Optimization(최적화)
- 모델의 성능을 개선하기 위해 사용되는 기법을 의미한다
- 주로 모델의 손실 함수(Loss Function)를 최소화하는 파라미터를 찾는 과정을 말한다
- Nerwork의 가중치에 대해서 손실 함수를 정의해 놓으면 이 손실 함수는 그 가중치가 얼마나 좋은지 나쁜지를 알려준다
- optimization 알고리즘들은 training error를 줄이고 손실함수를 최소화시키기 위한 역할을 수행한다
- 하지만 사실 우리는 Training error에 크게 신경쓰지 않는다
- 대신에 "한번도 보지 못한 데이터"에 대한 성능이 더 중요하다
- 우리가 원하는 것은 train/test error의 격차를 줄이는 것이다
Stochastic Gradient Descent(SGD)
- 가장 간단하고 널리 사용되는 최적화 알고리즘
- 일반적인 경사 하강법(Gradient Descent, GD)은 손실 함수의 그래디언트를 계산할 때 전체 데이터 세트를 사용한다
- 이에 반해 확률적 경사 하강법은 손실 함수의 경사를 계산할 때 데이터 세트에서 무작위로 선택한 하나의 샘플만을 사용한다
- 우선 미니 배치 안의 데이터에서 Loss를 계산한다
- 우리의 목표는 모델의 예측과 실제 값 사이의 차이, 즉 손실을 최소화하는 것이다
- 이를 위해 우리는 먼저 현재 모델의 파라미터로 손실을 계산한다
- 이 때 미니 배치(mini-batch)라는 작은 데이터 그룹을 사용한다
- 그리고 'Gradient의 반대 방향' 을 이용해서 파라미터 벡터를 업데이트한다
- 그래디언트가 양수라면 해당 파라미터를 증가시키면 손실이 증가하고, 그래디언트가 음수라면 해당 파라미터를 증가시키면 손실이 감소한다
- 따라서 손실을 최소화하려면 파라미터를 '그래디언트의 반대 방향'으로 업데이트 해야한다
- 이 단계를 계속 반복하면 결국 Loss가 낮아진다
SGD 특징
- 계산 효율성
- 전체 데이터 세트 대신 하나의 샘플만을 사용하기 때문에, 한 번의 반복이 더 빠르고 메모리 효율도 더 좋다
- 이는 큰 데이터 세트에서 특히 중요한 이점이다
- 불규칙한 최적화
- 확률적 경사 하강법은 무작위 샘플을 사용하기 때문에, 경사 하강법에 비해 경로가 불규칙하다
- 이는 지역 최솟값에서 벗어나는 데 도움이 될 수 있다
- 온라인 학습
- 확률적 경사 하강법은 새로운 데이터가 도착하면 즉시 업데이트를 수행할 수 있으므로, 온라인 학습에 적합하다
SGD의 문제점
Learnning rate(비효율적인 학습률)
- SGD는 학습률 파라미터에 매우 민감하다
- 너무 큰 학습률은 수렴을 방해하며, 너무 작은 학습률은 학습 속도를 느리게 만든다
- 모든 매개변수에 대해 동일한 학습률을 사용하므로, 일부 매개변수는 너무 느리게 학습되고, 다른 일부는 너무 빠르게 학습될 수 있다
- 이로 인해 학습이 불안정해질 수 있으며, 적절한 학습률을 설정하는 것은 매우 어려운 작업이다
- 이 문제는 고차원 공간에서 훨씬 더 빈번하게 발생한다. 실제로는 가중치가 수천 수억 개일 수 있다. 이 경우 gradient 방향은 수억 개의 방향으로 움직일 수 있다. 이런 수억 개의 방향 중에 불균형한 방향이 존재한다면 SGD는 잘 동작하지 않게 된다
local minima(지역 최적점)
- 손실 함수가 여러 개의 최솟값을 가질 때, 그 중에서 전체에서 가장 작은 값인 '전역 최솟값(global minimum)'이 아닌 다른 최솟값에 머무르는 상황을 말한다
- SGD는 그래디언트가 0인 곳을 찾는데, 이는 최솟값 뿐만 아니라 극대값이나 안장점에서도 발생할 수 있다
- 따라서 SGD는 비용 함수가 복잡하고 비선형일 경우 지역 최솟값에 갇히고, 더 이상 학습이 진행되지 않을 수 있다
- 이는 전역 최적점(global optimum)을 찾는 것을 방해하며, 모델의 성능을 저하시킨다
saddle point(안장점)
- 안장점은 어떤 방향에서 보면 극소점(local minimum) 같지만, 다른 방향에서 보면 극대점(local maximum)처럼 보이는 점을 말한다
- local minima는 아니지만, 한쪽 방향으로는 증가하고 있고 다른 한쪽 방향으로는 감소하고 있는 지역을 생각해보면 이런 곳에서도 gradient는 0이 된다
- 고차원 공간에서는 local minima 보다 이러한 saddle point이 많이 발생할 수 있다
- SGD는 그래디언트가 0인 지점을 찾기 때문에, saddle point에서 학습이 멈출 수 있다
- 또한 saddle point 뿐만 아니라 saddle point의 근처에서도 문제는 발생한다
- saddle point 근처에서 gradient가 0 은 아니지만 기울기가 아주 작다
- gradient를 계산해서 업데이트를 해도 기울기가 아주 작기 때문에 현재 가중치의 위치가 saddle point 근처라면 업데이트는 아주 느리게 진행된다

계산
- Loss를 계산할 때 마다 매번 전부를 계산하는 것은 어렵기 때문에 실제로는 미니배치의 데이터들만 가지고 실제 Loss를 추정하기만 한다
- 이는 매번 정확한 gradient를 얻을 수가 없다는 것을 의미한다. 대신에 gradient의 부정확한 추정값(noisy estimate) 만을 구할 뿐이다
Momentum SGD
- SGD 문제점의 대다수를 해결할 수 있는 방법이다
- 기본적인 SGD 알고리즘에 모멘텀 기법을 추가한 것이다
- 이전 스텝의 그래디언트를 고려하여 파라미터를 업데이트하는 방식을 사용한다
- 이는 마치 공이 경사면을 내려가며 가속도를 얻는 물리적 모멘텀 현상에 비유된다
- velocity를 이용해서 step을 조절을 하는데, velocity를 유지하여 gradient를 계산할 때 velocity를 이용한다. 현재 미니배치의 gradient 방향만 고려하는 것이 아니라 velocity를 같이 고려하는 것이다
- 모멘텀 방식에서는 각 단계에서 기울기에 비례하는 변화량이 속도에 더해지는데, 이를 통해 이전 단계의 기울기가 현재 단계의 업데이트에 영향을 미치게 된다. 이렇게 해서 속도는 연속적인 기울기를 모두 고려하게 되며, 이는 최적화 과정의 안정성을 높이고 학습 속도를 향상시킨다

- 하이퍼 파라미터 'rho'를 사용한다. rho는 momemtum의 비율이다
- velocity의 영향력을 rho의 비율로 맞춰주는데 보통 0.9와 같은 높은 값으로 맞춰준다
- velocity에 일정 비율 rho를 곱해주고 현재 gradient를 더해준다
- 이를 통해서 이제 gradient vector 그대로의 방향이 아닌 velocity vector의 방향으로 나아가게 된다
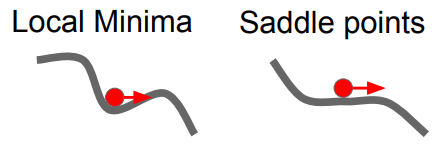
- local minima와 saddle points 문제를 momemtum이 어떻게 해결하는지 이해하려면 물리적으로 공이 굴러내려오는 것을 상상해보면 된다
- 이 공은 떨어지면 속도가 점점 빨라진다
- 이 공은 local minima에 도달해도 여전히 velocity를 가지고 있기 때문에 gradient = 0 이라도 움직일 수 있다
- saddle points에서도 비슷한 일이 일어난다
- saddle point 주변의 gradient가 작더라도, 굴러내려오는 속도가 있기 때문에 velocity를 가지게 된다. 때문에 saddle point를 잘 극복해 내고 계속 밑으로 내려올 수 있다
Nesterov accelerated gradient(Nesterov momentum)
- 계산하는 순서를 조금 바꿔 모멘텀 방법을 개선한 방법이다
- 기존 모멘텀 방법은 "공"이 경사면을 내려가면서 속도를 높이는 물리적인 모멘텀 원리를 모방한 것이다. 그러나 기본 모멘텀 방법의 한계점은, "공"이 최적점을 지나칠 수 있다는 것이다
- 이는 공이 너무 빠르게 이동하여 최적점을 지나쳐 버리고, 이후에 다시 되돌아오는 과정을 반복하게 된다
- Nesterov 모멘텀은 이 문제를 해결하기 위해, 그래디언트를 계산할 위치를 미리 "조정"하는 아이디어를 도입한다
- 즉, 매개변수를 업데이트하기 전에 모멘텀만큼 "이동"시킨 후 그 위치에서 그래디언트를 계산한다
- 이렇게 하면, "공"이 너무 빠르게 이동하여 최적점을 지나치는 것을 더 잘 제어할 수 있다
- 기본 SGD momentum은 "현재 지점"에서의 gradient를 계산한 뒤에 velocity와 섞어준다
- Nesterov를 사용하면 방법이 조금 다르다. 현재 지점에서 시작해서 우선은 Velocity방향으로 움직인다. 그리고 그 지점에서의 gradient를 계산한다. 마지막으로 다시 원점으로 돌아가서 둘을 합치는 것이다. velocity의 방향이 잘못되었을 경우에 현재 gradient의 방향을 좀 더 활용할 수 있도록 해준다
- 정리하자면, 기본 모멘텀 방법은 현재 위치에서의 기울기를 바탕으로 과거의 기울기 방향으로 이동하는 반면, NAG는 과거의 기울기 방향으로 먼저 조금 이동한 후 그 위치에서의 기울기를 계산한다. 이를 통해 미래의 위치를 조금 더 정확하게 예측하고, 이에 따라 업데이트를 수행한다
- NAG는 이런 방식으로 기울기의 변동을 더 잘 반영하며, 이를 통해 최적화 과정의 안정성을 더욱 높이고 학습 속도를 향상시킨다
- 특히, 안장점(saddle point)이나 기울기가 크게 변하는 지점 등에서의 성능이 뛰어나다
- Nesterov는 Convex optimization 문제에서는 뛰어난 성능을 보이지만 Neural network와 같은 non-convex problem 에서는 성능이 보장되지는 않는다
- esterov의 수식은 다음과 같다
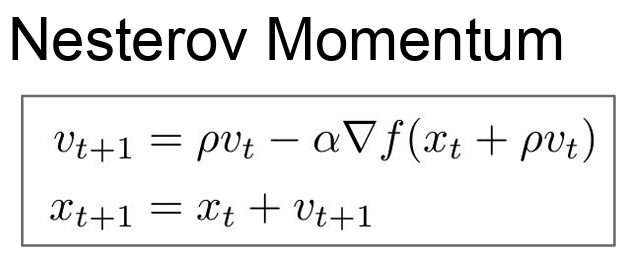
- velocity를 업데이트하기 위해서 이전의 velocity와 (x + pv)에서의 gradient를 계산한다. 그리고 step update는 앞서 계산한 velocity를 이용해서 구해준다

- 변수들을 적절히 잘 바꿔주면 Nesterov를 조금 다르게 표현할 수 있으며 Loss와 Gradient를 같은 점에서 계산할 수 있게 된다
- 그리고 수정된 수식을 통해서 우리는 Nesterov를 새롭게 이해해 볼 수 있다
- 첫 번째 수식은 기존의 momentum과 동일하다
- 기존과 동일하게 velocity 와 계산한 gradient를 일정 비율로 섞어주는 역할을 한다
- 두 번째로 맨 밑의 수식을 보면 우선 현재 점과 velocity를 더해 준다. 여기 까지는 기존과 동일하다
- 그리고 여기에 "현재 velocity - 이전 velocity" 를 계산해서 일정 비율(rho)을 곱하고 더해준다
- Nesterov momentum는 현재/이전의 velocity간의 에러보정(error-correcting term)이 추가됐다
AdaGrad(Adaptive Gradient Algorithm)
- 기본적인 경사 하강법은 모든 매개변수에 대해 동일한 학습률을 사용한다
- 이는 모든 매개변수가 동일한 속도로 학습되어야 한다는 가정을 내포하고 있다
- 실제로는, 각 매개변수는 서로 다른 속도로 학습되는 것이 더 효과적일 수 있다
- AdaGrad은 그래디언트의 크기에 따라 학습률을 조정하게 된다
- 특히, 각 매개변수에 대해 그래디언트의 제곱합의 루트를 나누어주는 방식으로 학습률을 조정한다
- 이렇게 하면, 자주 업데이트되는 매개변수의 학습률은 낮아지고, 적게 업데이트되는 매개변수의 학습률은 높아진다
- 따라서, AdaGrad는 각 매개변수에 대해 개별적으로 학습률을 조정하면서 최적화를 수행하게 된다
- 이 방법은 희소한 데이터에서 잘 작동하는 경향이 있다
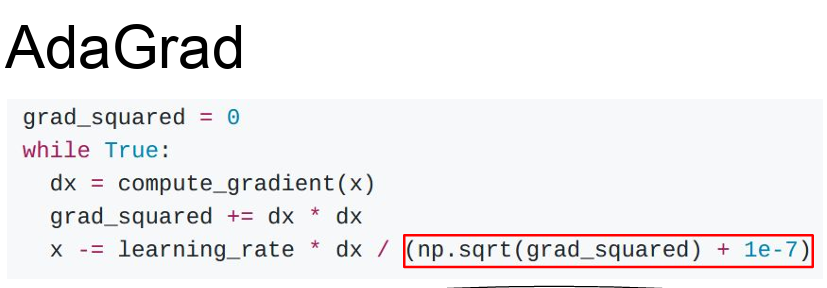
- AdaGrad는 훈련도중 계산되는 gradients를 활용하는 방법이다
- Adagrad는 velocity term 대신에 grad squared term을 이용한다
- 그리고 학습 도중에 계산되는 gradient에 제곱을 해서 계속 더해준다
- Update를 할때 Update term을 앞서 계산한 gradient 제곱 항으로 나눠준다
문제점
- 학습률 감소 속도 문제
- AdaGrad는 학습이 진행됨에 따라 학습률이 계속 감소하는데, 이는 긴 학습 기간 동안 학습률이 과도하게 작아져서 학습이 느려지거나 멈추는 문제를 일으킬 수 있다
- 즉, 모델 학습이 진행될 때 학습이 잘 이루어져 더 이상 변수의 값이 업데이트되지 않는 것인지, 값이 지나치게 커져서 추가적으로 학습이 되지 않는 것인지 알기 어렵다는 한계가 있다
- 적응적 학습률 조정 문제
- AdaGrad는 각 파라미터에 대해 개별적으로 학습률을 조정하지만, 이는 최적의 솔루션을 찾는 데 방해가 될 수 있다
- 특히, 모든 파라미터에 대해 동일한 학습률을 사용하는 것이 더 좋은 결과를 내는 경우도 있다
RMSProp
- AdaGrad 알고리즘의 단점을 보완하기 위해 제안된 방법
- RMSProp은 가장 최근에 계산된 그래디언트만을 사용하여 학습률을 조정한다
- 이는 '지수 가중 이동 평균(Exponential Weighted Moving Average)'라는 기법을 사용하여 구현된다
- 이 방식을 사용하면, 학습 초기에는 빠르게 학습률을 감소시키되, 학습이 오래 진행될수록 학습률 감소 속도가 줄어들어 학습이 지속적으로 이루어질 수 있게 된다

- RMSProp에서는 AdaGrad의 gradient 제곱 항을 그대로 사용한다
- 하지만 이 값들을 그저 누적만 시키는 것이 아니라 기존의 누적 값에 decay_rate를 곱해준다
- 이 값은 기존의 momentum 수식과 유사하게 생겼다
- 다만 gradients의 제곱을 계속해서 누적해 나간다
- RMSProp에서는 gradient 제곱 항에 쓰는 decay rate는보통 0.9 또는 0.99정도를 자주 사용한다
- 그리고 '현재 gradient의 제곱'은 (1 - decay rate) 를 곱해줘서 더해준다
- RMSProp은 gradient 제곱을 계속 나눠준다는 점에서 AdaGrad와 유사하다
- 이를 통해 step의 속도를 가속/감속 시킬 수 있다
Adam 알고리즘
- Adam은 RMSProp와 Momentum 방법을 결합한 알고리즘이라고 볼 수 있다
- Adam은 각 파라미터에 대해 그래디언트의 제곱을 평균내어 학습률을 조절하는 RMSProp의 방식과, 과거 그래디언트의 지수 가중 평균을 이용하는 Momentum 방식을 모두 사용한다

- Adam은 first moment와 second moment을 이용해서 이전의 정보(estimate)를 유지시킨다
- first moment는 gradient의 가중 합이다
- second moment는 AdaGrad이나 RMSProp처럼 gradients의 제곱을 이용하는 방법이다
- Adam으로 Update를 진행하게 되면 우선 first moment는 velocity를 담당한다. 그리고 sqrt(second moment)를 나눠주는데 second moment는 gradient의 제곱 항이다
- Adam은 momentum + second squared gradients 이다
- 이 두 종류의 유용한 특징을 모두 이용하는 것이다
- 초기에 second moment를 0으로 초기화한다
- Adam 알고리즘은 모멘텀 최적화가 과거 기울기의 지수 가중 평균을 유지하는 것처럼, Adam도 과거 기울기의 지수 가중 평균을 유지한다. 그러나 Adam은 과거 기울기의 제곱의 지수 가중 평균도 유지한다
- 이는 RMSProp에서 볼 수 있는 개념으로, 이를 통해 각 매개변수에 대한 학습률을 독립적으로 조정한다
- 따라서 Adam은 모멘텀 최적화의 관성 효과와 RMSProp의 학습률 조정 기능을 모두 가지며, 이를 통해 뛰어난 성능을 보인다
주요 장점
- 적응적 학습률 조정
- Adam은 각 파라미터에 대한 학습률을 독립적으로 조정한다
- 이는 특정 파라미터가 자주 업데이트되지 않거나 그래디언트가 작은 경우, 그 파라미터의 학습률을 증가시켜 학습을 가속화하는 데 도움이 된다
- 모멘텀 활용
- Adam은 과거 그래디언트의 정보를 활용하여 파라미터 업데이트의 방향과 크기를 조절한다
- 이는 지역 최적해(local minimum)나 평편한 영역(saddle point)에서 벗어나는 데 도움이 된다
-하이퍼파라미터 튜닝의 용이성 - Adam은 학습률 등의 하이퍼파라미터에 대해 상대적으로 민감하지 않다
- 따라서, 다른 최적화 알고리즘에 비해 하이퍼파라미터 튜닝이 덜 필요하다
문제점
- 초기에 second moment를 0으로 초기화한다
- second moment를 1회 Update하고 난 후를 생각해보자
- beta2는 decay_rate로 0.9또는 0.99로 1에 가까운 값이다. 그렇기 때문에 1회 업데이트 이후에도 second moment는 여전히 0에 가깝다
- update step에서 second moment로 나누게 되는데 나눠주는 값이 크기 때문에 초기 step이 엄청나게 커지게 된다
- 중요한 것은 이 커진 step이 실제로 손실함수가 가파르기 때문(geometry)이 아니라는 것이다
- 이 값은 second moment을 0으로 초기화 시켰기 때문에 발생하는 '인공적인' 현상이다
해결책
- Adam은 초기 Step이 엄청 커져 버릴 수 있고 이로 인해 잘못될 수도 있다
- 이를 해결하기 위해 보정하는 항(bias correction term)을 추가한다
- first/second moments를 Update하고 난 후 현재 Step에 맞는 적절한 unbiased term 을 계산한다
- bias correction term을 추가하면 다양한 문제에도 잘 동작한다
- 특히나 beta_1 = 0.9, beta_2 = 0.999로 설정하고 Learning rate를 E-3나 E-4 정도로만 설정해 놓으면 거의 모든 아키텍쳐에서 잘 동작하는 기본 설정으로 아주 제격이다
Learning rates decay
- 학습률 관리 전략 중 하나이다
- 이 전략은 학습이 진행됨에 따라 학습률을 점차 감소시키는 방법을 말한다
- 각각의 learning rates의 특성을 적절히 이용하는 방법이다
- 처음에는 learning rates를 높게 설정한 다음에 학습이 진행될수록 learning rates를 점점 낮추며 진행한다
- 가령 100,000 iteration에서 learning rates를 낮추고 학습시키는 방법(step decay) 혹은 exponential decay 처럼 학습과정 동안에 꾸준히 learning rate를 낮추는 방법도 있다
- learning rate decay는 Adam 보다는 SGD Momentum을 사용할 때 자주 사용한다
- 한 가지 유념해야 할 점은 learning rate decay는 부차적인(second-order) 하이퍼파라미터 라는 것이다
- 일반적으로 learning-rate decay를 학습 초기부터 고려하지는 않는다
- 보통 학습 초기에는 learning rate decay가 없다고 생각하고 learning rate를 잘 선택하는 것이 중요하다
- learning rate와 dacay 등을 cross-validate(교차검증) 하려고 한다면 문제가 너무 복잡해진다
- learning rate decay를 설정하는 순서
- 우선 decay 없이 학습을 시켜본다
- 그리고 Loss curve를 잘 살피고 있다가 decay가 필요한 곳이 어디인지 고려해 보는 것이 좋다
장점
- 초기의 빠른 학습
- 학습 초기에는 학습률이 높기 때문에, 모델은 빠르게 학습하고 큰 틀에서 최적의 파라미터 방향으로 빠르게 이동한다
- 학습 후반의 안정화
- 학습이 진행됨에 따라 학습률이 점차 감소하므로, 학습 후반에는 학습률이 낮아져 파라미터의 업데이트가 더욱 세밀해진다
- 이를 통해 모델은 최적의 솔루션에 더욱 가까이 다가갈 수 있다
First-Order Optimization
- 함수의 1차 미분(그래디언트)만을 사용하여 최적의 해를 찾는 방법을 의미한다
- 이 방법은 함수의 그래디언트를 계산하고, 그래디언트의 반대 방향으로 파라미터를 업데이트함으로써 함수의 값을 점진적으로 감소시키는 방식으로 작동한다
- 이러한 과정은 반복적으로 수행되며, 그래디언트가 0인 지점, 즉 함수의 최소값에 도달할 때까지 이루어진다
Second-Order Optimization
- 함수의 1차 미분(그래디언트) 뿐만 아니라 2차 미분(헤시안)을 사용하여 최적의 해를 찾는 방법을 의미한다
- 2차 최적화 방법은 함수의 곡률을 고려하여 더욱 효율적인 방향으로 업데이트를 수행한다
- 이는 각 단계에서의 업데이트 방향과 크기를 더욱 정확하게 조절할 수 있기 때문에, 일반적으로 더 빠른 수렴 속도를 보인다
Newton's Method
- 함수의 극값(최대값 또는 최소값)을 찾는 방법으로, gradient(1차 미분) 뿐만 아니라 Hessian matrix(2차 미분값들로 된 행렬)를 사용하여 함수의 곡률을 고려한다
- Hessian matrix의 역행렬을 이용하게 되면 실제 손실함수의 2차 근사를 이용해 minima로 곧장 이동할 수 있을 것이다
- 이 알고리즘이 다른 Optimization 알고리즘에 비해 특이하다고 할 수 있는 점은 바로 Learning rate가 없다는 점이다
- Newton's Method는 learning rate이 없이도 매 step마다 항상 minma를 향해 이동한다
- 하지만 실제로는 learning rate가 필요하다. 2차 근사도 사실상 완벽하지 않다. minima로 이동하는게 아니라 'minima의 방향'으로 이동하기 때문이다
- Newton's Method는 Deep learning에서는 사용할 수 없다. 왜냐하면 Hessian matrix는 N x N 행렬이다. N은 Network의 파라미터 수이다. N이 1억이면 1억의 제곱만큼 존재할 것이다. 이를 메모리에 저장할 방법은 없으며 또한 역행렬계산도 불가능 할 것이다. 그래서 실제로는 'quasi-Newton methods'를 이용한다
수행 단계
- 임의의 시작점을 선택한다
- 현재 점에서의 함수의 기울기와 곡률을 계산한다
- 이 정보를 사용하여 함수의 최소값이 있을 수 있는 다음 점으로 이동한다
- 이 과정을 최소값을 찾을 때까지 반복한다
Quasi-Newton Methods
- Quasi-Newton Methods는 헤시안 행렬의 근사치를 사용한다
- 이전 단계에서 계산한 정보를 활용하여, 헤시안 행렬의 근사치를 업데이트한다
- 이런 방식으로, 2차 미분의 계산 없이도 Newton's Method와 유사한 성능을 달성할 수 있다
- Quasi-Newton Methods는 Full Hessian을 그대로 사용하기 보다 근사시킨다
- Low-rank approximations 하는 방법이다
- Quasi-Newton Methods 중 가장 널리 사용되는 방법은 BFGS(Broyden-Fletcher-Goldfarb-Shanno) 방법과 그 변형인 L-BFGS(Limited-memory BFGS) 방법이다
- L-BFGS은 사실상 DNN에서는 잘 사용하지 않는다. 왜냐하면 L-BFGS에서 2차근사가 stochastic case에서 잘 동작하지는 않기 때문이다. 그리고 L-BFGS는 non-convex problems에도 적합하지 않다
- 하지만 full batch update가 가능하고 stochasticity이 적은 경우라면 L-BFGS가 좋은 선택이 될 수 있다
- L-BFGS가 Neural network를 학습시키는데 그렇게 많이 사용되지는 않지만 Sytle tranfer와 같은 알고리즘에 종종 사용할 수 있다
Model Ensembles
- 여러 개의 학습 모델을 결합하여 보다 높은 성능을 달성하는 기법을 말한다
- 각 모델의 예측을 종합함으로써 단일 모델의 한계를 극복하고, 일반화 성능을 향상시키는데 도움이 된다
-손실함수 최적화를 이미 모두 끝마친 상황에서 '한번도 보지 못한 데이터' 에서의 성능을 올리기 위해서 사용된다 - Machine learning 분야에서 종종 사용하는 기법이다
- 아이디어는 아주 간단하다. 모델을 하나만 학습시키지 말고 10개의 모델을 독립적으로 학습시키는 것이다
- 결과는 10개 모델 결과의 평균을 이용한다
- 모델의 수가 늘어날수록 overfitting 줄어들고 성능이 조금씩 향상된다. 보통 2%정도 증가한다
- 조금 더 창의적인 방법도 있다. 모델을 독립적으로 학습시키는 것이 아니라 학습 도중 중간 모델들을 저장(sanpshots)하고 앙상블로 사용할 수 있다. 그리고 Test time에는 여러 snapshots에서 나온 예측값들을 평균을 내서 사용한다. 이런 snapshots은 Training 과정 중간에 저장한다
- 좀 더 향상된 앙상블 알고리즘도 있다
- 이 방법은 아주 독특한 Learning rate 스케줄을 이용한다. Learning rate를 엄청 낮췄다가 다시 엄청 높혔다가를 반복한다. 이런 방식으로 손실함수에 다양한 지역에 수렴할 수 있도록 만들어 준다
- 또 다른 방법으로는 학습하는 동안에 파라미터의 exponentially decaying average를 계속 계산한다
- 이 방법은 학습중인 네트워크의 smooth ensemble 효과를 얻을 수 있다
- checkpoints에서의 파라미터를 그대로 쓰지 않고 smoothly decaying average를 사용하는 방법이다. 이를 Polyak veraging라고 합니다. 때때로 조금의 성능향상을 보일 수 있다
모델 앙상블의 세 가지 기법
- 배깅(Bagging)
- 배깅은 복원 추출(Bootstrap Aggregating)을 통해 여러 개의 다른 학습 데이터 세트를 생성하고, 이를 각각의 모델에 학습시키는 방법이다
- 각 모델의 예측 결과를 투표(voting) 또는 평균(averaging)하여 최종 예측을 결정한다
- 랜덤 포레스트(Random Forest)는 배깅의 대표적인 예이다
- 부스팅(Boosting)
- 부스팅은 약한 학습기(Weak Learner)를 순차적으로 학습시키면서, 이전 학습기가 잘못 분류한 샘플에 가중치를 더 주는 방법이다
- 이렇게 학습된 모델들을 결합하여 최종 예측을 수행한다
- 에이다부스트(AdaBoost)나 그래디언트 부스팅(Gradient Boosting) 등이 부스팅의 예이다
- 스태킹(Stacking)
- 스태킹은 여러 개의 다른 모델을 학습시킨 후, 그들의 예측을 입력으로 받아 최종 예측을 수행하는 '메타 학습기(Meta Learner)'를 학습시키는 방법이다
출처 및 참조

공부 기록