반갑습니다
Data Flywheel에 대해 소개해볼까 합니다.
최근 진행하고 있는 Data-cetric NLP를 하면서 느낀 점이 많습니다.
현업에서는 이렇게 하는구나 라는 감을 좀 많이 익히는 듯 싶습니다.
Data Flywheel이란 용어는 생소할 수 있는데요.
대단한 건 아닙니다.
여러분들이 이미 알고 계신 부분들을 합친 하나의 프로세스라고 생각하시면 되겠습니다.
사람들은 왜 이미 있는것들을 모아서 새로운 용어를 정의할까요
제 생각엔 개념을 구조화하는 것이 중요해서 같습니다.
아무튼
Data Flywheel?
Data Flywheel은 데이터와 기계 학습 모델이 상호작용하면서 성능을 지속적으로 개선하는 일종의 선순환 구조를 뜻합니다.
이는 데이터가 많아지고 정교해질수록 모델이 더 정확해지고, 모델이 개선될수록 더 가치 있는 데이터가 생성되어 또 다른 데이터 축적과 개선으로 이어지는 반복적인 과정입니다.
Flywheel 이란 단어의 뜻은 성장을 만드는 선순환의 수레바퀴
라는 의미입니다
사진을 보시면 이해가 쉬울 듯 싶습니다.
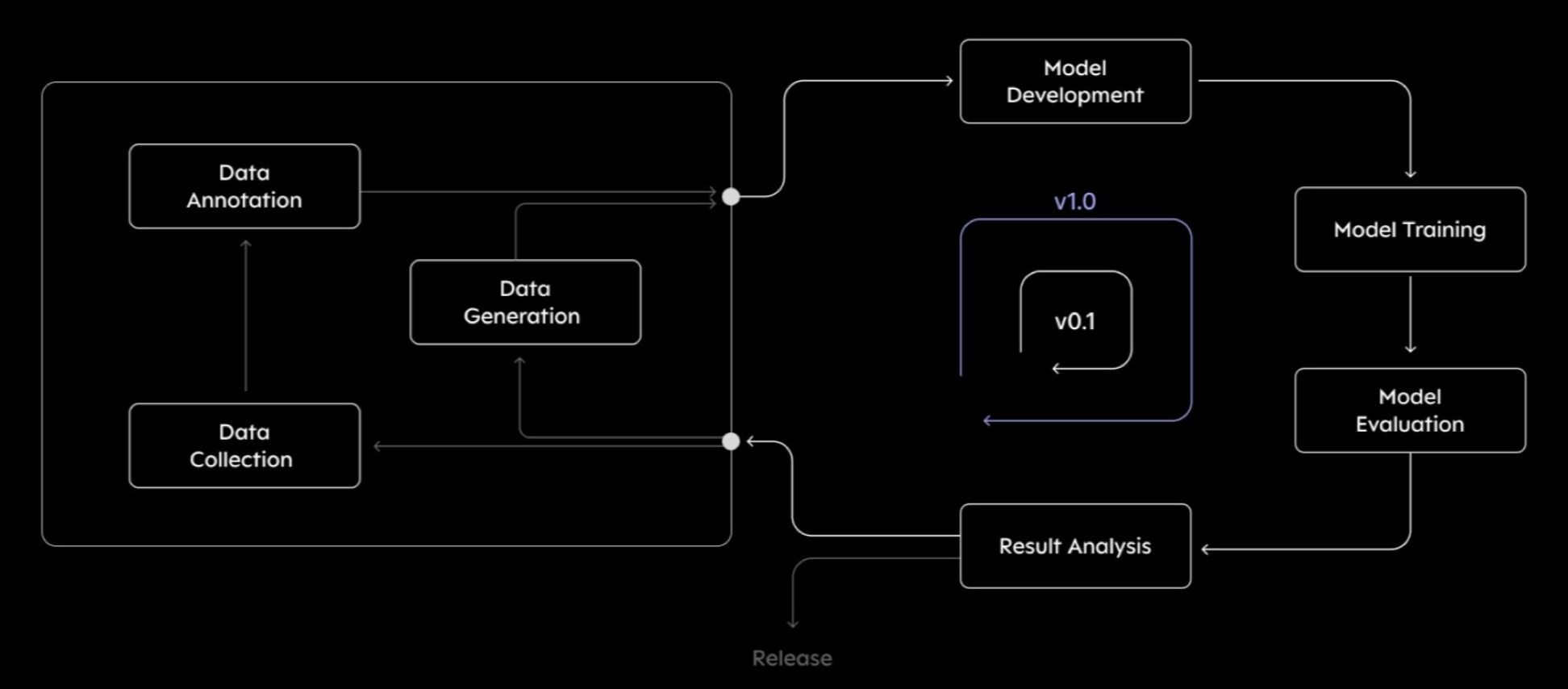
왼쪽에
Data Annotation
Data generation
Data Collection
은 학습에 필요한 데이터를 모으는 과정입니다.
오른쪽의
Model Development
Model Training
Model Evaluation
Result Analysis
들은 모은 데이터를 바탕으로 모델을 만들고 평가하고 분석하는 과정입니다.
예를 들어보겠습니다.
초기 만개의 데이터를 통해 모델을 클래스 예측 모델을 학습시켰다고 해봅시다.
그 모델로 무언가를 예측하면 클래스별 확률 분포를 알 수 있겠죠.
그럼 확률 분포가 99퍼 이런게 아니라 40퍼, 50퍼정도 되는 모델이 아리까리한 데이터들이 존재할 수 있습니다.
그럼 다음 학습에 애매했던 데이터를 더 많이 추가하여 2차 학습을 진행하게 되겠죠.
애매했던 데이터는 첫 학습을 통해야만 알 수 있습니다.
사진을 보고 클래스를 분류할 때,
비비빅과 바밤바가 헷갈린다
라는 정보는 해봐야만 알 수 있지요.
본인의 데이터셋의 약점을 알 수 있는겁니다.
그럼 비비빅 사진과 바밤바 사진을 더 많이 가져오거나
비비빅 사진과 바밤바 사진을 증강하는 방향으로 데이터를 늘릴 수 있겠습니다.
이렇듯 모델 훈련과 데이터 수집은 긴밀한 관계를 갖습니다.
데이터, 모델 둘 중 하나의 퀄리티가 높아지면 자연스레 다른 하나도 퀄리티가 높아집니다.
이것이 Data Flywheel입니다.
이 중, 분석한 결과를 바탕으로 데이터를 보강하고 관리하는 업무를 DMops라고 하죠.
DMOps
DMOps는 "Data Management Operations"의 약자로, 데이터 관리와 운영을 최적화하기 위한 시스템과 프로세스를 뜻합니다. DMOps는 주로 데이터 중심 조직이 대규모 데이터를 효율적으로 관리하고 활용할 수 있도록 지원하며, 특히 머신러닝과 인공지능 프로젝트에서 원활한 데이터 파이프라인을 구축하는 데 중요한 역할을 합니다.
DMOps가 하는 일들은
- 데이터 수집
- 파이프라인 관리
- 품질 관리, 전처리들
- 데이터 저장, 접근권한 관리
- 데이터 거버넌스 고려
이정도가 있겠습니다.
1,2,3,4는 자주 들어 보시고 또 아실거라 생각합니다.
주의깊게 봐야할 부분은 5번이겠네요.
데이터 저작권에는 다양한 종류가 있습니다.
1. 연구목적
2. 공공을 위해서만 사용 가능
3. 개인의 이익을 위해서 사용 가능
어떤 데이터는 연구를 위해서만 사용이 가능하고.. 어떤 데이터는 국가같은 공공기관에 도움을 주고 수입을 내지 않는 선에서만 가능하고... 어떤 데이터는 상관없이 사용할 수 있습니다.
저같은 취준생은 주로 데이터를 사용한다면 1. 연구목적 을 위해서만 사용했으므로 저작권에 크게 신경쓰지 않았었는데, 기업은 수익을 내는 집단이기에 수입을 내는것이 금지된 데이터를 사용하면 안됩니다.
고소미를 먹을 수 있어요 ㅠ
따라서 DMOps에서는 수집된 데이터가 법에 위배되지 않는지, 또 수익을 내도 되는지 등 안전한 데이터를 고려하고 모으는 것이 중요합니다.
근데 만약에 학습하고 모델배포까지 해놨는데 갑자기 데이터중 일부가 수익창출 금지로 바뀌면 어카죠...? 다시 만들어아햐나
아무튼 위 내용들이 DMOps의 역할이라고 보시면 되겠습니다.
이번엔 모델의 관점으로 넘어가보겠습니다.
Data Flywheel에서의 오른쪽 부분입니다.
이 부분은 우리가 자주 듣는 MLOps분들이 하시는 업무라고 생각하시면 되겠습니다.
MLOps
MLOps는 모델의 개발, 배포, 운영을 중심으로 하는 집단입니다.
DMOps와 다르게 주로 머신러닝 모델을 지속적으로 개선하고 효율적으로 운영할 수 있는 프로세스를 구축하는 데 중점을 둡니다.
DMOps분들이 열심히 가공해주신 데이터를 잘 쓰실 분들이 필요하겠죠.
MLOps에서는 그 역할을 수행합니다.
역할들을 살펴보자면
1. 모델 학습
2. 평가
3. 배포
4. 모니터링, 버전 관리
5. AI 윤리 검증
이거도 1,2,3,4번은 여러분들이 잘 알고 계시는 부분이죠.
주의깊게 봐야할 부분은 5번입니다.
저번 글에서도 다양한 데이터셋에 대해서 소개해드렸는데요.
많은 종류의 데이터의 초점이 AI윤리에 맞춰져 있었습니다.
AI가 인간을 지배한다.. 뭐 이런 얘기 AI 하시는 분들은 공감을 못하실 수도 있겠지만.. AI에 대해 자세히 알 일이 없는 일반 소비자분들은 경계할 수 있다고 생각합니다.
최대한 많은 소비자를 끌어오기 위해서는 성능 뿐만 아니라 나쁜 말을 안하는지, 마약 제조법 이런거 안알려주고 뭔가 무섭게 대답 안하고 그런 요소들도 필요합니다.
그러기 위해서는 AI모델이 윤리에 어긋나는 답변을 생성하거나 내보낸 결과가 신뢰성이 있어야 합니다.
이 부분이 아주 어렵습니다... 할루시네이션은 아직까지도 정복하지 못한 부분이기도 하고 ㅠ
또, 다른 사람의 프라이버시에 관한 정보를 답변으로 내보내면 안되겠죠.
고려해야 할 부분이 많습니다.
대체로 ML모델은 DMOps에서 처리한 데이터가 질이 좋을수록 성능이 향상되기에 DMOps의 역할이 중요하고, DMOps분들은 모델의 성능이 좋을수록 더 좋은 데이터를 제공할 수 있기 때문에 서로 상호보완적이라고 할 수 있겠습니다.
'
'
'
이로서 Data Flywheel과 DMOps, 추가로 MLOps까지에 대한 설명을 마칩니다.
확실히 글을 적는 것이 머리속에 정리가 잘 되는 느낌입니다.
여러 직무가 하는 일에 대해 자세히 알고 있는 것이 본인의 진로를 정하는 데에 큰 힘이 된다고 생각합니다.
혹시나 틀린 부분이 있다면 알려주시면 도움이 많이 될 것 같습니다.
감사합니다 !
