이번에는 Bringing AI to Edge라는 논문에 대해 리뷰해보겠습니다.
논문 링크 : https://arxiv.org/abs/2011.14808
1. Introduction
- 2012년 Alexnet이 Imagenet Contest에서 10% 이상의 차이로 우승
- 이후, 더 복잡할수록 높은 정확도가 나타난다는 것을 알게 됨.
- 그러나, 훈련 과정에서 많은 계산과 시간 소요, 환경적 문제(CO2) 등이 있음
(ResNet50은 imageNet training하는 데 29시간 걸림) - 많은 회사에서 DNN inference를 서버를 통해 해결함.
- 그러나 자율주행과 같은 분야에서 클라우드를 통한 DNN inference는 반응성에 대한 어려움, 보안 관련 어려움이 있음
그 결과,Edge Computing이라는 것이 나타나게 됨.
Edge Computing을 위해서는 하드웨어의 자원 한계 속에서 DNN 모델을 사용할 수 있어야 하는데, 이 하드웨어의 resource 한계와 DNN 모델의 사이즈의 차이를 Computational Gap이라고 합니다.
Computational Gap 을 줄이기 위한 하드웨어적 발전
- ASICs
- TPU
- DianNao familiy
- ESE
등의 accelerator 개발
-> 너무 많은 비용이 초래되고, 호환성 문제가 생김
Computational Gap 을 줄이기 위한 소프트웨어적 발전
- light-weight DNN Model Design
: 모델 디자인을 작게 만드는 방법 - Model Compression
: 만들어진 모델을 줄이는 방법 - NAS
: AutoML을 사용하여 자동으로 최적의 모델을 만드는 방법
2. [ Light-weight Network Design ]
이 문단에서는 Hand-Craft models 들을 classification 과 object-detection, 이 2가지 주요 카테고리에 따라 나누어 설명합니다.
< Classification 관점 >
1) SqueezeNet
squeezeNet은 새로운 computational module이 있는데, 바로 Fire-module 입니다.
squeeze layer + expand layer => Fire-module를 사용- squeeze layer는 1X1 conv filter를 사용 ( 파라미터가 기존 3X3에 비해 9배 감소 )
- expand layer는 1X1 conv filter 와 3X3 conv filter 같이 있음.
(squeeze layer의 채널 수를 통해 expand layer의 3X3 conv filter에 들어올 채널 수를 줄여줄 수 있습니다.) - AlexNet과 같은 수준의 정확도를 달성하면서 model 복잡도는 낮춤.
2) MobileNet
- Depth-wise separable convolution 사용
- Depthwise convolution 과 Pointwise convolution를 합친 것
Depthwise convolution
: Feature map의 채널마다 각기 다른 커널 사용 => 출력 채널 수 = 입력 채널 수Pointwise convolution
: 1X1 conv 사용으로, 필터 수를 줄여줌
3) ShuffleNet
- group convolution 사용
- channel shuffle을 통해 계산량을 줄이고 높은 정확도 달성.
4) EfficientNet
Compound Model Scailing- Channel 늘리기 (Width), Layer 쌓기 (Depth), Input size 키우기 (Resolution)을 종합하여 모델 확장.
< Object Detection 관점 >
one-stage methods와two-stage methods가 있음.
one-stage methods : object classification과 localization을 한번에 하는 방법
- YOLO, SSD
two-stage methods : 입력 이미지를 먼저 특징 추출을 한 뒤 (classification), localize를 하는 방법.
- RCNN, Fast RCNN, Faster RCNN
Object Detection에서 backbone(입력 이미지 -> 특징 추출) 부분의 computational complextiy를 줄이기 위한 방법이 있는데, Tiny-dsod, Tiny-SSD, Tiny-YOLO 와 같은 방식입니다.
다른 방법으로는, SSD framework에 MobileNet, ShuffleNet, SqueezeNet과 같은 light-weight CNN을 결합하는 것입니다.
3. [ Network Compression ]
Network Compression은
over-parameterized network의 redundancy를 제거하여 모델을 경량화하는 방법입니다.
1) network pruning
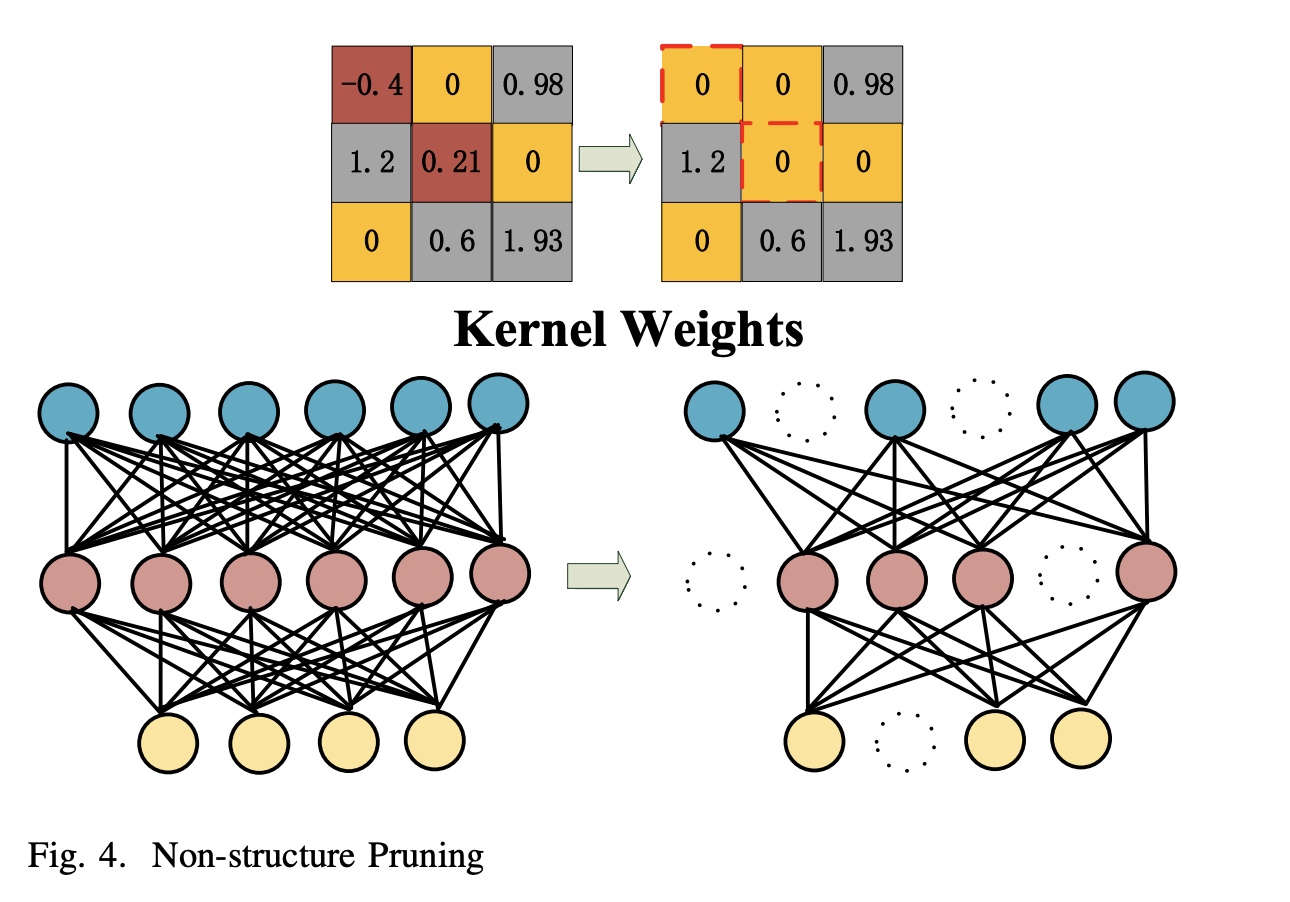
- Non-Structure Pruning
- weight pruning과 같은 의미.
- 위의 그림처럼, 관련 없는 가중치를 제거하는 방법
- kernel의 값을 지우거나, full-connected layer에서의 뉴런을 제거
- Non-Structure Pruning은 상당히 많은 수의 파라미터와 메모리 사용량을 줄일 수 있습니다.
Non-Structure Pruning은 memory-footprint와 MACs를 줄여주지만, 이러한 감소가 직접적인 latency 개선이 이루어지는 것은 아닙니다.
질문
그 이유는 Non-Structure Pruning은 sparse structure를 만들기 때문에 irregular access pattern이 되기 때문입니다.
이러한 DNN 모델의 irregular pattern은 compressed sparse row와 compressed sparse column과 같은 특별한 형식이 필요한데, 희소행렬을 저장하기 위함입니다.
- Structure Pruning
- Structure Pruning은 regular pattern을 유지하면서 pruning을 합니다.
- regularity 유지를 위해, 모델의 예측과 관련없는 필터와 채널을 완전히 지워버립니다.
- Structure Pruning에 의해 제거되는 compressed Network는 전문 소프트웨어 라이브러리 지원 없이 off-the-shelf hardware 플랫폼에서 inference를 직접 가속화할 수 있습니다.
- structure pruning의 프로세스
- (1) pruning 기준을 정의.
- (2) 압축 비율 및 MAC 또는 FLOP 수와 같은 기준과 목표에 따라 pruning 된 채널을 선택.
- (3) pruned model을 미세 조정 후, Retrain하여 정확도 유지.
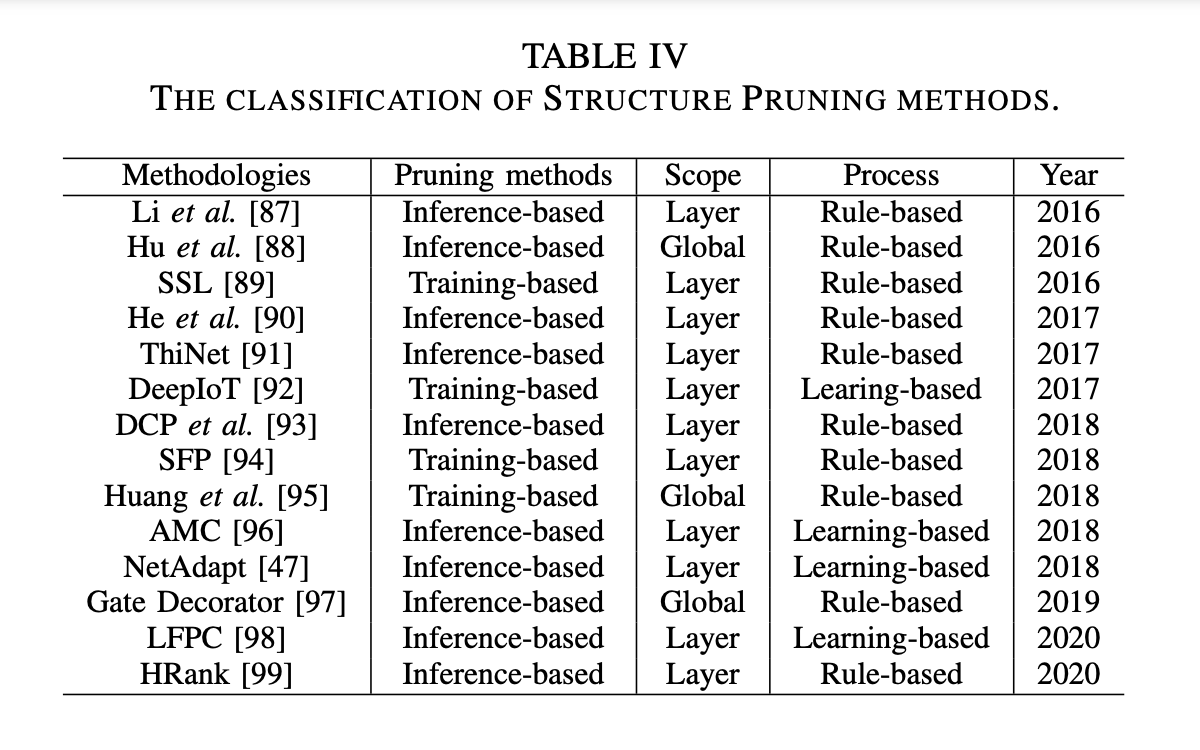
pruning 방법에 따라 Traning-based 와 Inference-based로 나눌 수 있습니다.
- Training-based
- train 중에 pruning이 실행되며, sparsity constraint에 노출됨.
- compact network가 over-parameterized된 네트워크에서 직접 학습됩니다.
- Inference-based
- pruning 방법이 정의된 규칙에 따라 사전 훈련된 모델에서 중복 채널을 줄이는 방식입니다.
pruning 범위에 따라 layer pruning과 global pruning으로 나눌 수 있습니다.
- Layer pruning
- 정의된 타겟에 맞게 layer 별로 pruning을 적용되는 것
- Global Pruning
- 정의된 타겟에 맞게 최상의 pruned network를 찾기 위해 전체 네트워크에 pruning을 적용하는 것
pruning의 프로세스는 Rule-based, Learning-based로 나눌 수 있습니다.
- Rule based
- 정의된 룰에 의해 pruning이 실행되는 것. (ex :
heuristic algorithms)
- 정의된 룰에 의해 pruning이 실행되는 것. (ex :
- Learning based
- learning-algorithm에 의해 pruning이 실행되는 것 (ex :
reinforcement learning,evolutionary algorithms,gradient-based optimization)
- learning-algorithm에 의해 pruning이 실행되는 것 (ex :
pruning의 2가지 결점
1) pruning의 이론적 토대가 부족하기 때문에 복잡한 모델을 pruning해야 하는지 아니면 리소스가 제한된 하드웨어 플랫폼에 대해 compact model을 direct로 훈련해야 하는지에 대한 논쟁이 있습니다.
2) 거의 모든 pruning methods들이 하드웨어와 독립적입니다. 즉, 하드웨어 아키텍처들은 각기 다른 병렬 처리 능력을 갖고 있으므로, pruning methods를 사용한다 하더라도 성능 향상이 이루어지지 않을 수 있습니다.
따라서 다양한 하드웨어에 모델을 맞출 수 있도록 하드웨어를 인지한 pruning methods를 고안할 필요가 있다.
