to be data scientist