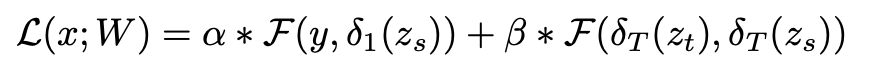
리뷰가 길어져 나누어 작성하였습니다.
1. Deep Compression
이전 게시물에서 Deep Compression의 Pruning에 대해 리뷰하였습니다.
지금부터는 Quantization, 양자화에 대해 리뷰하겠습니다.
1. Quantization(양자화)
동일한 수준의 정확도를 유지하면서
full-precision(FP32)의 weights 및 activations를
low-precision(예: FP16, INT8, 바이너리)로 인코딩하는 것.
- 초기 연구에서 FP16을 사용하여 DNN 모델을 train하는 것이 정확도를 유지하면서 computational cost를 낮춘다는 것을 보여줬습니다.
질문
-
off-chip 메모리 접근으로 발생한 높은 오버헤드를 완화할 수 있도록 전체 모델을 edge devices의 on-chip 메모리에 맞출 수 있습니다.
-
low-bit representation을 사용하는 작업은 일반적으로 더 적은 에너지를 소비하고 더 빠르게 실행되기 때문에, Quantization은 에너지 소비와 지연 속도까지도 줄여줍니다.
-
앞선 연구에서는 weights와 activation을 동일한 low-bit로 만들었는데, 요즘 하드웨어나 가속기들은
mixed precision 연산을 제공합니다.
예를 들어, Nvidia Turing GPU 아키텍처는 1-bit, 4-bit, 8-bit, 16-bit 산술 연산을 지원합니다.
-> 더 효율적이고 flexible한 방법으로 weight와 activation을 양자화 할 수 있게 됨
HAQ : 하드웨어 인식 자동 양자화 접근 방식
- HAQ는 강화 학습을 활용하여 대상 하드웨어의 각 레이어에 대해 서로 다른 양자화 폭을 선택합니다.
- 또한 하드웨어 아키텍처는 학습 루프에 관여하여, 바로 inference latency와 에너지를 줄여줍니다.
- HAWQ 또한 비슷한 방식으로 양자화하는데, 여기서 양자화된 정밀도는 헤시안 행렬을 기준으로 각 레이어에 대해 결정됩니다.
몇몇 연구에서는 binary나 ternary 양자화를 사용하여 DNN model 압축을 최대화합니다.
- 그렇게 만들어진 network들은 binary 또는 ternary 네트워크는 전용 하드웨어의 효율성을 높이기 위해 저렴한 비트 연산을 사용할 수 있습니다.
Courbariaux et al 이 제시한 binaryconnect.
-
full-precision weight를 binary 형태로 바꾼 것.
-
간단한 이진화 방법 사용
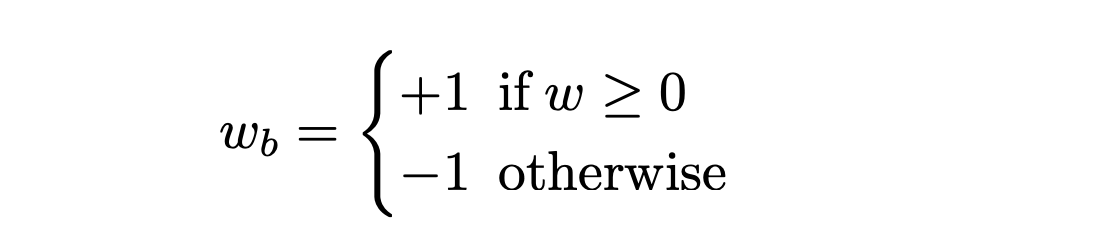
-
Wb = binary weight
-
W = full-precision
-
질문 위와 같은 방식은 hidden units의 많은 입력 가중치에 대한 이산화 평균은 정보 손실을 보상할 수 있습니다.
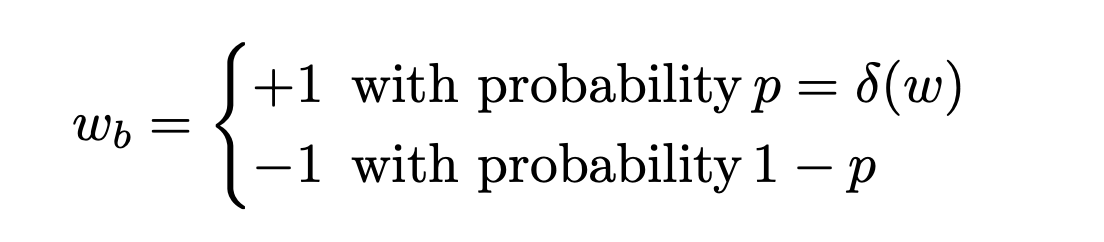
- 이에 대한 대안으로, 보다 미세하고 정확한 평균화 프로세스를 수행할 수 있게 확률적으로 이진화하는 것으로, 모델 일반화 기능을 개선하는 데 도움이 됩니다.
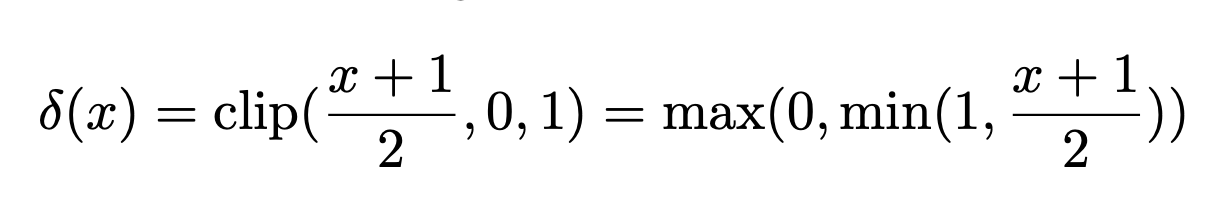
- Hard sigmoid를 사용하여 확률적으로 이진화합니다.
이러한 binarizd 방법은 모델 성능을 크게 저하시키는 매우 이산적인 매개 변수 공간으로 인해 훈련 프로세스가 수렴되기 어려울 것입니다.
나중에, Rastegari 등은 전체 정밀 가중치를 직접 반올림하는 대신 +1과 -1로 제한하는 효율적인 근사 전략을 제시합니다.
양자화 생략...
2. Knowledge Distillation
지식 증류 기법은 compact한 student model이 복잡하고 강력한 teacher model로부터 knowledge을 학습하는 방법입니다.
-
지식 증류 기법은 Bucila가 처음 제시하였고, Hinton이 일반화하여 DNN들에 적용하였습니다.
-
student model은 일반적인 training 방식인 one-hot 분류 기법을 사용하여 학습하는데, 이를 hard targets라고 합니다.
(ex [0,0,1,0] ) -
teacher model의 knowledge는 soft target 방식인 [0.1,0.21,0.6,0.09]와 같은 방식으로 student model에게 증류되고 이동합니다.
-
즉, 이렇게 출력값의 확률이
지식이 된다고 말하고 있습니다. -
그럼에도 불구하고, 1에 가장 가까운 correct class가 확률 분포를 지배해버리는 문제점이 있기 때문에,
softmax temperature를 사용합니다. -
temperature T는 더
soft하게 만들어주는 것입니다. 높은 T는 더욱 더 soft하게 만들어줍니다.
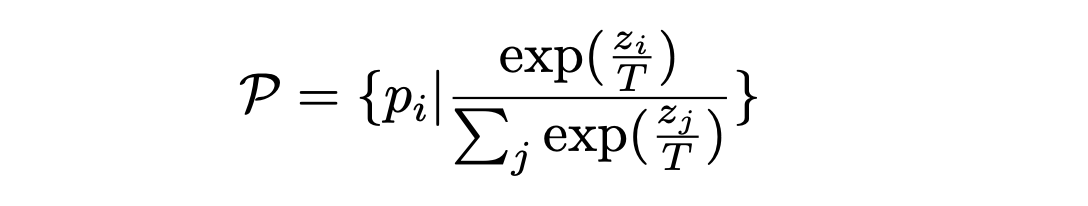
- 위의 식이 softmax temperature 함수입니다. T=1일 때, 일반적인 softmax 함수입니다.
지식 증류 방법
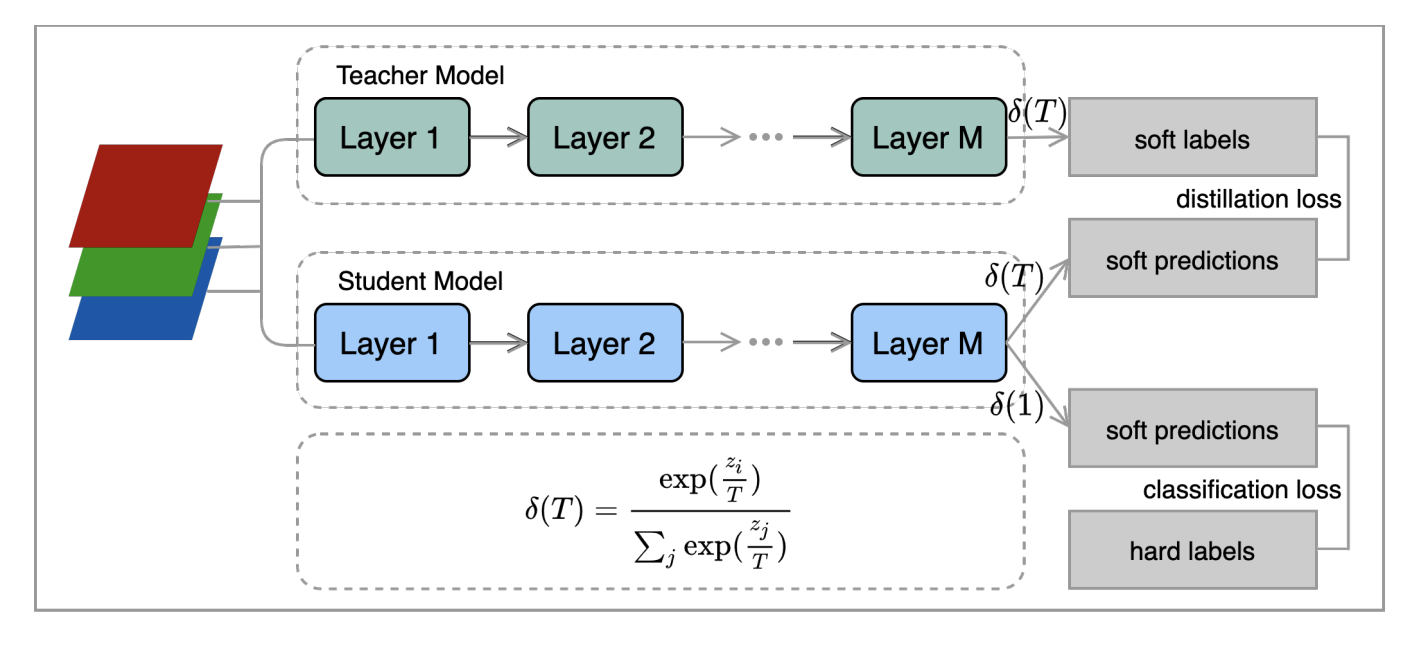
-
큰 모델을 학습 시킨 후, 작은 모델을 손실함수를 통해 학습시킵니다.
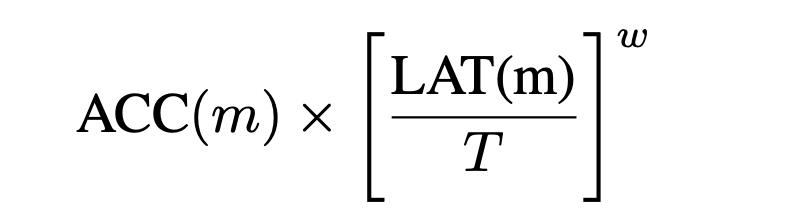
-
위의 식이 Knowledge Distillation의 손실함수입니다.
위의 작업들은 teacher model의 Output layer부분의 지식만을 사용하였지만,
Remero는 FitNets라는 Compact model을 train하는 지식 증류 기법을 사용하였습니다.
FitNets의 메인 아이디어는 얕고 넓은 teacher model에서 깊고 얇은 student model에게 지식을 전달하는 것입니다.
다른 작업과의 다른 점이라면, 마지막 teacher model의 output layer만을 사용하는 것이 아니라 중간의 feature representations 또한 사용한다는 점입니다.
3. Hardware-aware NAS
모델 압축은 edge devices를 위해 'large-to-small' 방법을 제공하여 복잡한 모델을 효율적이고 작은 모델로 만들어줍니다.
비록 이것이 지연 속도와 모델 크기를 줄여주지만, pre-trained 모델보다 더 정확해질 순 없습니다.
(줄인다고 해도, 줄이기 전의 모델보다 정확도가 높아질 순 없음)
또한, AutoML은 날이 갈수록 발전하고 있습니다.
그래서 이러한 질문이 제기됩니다.
NAS는 하드웨어 효율적이고 정확한 신경 아키텍처를 직접 설계할 수 있을까?
Tan 은 hardware-aware NAS 프레임 워크를 제안했는데, 그것은 MnasNet입니다.
MnasNet에서 지연 시간과 정확성은 강화 학습 알고리즘의 reward function로 공식화되며, 지연 시간은 대상 모바일 장치에서 직접 측정됩니다.
- 위의 식이 reward 입니다.
- ACC(m)에서 m = 얻은 network
- T = 지연 기대값
- w = 보상에서 대기 시간의 가중치를 조정하는 변수
- ACC = accuracy
- LAT = latency
4. Adaptive Models
앞의 섹션들에서는 고정된 DNN 모델에 대해서만 설명하였습니다.
그러나, run-time 중에, DNN applications는 computational units와 communication bandwidth을 다른 application들과 공유하면서 결과적으로 computing과 communication 자원의 유용성이 DNN의 infercne time에 상당한 영향을 끼친다.
또한, 배터리에 의존하는 edge system들은 energy variance가 frequency를 scailing down하거나 DNN application의 inference time에 영향을 주는 power와 같은 시스템의 상태를 바꿉니다.
이러한 variance들은 QoS에 영향을 끼칩니다.
여기에 우리는 5가지의 adaptive model이 있습니다.
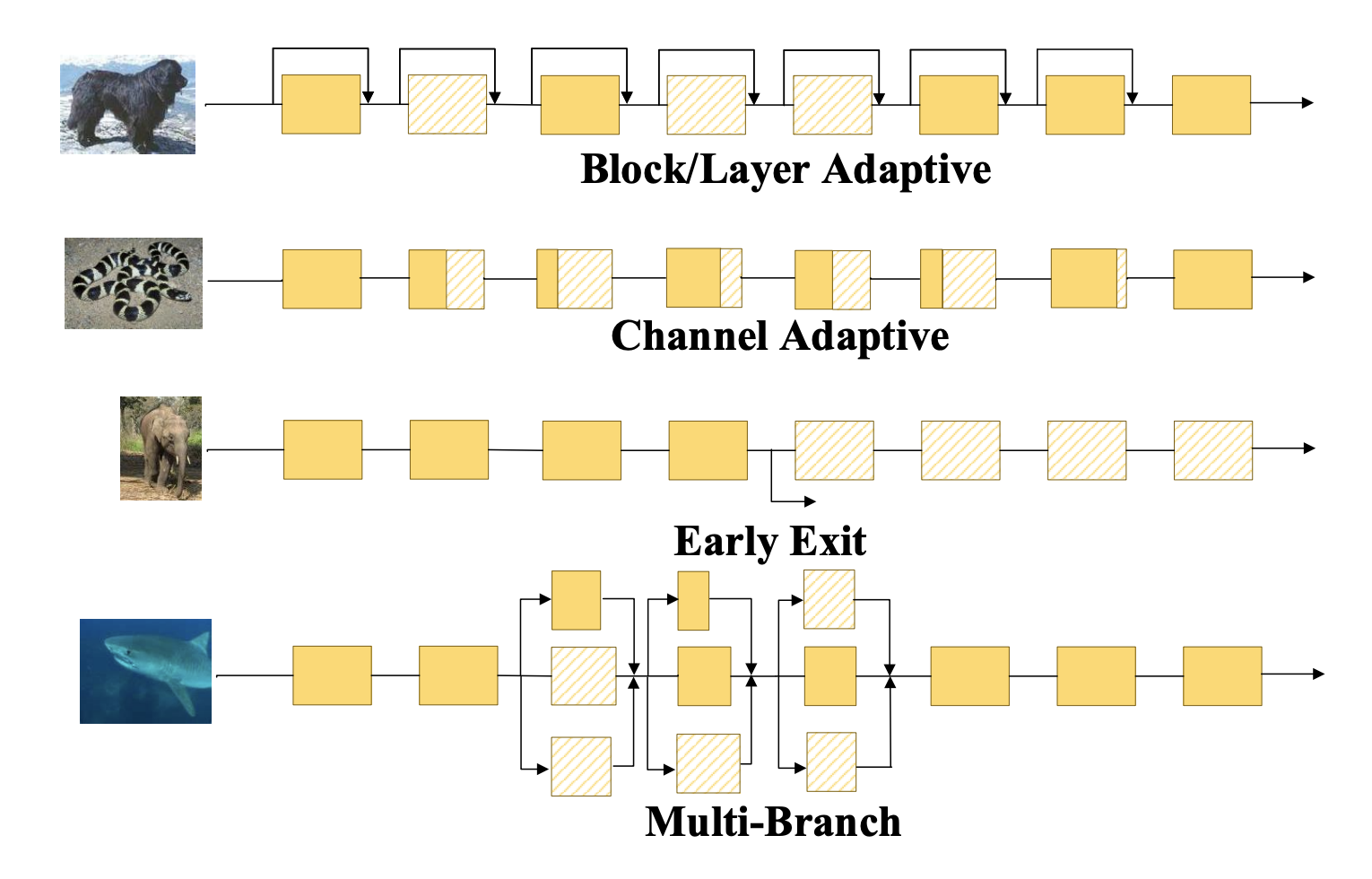

⬆️ Attention
- Block/Later Adaptive : blocks/layers의 부분을 선택하여 DNN inference 실행
- Channel Adaptive : 각 layer에서 channel의 일부분을 통해 DNN inference 실행
- Early Exit : 중간의 결과를 사용하고 나머지 layer들을 skip
- Multi-branch: 다양한 kernel을 통해 특징을 추출하며 kernel의 조합을 사용하여 DNN inference 실행
- Attention : 이 방법은 Attention 메커니즘
을 사용하여 이미지의 중요한 공간 위치를 찾고 이러한 영역에서 계산 비용이 많이 드는 컨볼루션만 수행합니다.
