Regularization
- 모델의 과적합(Overfitting)을 방지하는 기법 중 하나이다
- 과적합 : 모델이 학습 데이터에 지나치게 적응해 새로운 데이터에 대한 성능이 떨어지는 현상
- Ensemble이 아닌 단일 모델의 성능을 향상시키기 위해 사용한다
- 다양한 전략으로 train/test error간의 격차를 줄여보려는 것이 목적이다
- 우리가 모델에 어떤 것을 추가할 때 모델이 training data에 fit하는 것을 막아준다
- 한 번도 보지 못한 데이터에서의 성능을 향상시키는 방법이다
- Neural network에서 가장 많이 사용하는 regularization은 바로 dropout이다
Dropout
- Dropout은 학습 과정에서 신경망의 일부 뉴런을 임의로 '끄는' 것을 의미한다. 이 '끄는' 작업은 각 훈련 단계에서 무작위로 수행되며, 이로 인해 신경망이 특정 뉴런에 과도하게 의존하는 것을 방지한다
- Dropout은 정말 간단하다. forward pass 과정에서 임의로 일부 뉴런을 0으로 만들면 된다
- 자세하게 말하자면 activation을 0으로 설정한다
- 각 레이어에서 next activ = prev activ * weight이다
- 현재 activations의 일부를 0으로 만들면 다음 레이어의 일부는 0과 곱해진다
- forward pass할 때마다 0이 되는 뉴런이 바뀐다
- Dropout은 한 레이어씩 진행하게 된다
- 한 레이어의 출력을 전부 구하고 임의로 일부를 0으로 만들고 다음 레이어로 넘어간다
- Dropout의 주요 장점 중 하나는 구현이 매우 간단하다는 것이다. 또한, 학습 시간에만 드롭아웃을 적용하고 예측이나 테스트 시에는 모든 뉴런을 사용하므로 원래의 신경망 성능을 그대로 유지할 수 있다
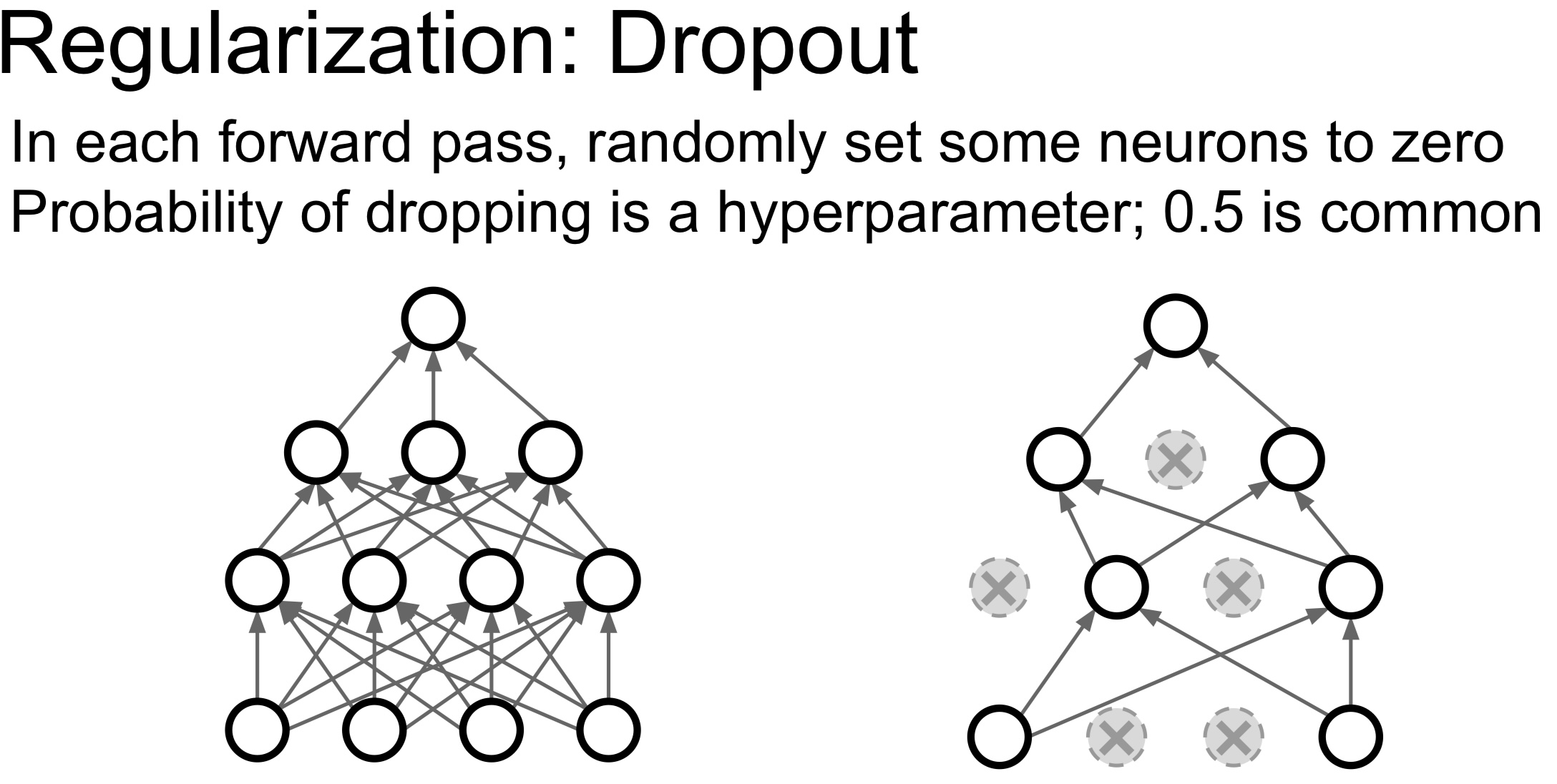
앙상블 효과
- Dropout은 실질적으로 앙상블 학습을 수행하는 것과 유사한 효과를 준다
- 위 이미지에서 오른쪽의 Dropout을 적용한 네트워크를 살펴보면 뉴런의 일부만 사용하는 서브네트워크라는 것을 알 수 있다
- 또한, Dropout으로 만들 수 있는 서브네트워크의 경우의 수가 정말 다양하다는 것을 알 수 있다
- 따라서 Dropout은 서로 파라미터를 공유하는 서브네트워크 앙상블을 동시에 학습시키는 것이라고 생각할 수 있다
- 이렇게 여러 다른 신경망을 학습시키는 것은 각각의 신경망이 서로 다른 방식으로 오차를 만들 가능성이 있기 때문에, 이 오차들이 상호 보완되어 전체적인 성능을 향상시키는 효과가 있다
과적합 방지
- Dropout을 적용하게 되면 네트워크가 어떤 일부 features에만 의존하지 못하게 해준다
- 대신에 모델이 예측할 때 다양한 features를 골고루 이용할 수 있도록 한다
- 따라서 Dropout이 Overfitting을 어느정도 막아준다고 할 수 있다
Inverted dropout
- Dropout을 역으로 계산한다
- Test time에서는 곱하기 연산이 하나 추가되는 것은 계산효율이 떨어지기에 Test time에는 기존의 연산을 그대로 사용하고 대신 Train time 에서 p를 나눠준다. 보통 train은 GPU로 하기 때문이다
- Train time에서는 곱하기 몇 번 추가되는 것에 별로 신경쓰지 않지만 Test time에서는 가능한 효율적으로 동작하길 원한다
Batch Normalization
- 각 레이어의 입력 분포를 정규화하여 학습 속도를 개선하고, 초기화에 대한 의존성을 줄여주며, 과적합을 방지하는 효과가 있다
- 배치 정규화는 각 레이어에서 활성화 함수의 입력에 대해 평균이 0이고 표준편차가 1인 정규분포를 갖도록 조정한다
- 이는 미니배치(mini-batch)의 데이터를 사용하여 계산한다
- 구체적으로는, 미니배치의 데이터를 통해 평균과 분산을 계산하고, 이를 통해 정규화를 수행한다
- 이렇게 하면 각 레이어의 입력 분포가 일정하게 유지되어 '내부 공변량 변화(Internal Covariate Shift)' 문제를 완화시킨다
- 이는 학습 속도를 크게 향상시키며, 또한 배치 정규화 레이어는 정규화 과정에서 약간의 노이즈를 추가하는 효과도 있어, 이는 드롭아웃(Dropout)과 비슷한 방식으로 과적합을 방지하는 효과도 있다
- Train time의 BN를 상기해보면 mini batch로 하나의 데이터가 샘플링 될 때 매번 서로 다른 데이터들과 만나게 된다
- Train time에서는 각 데이터에 대해서 이 데이터를 얼마나 어떻게 정규화시킬 것인지에 대한 확률성이 존재한다
- 하지만 test time에서는 정규화를 mini batch 단위가 아닌 global 단위로 수행함으로써 확률성을 평균화 시킨다
- 이런 특성 때문에 BN 은 Dropout과 유사한 Regularization 효과를 얻을 수 있다
- Train time에는 확률성(noise)이 추가되지만 Test time에서는 전부 평균화 되기 때문이다
- 실제로 BN을 사용할 때는 Dropout을 사용하지 않는다. BN에도 충분히 regularization 효과가 있기 때문이다
Data Augmentation(데이터 증강)
- 기존의 학습 데이터를 변형하거나 추가하여 데이터의 양을 증가시키는 기법이다
- 이 방법은 학습 데이터가 부족한 경우나 과적합을 방지하고자 할 때 유용하게 사용된다
- 이미지 데이터의 경우, 회전, 확대/축소, 뒤집기, 색상 변경 등의 변형을 통해 데이터를 증강할 수 있다
- 텍스트 데이터의 경우, 단어의 순서를 바꾸거나 동의어를 사용하는 등의 방법으로 데이터를 증강할 수 있다
- Data Augmentation은 모델이 데이터의 다양한 변형에 대해 강건하게 만들어주므로, 일반화 성능을 향상시키는 데 효과적이다
DropConnect
- activation이 아닌 weight matrix를 임의적으로 0으로 만들어주는 방법이다
- Dropout이 각 레이어의 뉴런을 무작위로 '끔'으로써 과적합을 방지하는데 반해, DropConnect는 신경망의 가중치를 무작위로 '끔'으로써 과적합을 방지한다
- 즉, 학습 과정에서 신경망의 연결(가중치) 일부를 무작위로 선택하여 해당 연결을 끊는 방식이다
- DropConnect의 이점은 Dropout보다 더 많은 모델 구성을 탐색할 수 있다는 것이다. 이는 더 다양한 앙상블 효과를 가져와 일반화 성능을 더욱 향상시킬 수 있다
- 하지만, DropConnect의 단점으로는 계산 복잡성이 증가한다는 점이 있다. Dropout에 비해 DropConnect는 더 많은 무작위성을 도입하기 때문에, 학습 과정이 더 복잡해지고 연산 비용이 증가할 수 있다
Fractional Max Pooling
- 기존 2x2 maxpooling 연산은 고정된 2x2 크기의 윈도우를 슬라이딩하여 각 윈도우 내에서 가장 큰 값을 선택하는 방식이다
- 반면 fractional max pooling에서는 윈도우의 크기가 랜덤하게 변동하며, 이는 각각의 입력에 대해 다른 풀링 영역을 생성한다. 이로 인해 모델이 데이터에 과적합하는 것을 방지하고, 일반화 성능을 향상시킨다
- 기존의 정수 스케일의 Max Pooling과 달리, Fractional Max Pooling은 풀링 영역을 분수로 정의함으로써 더 많은 다양성을 도입한다
Transfer Learning
- 모델을 빠르게 학습시킬 수 있는 방법이다
- overfitting이 일어날 수 있는 상황중 하나는 바로 충분한 데이터가 없을 때이다. 데이터가 충분치 않을 때 모델은 아주 작은 데이터셋을 지나치게 overfit할 수 있다. Regularization이 이를 해결할 수 있는 전략 중 하나이지만 Transfer learning 이라는 방법도 있다
- Transfer learning은 "CNN 학습에는 엄청많은 데이터가 필요함" 이라는 미신을 무너뜨려 버린다

- 이 CNN을 가지고 우선은 ImageNet과 같은 아주 큰 데이터셋으로 학습을 한 번 시킨다

- 그 후 Imagenet에서 학습된 features를 우리가 가진 작은 데이터셋에 적용한다
- 이제는 1000개의 ImageNet 카테고리를 분류하는 것이 아니라 10종의 강아지를 분류하는 문제이다. 데이터는 엄청 적다
- 이 작은 데이터셋은 C개의 클래스만 가지고 있다
- 일반적인 절차는, 우선 가장 마지막의 FC Layer는 최종 feature와 class scores간의 연결인데 이를 초기화 시킨다
- 기존에 ImageNet을 학습시킬 때는 4,096 x 1,000 차원의 행렬이었지만 새로운 문제를 풀기 위해서 4,096 x 10(C)으로 바꿔주게 된다
- 그리고 방금 정의한 가중치 행렬은 초기화시킨다
- 그 다음 나머지 이전의 모든 레이어들의 가중치는 freeze 시킨다
- 그렇게 되면 linear classifier를 학습시키는 것과 같다. 오로지 마지막 레이어만 가지고 우리 데이터를 학습시키는 것이다
- 이 방법은 사용하면 아주 작은 데이터셋일지라도 아주 작 동작하는 모델을 만들 수 있다
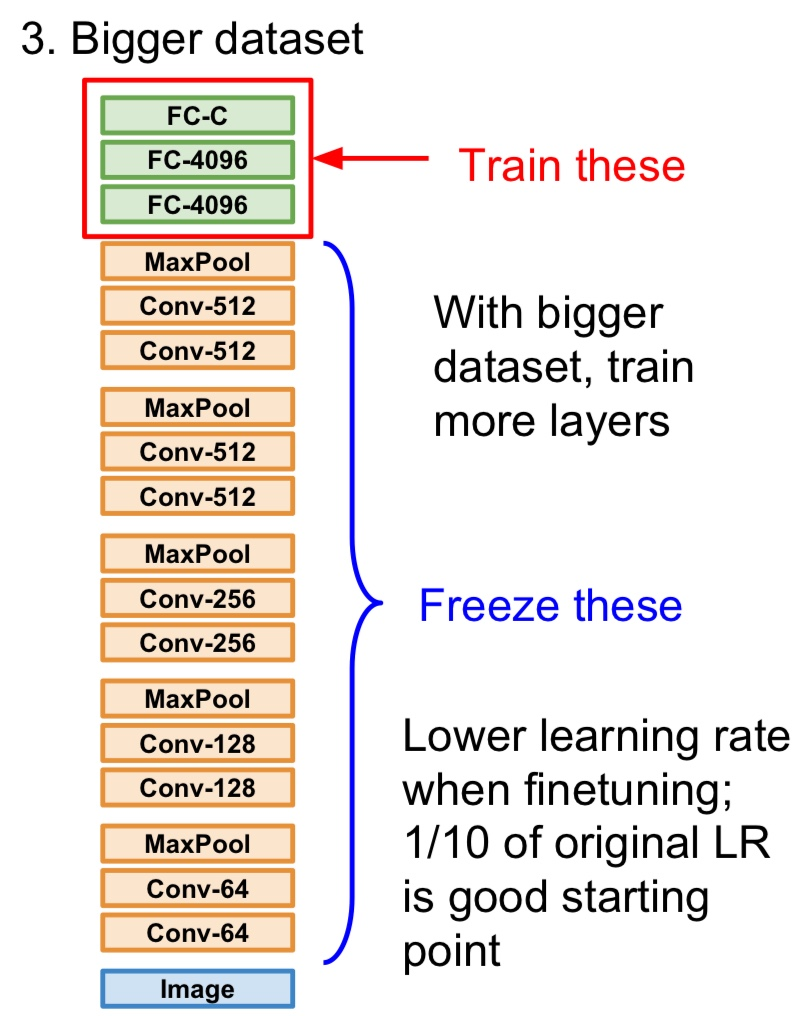
- 만일 데이터가 조금 더 있다면 전체 네트워크를 fine-tuning 할 수 있다
- 최종 레이어들을 학습시키고 나면, 네트워크의 일부만이 아닌 네트워크 전체의 학습을 고려해 볼 수도 있다
- 데이터가 더 많이 있다면 네트워크의 더 많은 부분을 업데이트 시킬 수 있을지도 모른다
- 이 부분에서는 보통 기존의 Learning rate보다는 낮춰서 학습시킨다. 왜냐하면 기존의 가중치들이 이미 ImageNet으로 잘 학습되어 있고 이 가중치들이 대게는 아주 잘 동작하기 때문이다
- 우리가 가진 데이터셋에서의 성능을 높히기 위해서라면 그 가중치들을 아주 조금씩만 수정하면 될 것이다
- Transfer Learning는 특정 분야에서 학습된 신경망의 지식을 다른 관련 분야의 문제를 해결하는 데 활용하는 기법이다
- 보통, 대규모 데이터셋(예를 들어, ImageNet)에서 사전 학습된 모델의 가중치를 초기값으로 사용하고, 이를 특정 작업에 맞게 미세 조정(Fine-tuning)한다
출처 및 참조

공부 기록