머신러닝
1.[Ensemble] Boosting
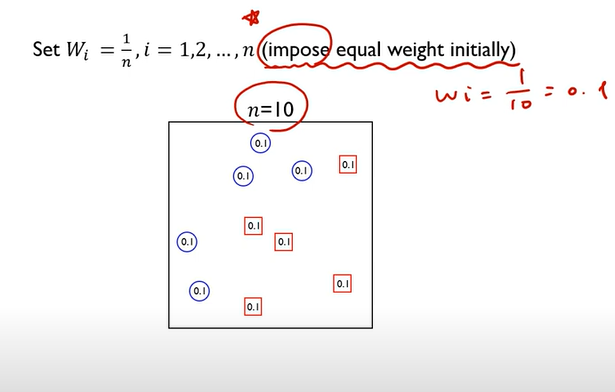
여러 개의 learning 모델을 순차적으로 구축하여 최종적으로 합침여기서 사용하는 learning 모델은 매우 단순한 모델 \- 단순한 모델: Model that slightly better than chance: 정확도가 0.5보다 조금 더 좋음순차적 -> 모델
2.[Ensemble] Bagging
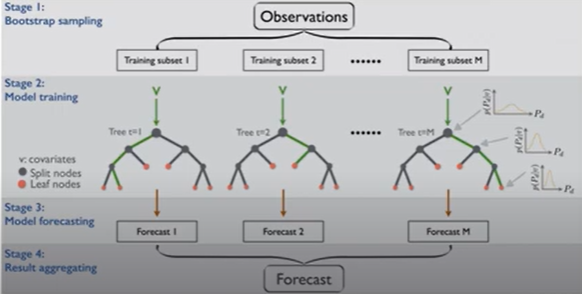
Ensemble의 diversity는 data diversity, model diversity 두가지가 있는데, bagging은 data diversity에 관한 것이다.K-fold 교차 검증은 단일 데이터 분할보다 신뢰성이 높고, 모델의 일반화 성능을 더 정확하게 평
3.[Ensemble] 이론적 배경

No Free Lunch Theorem어떤 알고리즘도 모든 상황에서 다른 알고리즘보다 우월하다는 결론을 내릴 수 없다.문제의 목적, 데이터 형태 등을 종합적으로 고려하여 최적의 알고리즘을 선택할 필요가 있다.Do we need hundreds of classifiers
4.[의사결정나무]
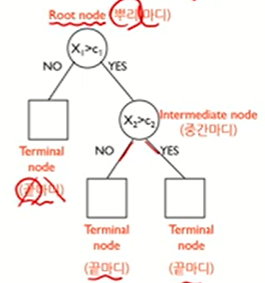
데이터에 내재되어 있는 패턴을 변수의 조합으로 나타내는 예측/분류 모델을 나무의 형태로 만드는 것데이터를 2개 혹은 그 이상의 부분집합으로 분할\-> 데이터가 균일해지도록 분할균일의 정의분류: 비슷한 번주를 갖고 있는 관측치끼리 모음예측: 비슷한 수치를 갖고 있는 관측
5.부스트코스 < DATA SCIENCE PROJECTS> 코칭스터디 : 2024

✅1주차 분류모델 기초https://colab.research.google.com/drive/1EJKInPP7DQ2fxC5ubdOyMFwlw3pZTN08?usp=drive_link✅2주차 EDA를 통해 데이터 탐색하기https://colab.resea