CPU와 GPU 차이
Core의 수와 명령어를 처리하는 방식의 차이
CPU
- CPU는 core의 수가 보통 4~6개, 많으면 10개 이다. CPU는 8 ~ 20개의 스레드를 동시에 실행시킬 수 있다
- 따라서 CPU는 한 번에 20가지의 일(스레드)을 할 수 있다
- CPU의 멀티스레드 능력은 아주 강력하다. 아주 많은 일을 할 수 있으며 엄청 빠르다. 그리고 독립적으로 수행한다
GPU
- GPU는 수천 개의 코어를 보유하고 있어 어떤 Task가 있을 때 이 일을 병렬로 수행하기 아주 적합하지만 그 Task는 전부 같은 Task여야 한다
- GPU는 각각의 코어가 더 느린 clock speed에서 동작한다. 그리고 그 코어들이 그렇게 많은 일을 할 수 없다
- GPU core들은 독립적으로 동작하지 않는다. 코어마다 독립적인 테스크가 있는 것이 아니라 많은 코어들이 하나의 테스크를 병렬적으로 수행하는 방식이다
메모리 사용 방식의 차이
CPU
- CPU에도 캐시가 있지만 비교적 작다
- CPU는 대부분의 메모리를 RAM에서 끌어다 사용한다
- RAM은 일반적으로 8, 12, 16, 32 GB 바이트 정도이다
GPU
- GPU는 칩 안에 RAM이 내장되어 있다
- 실제 RAM와 GPU간의 통신은 상당한 병목현상을 초래한다. 그렇기 때문에 GPU는 보통 칩에 RAM이 내장되어 있다
- GPU는 12GB의 메모리와 GPU 코어 사이의 캐싱을 하기 위한 일종의 다계층 캐싱 시스템을 가지고 있다
행렬곱(Matrix multiplication) 연산
- CPU는 아주 다양한 일을 할 수 있기 때문에 범용처리에 적합하고, GPU는 병렬처리에 더 특화되어 있다
- 그런 GPU에서 정말 잘 동작하고 아주 적합한 알고리즘은 바로 행렬곱(Matrix multiplication) 연산이다
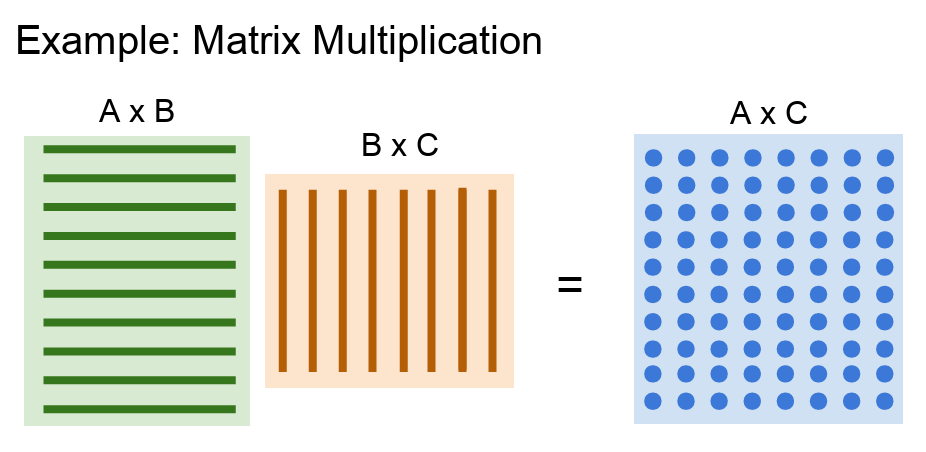
- 왼쪽은 행이 많은 행렬, 오른쪽은 열이 많은 행렬이다
- 결과 행렬은 두 행렬의 내적이다. 이 때의 내적 연산은 모두 서로 독립적이다
- 결과 행렬을 살펴보면 각각의 원소가 전부 독립적이다. 따라서 모두 병렬로 수행될 수 있다. 그리고 각 원소들은 모두 같은 일을 수행한다. 다만 서로 입력 데이터만 조금씩 다를 뿐이다
- GPU는 결과 행렬의 각 요소들을 병렬로 계산할 수 있으며 이러한 특성 때문에 GPU는 엄청나게 빠르다
- 이런 연산들은 GPU가 정말 잘 하는 것들이다. CPU였다면 각 원소를 하나씩만 계산할 것이다
- Convolution을 예로 들면 convolution에는 입력(텐서)이 있고 가중치가 있다. conv 출력은 마찬가지로 입력과 가중치간의 내적이다. CPU의 경우라면 이 연산을 각 코어에 분배시켜서 아주 빠르게 연산할 수 있도록 해준다
Programming GPUs
- GPU에서 직접 실행되는 코드를 작성하는 방법들
NVIDIA의 CUDA
- NVIDIA에서 CUDA를 지원하는데 그 코드를 보면 c언어의 형태와 유사하지만 GPU에서 실행되는 코드이다
- CUDA 코드를 작성한다는 것은 GPU의 성능을 전부 짜낼 수 있는 코드를 작성하는 것이기에 상당히 힘든 일이다
- 때문에 NVIDIA는 GPU에 고도로 최적화시킨 기본연산 라이브러리를 배포해 왔다
- cuBLAS
- 다양한 행렬곱을 비롯한 연산들을 제공한다. 이는 아주 고도로 최적화되어 있다
- GPU에서 아주 잘 동작하고 하드웨어 사용의 이론적 최대치까지 끌어올려 놓은 라이브러리이다
- cuDNN
- 이는 convolution, forward/backward pass, batch norm, rnn 등 딥러닝에 필요한 거의 모든 기본적인 연산들을 제공하고 있다
OpenCL
- OpenCL은 NVIDIA GPU에서만 동작하는 것이 아니라 AMD에서도 그리고 CPU에서도 동작한다
- 하지만 OpenCL은 아직 딥러닝에 극도로 최적화된 연산이나 라이브러리가 개발되지는 않았다. 그래서 CUDA보다는 성능이 떨어진다
Bottleneck 병목현상
- 실제로 GPU로 학습을 할 때 생기는 문제 중 하나는 Model과 Model의 가중치는 전부 GPU RAM에 상주하고 있는 반면, 실제 Train data(Big data)는 SSD와 같은 하드드라이브에 있다는 것이다
- 때문에 Train time에 디스크에서 데이터를 읽어드리는 작업을 세심하게 신경쓰지 않으면 Bottleneck이 발생할 수 있다
- GPU는 forward/backward 가 아주 빠른 것은 사실이지만, 디스크에서 데이터를 읽어드리는 것이 Bottleneck이 된다
- 이는 상당히 좋지 않은 상황이고 느려지게 된다
- 해결책 중 하나는 바로 데이터셋이 작은 경우에는 전체를 RAM에 올려 놓는 것이다. 데이터셋이 작지 않더라도, 서버에 RAM 용량이 크다면 가능할 수도 있다
- 혹은 HDD 대신에 SSD를 사용하는 방법이 있다. 데이터를 읽는 속도를 개선시킬 수 있다
- 또 다른 방법은 CPU의 다중스레드를 이용해서 데이터를 RAM에 미리 올려 놓는 것(pre-fetching)이다. 그리고 buffer에서 GPU로 데이터를 전송시키게 되면 성능향상을 기대할 수 있다
Deep Learning Frameworks
- 딥러닝 모델을 개발하고 훈련시키기 위한 도구 모음을 의미한다
- Framework를 사용하면 딥러닝 알고리즘을 쉽게 설계, 테스트, 그리고 개발할 수 있다
- 가장 널리 사용되는 프레임워크는 TensorFlow와 PyTorch이다
Deep Learning Framwork를 사용하는 이유
- Computational Graph
- 딥러닝 프레임워크를 이용하게 되면 이처럼 엄청 복잡한 그래프를 우리가 직접 만들지 않아도 된다
- gradient의 계산
- 딥러닝에서는 항상 그래디언트를 계산해야 한다
- Loss를 계산하고 Loss에 부합하는 가중치의 그래디언트를 계산해야 한다
- 딥러닝 프레임워크를 사용하면 forward pass만 잘 구현해 놓으면 back propagation은 알아서 구성된다
- GPU의 효율적 사용
- cuBLAS, cuDNN, CUDA 그리고 memory등을 직접 세심하게 다루지 않아도 된다
Numpy의 문제점
- gradient를 구하는 코드를 직접 작성한다고 하면 backward도 직접 작성해야 한다
- 이런 복잡한 수식을 구현하는 것은 아주 까다롭고 고통스러운 일이다
- 또 다른 문제점은 GPU에서 동작하지 않는다는 것이다
- umpy는 CPU에서만 동작한다
- 그렇기 때문에 Numpy만 쓰는 사람들은 GPU의 엄청난 계산 능력을 체험하지 못하게 된다
- 다시 말하자면 그때그때 마다 그래디언트를 스스로 계산하는 것은 상당히 힘든 일이다. 때문에 딥러닝 프레임워크의 목표는 바로 여러분이 forward pass 코드를 Numpy 스럽게 작성을 해 놓으면 GPU에서도 동작하고 그래디언트도 알아서 계산해 주기에 Framework를 사용한다
Static Graphs vs Dynamic Graphs
Static Graphs
- 그래프가 단 하나만 고정적으로 존재한다
- TensorFlow에서 사용하는 방식이다
- 정적 그래프는 연산의 흐름을 미리 정의하고, 이후에 데이터를 통해 그래프를 실행하는 방식이다
- 그래프를 한번 구성해 놓으면 메모리 내에 그 네트워크 구조를 가지고 있게 된다. 그렇게 되면 그 자체를 Disk에 저장할 수 있다. 후에 원본 코드 없이도 그래프를 다시 불러올 수 있다
주요 특징
- 그래프 최적화
- 정적 그래프는 미리 정의되기 때문에, 컴파일 시간에 그래프의 최적화가 가능하다
- 일부 연산들을 합쳐버리고 재배열시키는 등으로 가장 효율적으로 연산을 하도록 최적화 시킬 수 있다
- 이는 실행 시간을 줄이고, 메모리 사용량을 최소화하는 데 도움이 된다
- 병렬 처리
- 정적 그래프는 병렬 처리를 쉽게 구현할 수 있다
- 모든 연산이 미리 정의되어 있기 때문에, 연산 간의 의존성을 파악하고 해당 연산을 동시에 실행할 수 있다
- 이식성
- 정적 그래프는 언어나 플랫폼에 독립적이다
- 그래프가 한 번 정의되면, 다양한 환경에서 그래프를 실행할 수 있다
Dynamic Graphs
- 매번 forward pass할 때마다 새로운 그래프를 구성한다
- PyTorch에서 사용하는 방식이다
- 동적 그래프는 연산이 실행되는 동안 그래프를 구성하는 방식이다
- 즉, 그래프는 데이터가 흐를 때마다 새롭게 생성되고 업데이트 된다
- "그래프 구성" 과 "그래프 실행" 하는 과정이 얽혀 있기 때문에 모델을 재사용하기 위해서는 항상 원본 코드가 필요하다
주요 특징
- 유연성
- 동적 그래프는 그래프 구조를 런타임에 동적으로 변경할 수 있다
- 이는 복잡한 아키텍처를 쉽게 구현하고, 조건부 실행을 포함하는 그래프를 만드는데 유리하다
- 직관적인 디버깅
- 동적 그래프는 파이썬과 같은 동적 언어의 자연스러운 흐름을 따르므로, 디버깅이 더 쉽다
- 중간 결과를 출력하거나, 체크포인트를 설정하고, 코드를 단계별로 실행하는 등의 작업이 가능하다
- 자연스러운 흐름 제어
- 동적 그래프는 파이썬의 제어 흐름 구문(if, while 등)을 자연스럽게 사용할 수 있다
- 이는 반복문을 이용한 RNN 등의 모델을 쉽게 구현할 수 있게 한다
출처 및 참조

공부 기록