반갑습니다
데이터에 대해 좀 깊게 생각해보면서 글을 작성해볼까 합니다.
최근 자연어처리에서의 AI는 Pretrained 된 언어모델을 바탕으로 추가적으로 데이터를 학습시켜 각자 원하는 일을 수행할 수 있는 모델을 만드는 방향으로 제작되는 것 같습니다.
그러니까
PLM (Pretrained Language Model)의 가중치를 오픈소스로 배포하면 사람들이 그걸 가져다가 본인의 데이터를 먹이는 거죠.
잘 생각해보면
PLM을 가져오는 일은 어렵지 않습니다.
import transformers
model = transformers.AutoModel.from_pretrained(모델이름)이 두줄로 몇십만, 몇백만, 몇억의 파라미터를 가지면서 최적화도 잘 되어있고 고도의 기술의 집약체를 가져올 수 있습니다.
직접 모델을 class로 구현할 수도 있겠지만, 허깅페이스에서 가져오는 모델들은 단순히 multi head attention layer들을 갖다 붙인 것이 아닌 수많은 시행착오를 겪으며 학습을 가장 효과적으로 수행하도록 다양한 테크닉들까지 들어가 있습니다.
무슨 말을 하고싶은거냐면
제가 아무리 잘 만들어도 저 두줄로 가져오는 모델보다 잘 만들기가 쉽지 않다는겁니다.
그럼 어디서 차이가 발생할까요
결국 데이터에서 발생하게 됩니다.
현업에서의 데이터는 얼마나 중요할까?
허깅페이스에서 가져오는 모델들을 우리가 풀고자 하는 도메인에 맞는 데이터를 학습시킴으로서 그 모델은 speciality를 갖습니다.
기업에서 풀고자 하는 다양한 문제를 해결하기 위해서 직접 제작한 데이터는 질과 양이 아주 중요합니다.
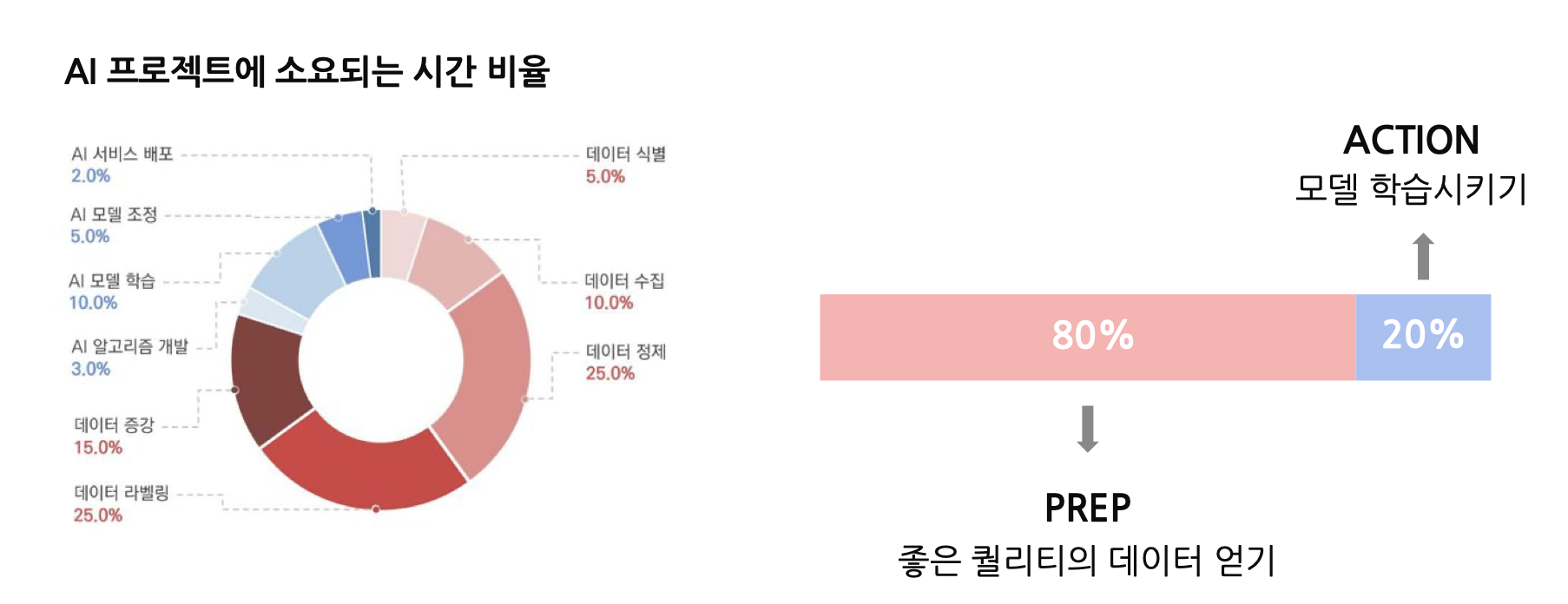
위 사진은 한국인공지능협회에서 만든 사진입니다.
AI 프로젝트에서 모델을 만들고 수정하고 배포하는 시간은 아주아주 작습니다.
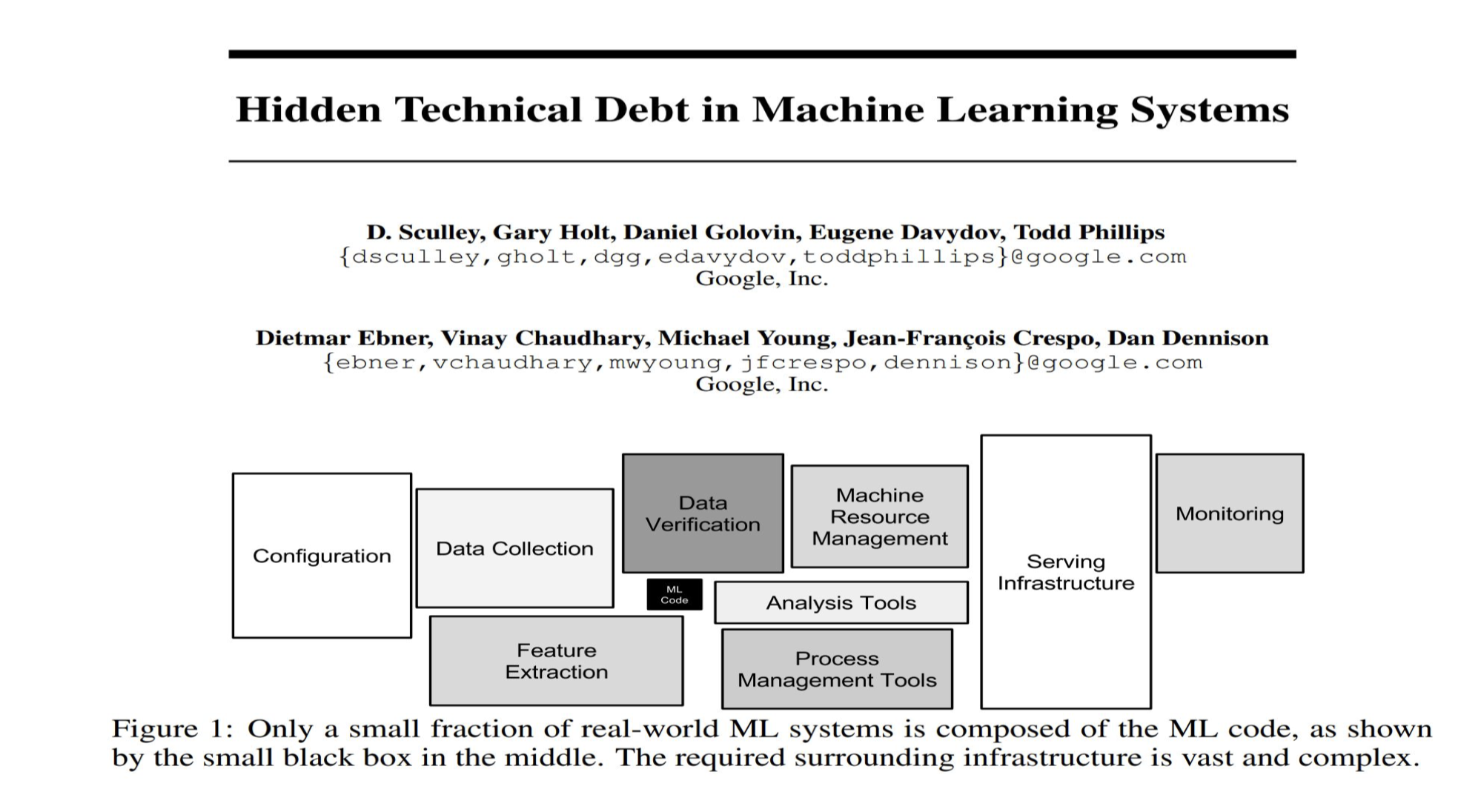
구글에서 발표한 논문입니다.(Hidden Technical Debt in Machine Learning Systems)
저 아주 작은 검정박스가 ML code입니다.
되게 조그마한 부분을 차지하고 있죠.
한국이든, 해외든 AI 프로젝트에서는 데이터를 수집, 가공, 증강하는 과정이 가장 오래걸리고 가장 중요하다고 볼 수 있겠습니다.
좋은 데이터는 어떤 데이터일까?
좋은 데이터란, 그 도메인에서 일어날 수 있는 모든 경우의 수를 표현하는 내용들을 가지고 있으면서 Label에 어떠한 오차도 없고(잘못 매겨지지 않았고), Label의 내용이 흔들림 없이 같은 기준으로 매겨진 데이터입니다.
좋은 데이터에 대해서 생각한 부분들을 적어봤습니다.
데이터에 대한 다양한 연구들이 있습니다.
데이터는 무조건 양이 많아야 한다
라고 주장하는 논문들도 있고
데이터의 양도 중요하긴 한데 아주 깨끗한 소수의 데이터로 학습시켰는데 성능이 대단했다
라고 주장하는 논문들도 있습니다.
제 나름대로 생각해 봤을 때,
좋은 AI 모델은 모든 케이스를 표현할 수 있는 데이터를 통해 학습을 시키는 것이 중요한 것 같습니다.
뭐 양이 많으면 당연히 95% 이상의 케이스를 찾을 수 있겠죠
반대로 모든 케이스를 담고 있다면
적은 데이터로도 맥을 딱딱 짚어서 다양한 케이스를 소화할 수 있도록 학습시킬 수도 있겠습니다.
뭐 양이던 질이던 중요하다는 것은 대부분 다 아실 것 같습니다.
사실 더 중요한건 어떻게 질이 좋고 많은 양의 데이터를 만들 수 있을까에 대한 내용이겠죠.
데이터를 만들 때 필수적으로 사용하는 것은 데이터 증강인데
데이터 증강 대한 글은 다음에 써 보도록 하고
훌륭한 데이터를 만들기 위해 필요한 것들에 대해 써 보겠습니다.
그렇게 좋은 데이터를 어떻게 만들어야 하죠?
데이터를 만들어야 하는 과정까지 돌입했다면
이미 문제를 정의했겠죠.
문제를 정의했다면
1. 그 문제를 풀기 위해서 어떤 데이터가 필요할지 명확하게 결정해야합니다.
어떠한 케이스들이 있을 것이고, 그 케이스들을 학습하려면 어떤 데이터가 있어야 할지를 상세히 그려야합니다.
2. 필요한 데이터를 어떻게 모을 지 결정합니다.
뭐 웹페이지를 크롤링 해서 가져올 수도 있겠고
회사 내부에서 가져올 수도 있겠고
LLM을 통해 케이스를 던져주고 생성할 수도 있겠습니다.
핵심은 내가 필요한 데이터인지 잘 구분하는 것이겠죠.
3. 데이터를 제작하는 데에는 올바른 라벨링이 필수적입니다.
물론 LLM에게 맡겨버릴 수도 있겠지만, 데이터를 처음 만들때에는 필수적으로 인간을 거쳐가야 한다고 생각합니다.
이러한 라벨링 과정이 데이터의 질을 결정한다고 생각합니다.
최근 부스트캠프에서 진행한 Data-centric modeling에서는 Text가 이상하게 바뀐 데이터들과 label이 잘못 매겨진 데이터를 통해 분류모델을 만드는데요.
PLM을 통해 학습을 시킬 때, text 데이터가 무너져도 라벨이 똑바로 서 있다면 제대로 구분하더군요.
'나는 밥을 먹었다.' 라는 문장도
'나 밥 먹었음.'
'나 밥 먹었었음.'
'난 밥 먹음.'
'나 밥 묵엇슴'
다양하게 표현될 수 있습니다.
텍스트가 무너진 데이터로 학습하는 것은 오히려 다양한 케이스의 문장을 받을 수 있기에 도움이 될 수도 있다고 생각합니다.
하지만 라벨이 무너지는건 용서가 안됩니다.
'나는 밥을 먹었다.' 라는 문장의 주제가 '스포츠'로 매겨져 있으면 아무리 문장이 이쁘고 뜻을 정확하게 가지고 있어도 모델은 무너집니다.
그만큼 라벨링이 중요합니다.
보통 현업에서 데이터를 구축할 때, 많은 사람을 고용해 데이터 라벨링을 진행합니다.
데이터의 질은 다양한 사람들이 모두 똑같은 기준으로 라벨링할 수 있도록 상세하고 이해하기 쉬운 Guideline을 만드는 것이 중요하다고 생각합니다.
또, 라벨링 하면서 모호할만한 부분들을 잘 대처할 수 있도록 다양한 케이스들에 대한 대처방안도 마련하는 것이 데이터의 질에 영향을 많이 끼치게 되겠습니다.
4. 데이터의 특성을 잘 파악하는 것도 중요합니다.
주제 분류같은 task는 그냥 아무 한국인도 어느정도 잘 하겠지만, 동/명사 분류 같은 작업은 그래도 국어국문학과를 나온 사람들이 오류 없이 잘 하겠죠.
일단 저보고 동사명사 분리하라고 하면 못할듯싶네요 ㅠㅠ
품사를 구별하는 데에 일반인을 고용(크라우드소싱)하면 데이터의 질이 떨어지고
capcha같이 자동차가 있는 사진을 찾는 Task에(근데이거좀 어려움) 서울대 석박사분들을 고용하면 돈이 떨어집니다.
데이터의 특성을 보고 라벨링을 맡길 사람을 정하는 것도 중요하겠습니다.
5. 만들어진 데이터를 제대로 검사해야 합니다.
아주 똑똑한 사람들이 만든 데이터라도 분명 라벨링 실수, 애매한 case 등이 제작 과정에서 발생하게 됩니다.
똑똑한 사람도 비슷한 데이터 만개 보면 졸리고 뇌가 제대로 가동을 안합니다.
만들어진 데이터를 제대로 검수할 수 있는 프로세스를 미리 구축하고 다시 한번 check하는 시간을 가져야 합니다.
'
'
'
이번 글에서는 클린한 데이터를 구축하기 위해 어떤 작업들이 필요할지에 대해서 적어봤습니다.
글을 작성하다 보면 확실히 머리속에 구조가 잘 정리되는 것 같습니다.
요즘 드는 생각인데
구조를 아는것이 좀 많이 중요한거 같다고 생각합니다.
머리속에 로드맵이 있다면 구현은 LLM이 해주니까요.
다음 글에서는 데이터를 증강하는 부분에 대해서 더 깊게 글을 작성해볼 것 같습니다.
감사합니다 !
