반갑습니다
예전에 텍스트 데이터에 대해 글을 작성했었는데요.
그 글에 LLM을 활용한 데이터 증강이 없어서 내용을 보충할까 합니다.
데이터 증강에는 다양한 방법이 있지만 이번 내용은 합성 데이터 생성을 통한 데이터 증강에 대해 소개해보겠습니다.
합성데이터 ?
합성 데이터는 실제 데이터를 모방한, 인간이 생성하지 않은 데이터입니다. 생성형 인공 지능 기술을 기반으로 한 컴퓨팅 알고리즘 및 시뮬레이션을 통해 생성됩니다. 합성 데이터 세트는 기반이 되는 실제 데이터와 동일한 수리적 속성을 갖지만 동일한 정보를 포함하지 않습니다. (출처 : AWS 웹페이지 합성데이터 정의)
간단하게 설명하면 생성형 인공지능으로 실제 데이터를 흉내낸 데이터라고 생각하시면 되겠습니다.
GPT에 들어가서
'배고픈 사람이 할 법한 말을 3가지 정도 생성해 줘.'
라고 하면 output이 나오겠죠.
그 output을 train 데이터로 활용하는 것입니다.
합성 데이터는 최근 LLM의 성능이 너무나도 좋아지면서 점점 더 퀄리티가 좋은 데이터를 생성할 수 있게 됐습니다.
하지만 시중에서 사용되는 대부분의 LLM들은 오픈소스가 아닙니다.
돈 내고 몇만개 몇십만개 데이터를 만드는 것은 비용적으로 쉽지 않겠죠.
그래서 대부분의 대기업들은 기업의 데이터로 독자적인 LLM을 만들어서 사용합니다.
그럼 나같은 사람은 어뜩해야할까요
아주 대단한 퀄리티의 데이터를 만들 순 없겠지만, 오픈소스로 공개된 모델 중 비교적 작은 7B모델 등을 활용하여 데이터를 만들 수 있습니다.
llama나 업스테이지의 solar 등이 있겠죠.
이 때, 생성되는 데이터는 Prompt를 얼마나 잘 구성해서 입력으로 넣냐에 따라 퀄리티가 결정되겠습니다.
요즘에는 프롬프트 엔지니어링이라는 직군도 생기고 있다 하더군요.
제 생각에는 그정돈가.. 싶긴 합니다.
하지만 시켜준다면......... 돈을 준다면 .........
기꺼이 하고싶군요
어떻게 생성해요 ??
이건 코드로 간단히 살펴보겠습니다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Upstage/SOLAR-10.7B-Instruct-v1.0")
model = AutoModelForCausalLM.from_pretrained(
"Upstage/SOLAR-10.7B-Instruct-v1.0",
device_map="auto",
torch_dtype=torch.float16,
)
conversation = [ {'role': 'user', 'content': 'Hello?'} ]
prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, use_cache=True, max_length=4096)
output_text = tokenizer.decode(outputs[0])
print(output_text)
위 코드에서는 AutoModel로 불러왔지만, transformers의 pipeline을 통해 불러올 수도 있습니다.
아무튼 PLM을 불러왔다면, 'role'과 'content'를 잘 구성해서 템플릿을 작성합니다.
이 템플릿을 프롬프트라고 이해하시면 되겠습니다.
model.generate를 통해 데이터를 auto-regressive하게 생성합니다.
이 때, max_length, temperature 등을 조절해서 output의 길이, 단어들의 rarity(희소성) 등을 결정하시면 되겠습니다.
Prompt
프롬프트(Prompt): 사용자 또는 시스템에서 제공하는 입력으로, LLM에게 특정 작업을 수행하도록 요청하는 지시문입니다. 프롬프트는 질문, 명령, 문장 시작 부분 등 다양한 형태를 취할 수 있으며, LLM의 응답을 유도하는 데 중요한 역할을 합니다.
(출처 : 위키독스 랭체인(LangChain) 입문부터 응용까지 )
conversation = [ {'role': 'user', 'content': 'Hello?'} ]
prompt = tokenizer.apply_chat_template(conversation,
tokenize=False, add_generation_prompt=True)
role과 content가 뭘까요
role은 LLM이 어떤 역할일지를 결정합니다.
content는 그 역할을 가진 LLM이 수행할 업무를 지시하는 부분입니다.
PROMPT = '''You are a helpful AI assistant. Please answer the user's questions kindly.
당신은 기자의 어시스턴트 입니다. 사용자의 질문에 대한 기사 제목을 만들어 주세요.'''
instruction = f"다양한 주제로 뉴스 기사 제목을 한개만 만들어 줘."이런식으로 지시한다면 뉴스 기사를 생성할 것이고
PROMPT = '''You are a helpful AI assistant. Please answer the user's questions kindly.
당신은 문장을 재구성하는 전문가입니다. 주어진 문장과 의미가 동일한 새로운 문장을 생성해주세요.'''
instruction = f"아래 문장과 동일한 의미를 갖는 새로운 문장을 하나만 만들어줘:\n\n'{text}'"이런식으로 지시한다면 주어진 문장과 비슷한 의미의 다른 문장을 생성하겠죠.
결과물을 살짝 살펴보겠습니다.

위 세 문장 모두 "MLP-KTLim/llama-3-Korean-Bllossom-8B" 라는 허깅페이스에서 무료로 공개돼 있는 모델을 사용하여 만든 문장들입니다.
훌륭하죠
하지만 항상 완벽하진 않습니다. 문장의 의미가 이상하거나 지시대로 output을 내보내지 못하는 경우도 존재하죠.
이런 경우를 최대한 줄이려면 어떻게 해야 할까요
Few shot Prompting
Few shor Prompting은 LLM에게 지시를 내릴 때 몇가지 예시를 보여주어 LLM이 지시를 명확히 이해하도록 하는 prompt 작성 기법입니다.
LLM에게 지시를 내릴 때
# Chat GPT labeled examples
few_shot_message = ""
# Mention the Task
few_shot_message = "Task: Sentiment Classification \n"
# Mention the classes
few_shot_message += "Classes: positive, negative \n"
# Add context
few_shot_message += "Context: We want to classify sentiment of hotel reviews \n"
#Add labeled examples
few_shot_message += "Labeled Examples: \n"
for labeled_data in labeled_dataset:
few_shot_message += "Text: " + labeled_data["text"] + "\n";
few_shot_message += "Label: " + labeled_data["label"] + "\n"이런식으로 예시를 몇가지 보여주고 지시를 내리는거죠.
이게 정말 효과가 있을까요?
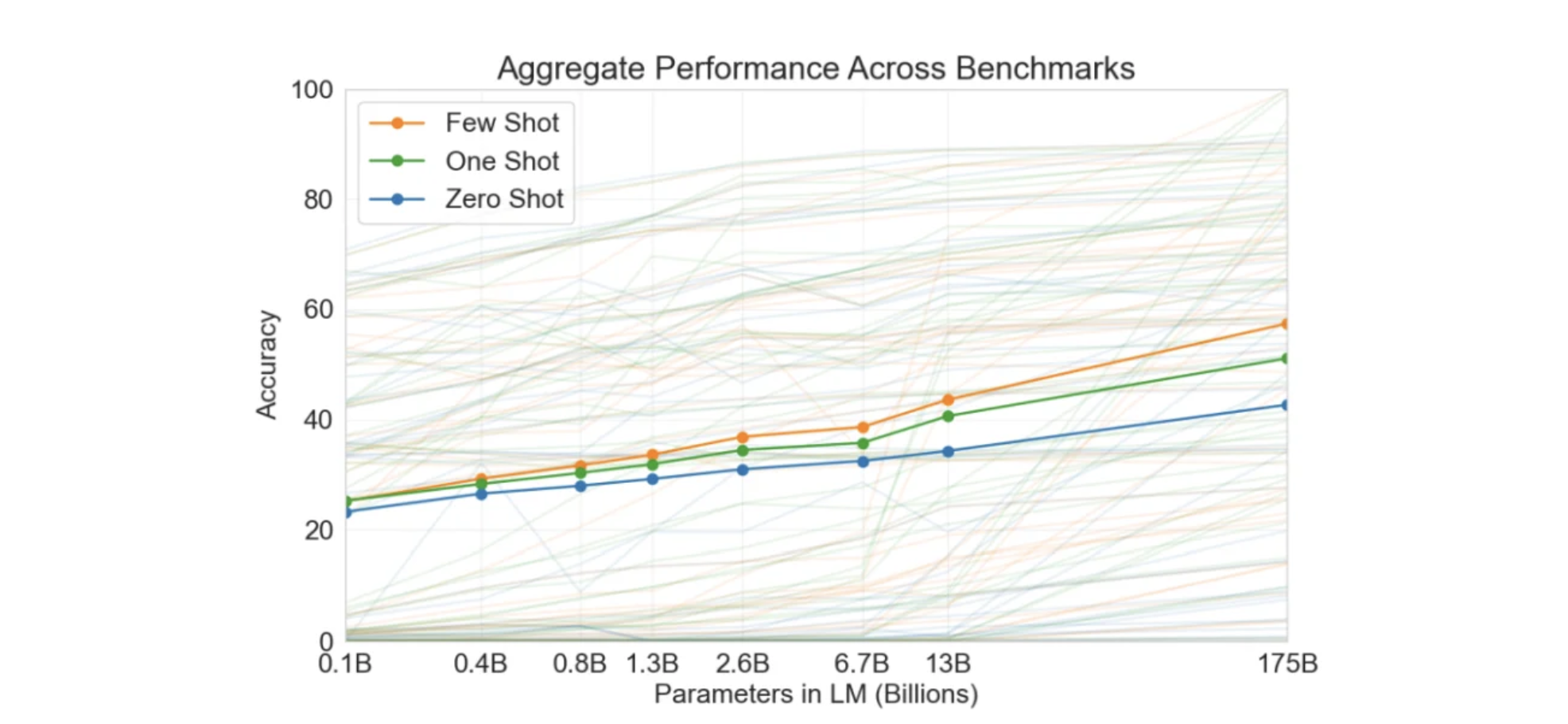
(출처 : https://www.unite.ai/gpt-3-few-shot-learning-for-language-model/)
위 그림을 보면 one-shot (예시 한개) 이 zero shot보다 acc가 높고, few shot(예시 여러개)의 경우 acc가 더 높은 것을 확인할 수 있습니다.
또 예시를 주는 경우에는 output의 형태를 좀 더 가공하기 쉽게 받을 수 있다는 장점도 있습니다.
예를 들어
'오늘 점심 메뉴를 추천해 줘.'
라는 지시문을 준다면
'좋습니다 ! 메뉴는 ~~~ ' 이런식으로 나온다던가 '위 문장은 점심 메뉴를 추천해달라는 문장입니다. 최근 요식업 ~~' 이런식으로 나온다던가
뭔가 혓바닥이 좀 길게 나올 수도 있습니다.
하지만 예시로
ex1 : 김치찌개
ex2 : 라면
ex3 : 마라탕 이렇게 준다면
output 또한 단어 한 개로 나올 수 있습니다.
지시문에 '단어 한개로 대답해줘' 라고도 할 수 있고.. 방법은 다양합니다.
다양한 prompt를 구성해서 원하는 대답이 나올 때 까지 지시문을 수정하는것이 바람직하겠습니다.
'
'
'
이로서 이전 글의 EDA 증강법, backtranslation에 이어 LLM을 통한 합성 데이터 증강까지 알아봤습니다.
사실 모델을 쓰지 않고 사람들이 만드는게 제일 좋긴 하겠죠.
하지만 비용적으로 쉽지 않습니다.
결국은 비용과 퀄리티 trade-off 관계인 것이지요.
글을 작성해 보니 두 마리 토끼를 전부 잡으려면 프롬프트 엔지니어를 고용해서 적은 돈으로 높은 퀄리티의 데이터를 구하고자 하는 노력도 충분히 이해가 가는군요.
저도 이번 기회에 많은 경험을 쌓아서 현업에서도 증강을 휘뚜루마뚜루 할 수 있도록 노력해야겠습니다.
감사합니다 !
