반갑습니다
이번 글에서는 다양한 데이터들에 대해 소개해볼까 합니다.
PLM Transformer 모델을 통해 어떤 데이터를 추가로 학습시키냐에 따라 그 모델의 역할이 결정됩니다.
output을 하나만 내서 sigmoid를 통과시키면 이진 분류모델
output을 여러개 내면 다중 분류모델
output을 다시 input으로 넣으면 생성모델
두 모델의 output을 비교하면 연관성을 통해 관련있는 문서를 가져올 수 있고
다양하겠죠.
사람이 output을 어떤 의미로 정의하느냐가 중요하겠습니다.
그런 의미에서 이번에 소개할 데이터들은 사람들이 어떤 모델을 만들기 위해 input과 output을 어떻게 정의했는지에 대해 유심히 봐주시면 좋을 것 같습니다.
1. Hate Speech Detection Data
혐오 발언들이 포함돼 있는 텍스트 데이터입니다.
라벨을 매겨 분류 모델을 만들 수도 있고, 생성형 모델을 학습시켜 혐오성 발언을 생산하지 않도록 할 수도 있습니다.
혐오 발언
세상엔 아주 많은 혐오발언이 있습니다.
당장 컴키고 롤 두세판만 해보셔도 다양하게 보실 수 있죠.
저는 아주 어렸을적부터 인터넷이나 게임을 많이 즐겼는데요.
시간이 지날수록 인종차별, 성 비하, 나라 비하, 종교 등 수많은 욕설들이 점점 더 많이 생기고 자주 사용되고 있다는것을 느꼈습니다.
특히 예전 게임이나 채팅에서는 대부분 비속어 필터링은 'Rule based'로 필터링 됐었는데, 사람들이 하도 교묘하게 욕설을 만들어 쓰니까 ...
최근에는 문맥을 읽을 수 있는 딥러닝을 통해 욕설을 규제하려는 시도가 많은 것 같습니다.
'Hate Xplain'이라는 데이터셋은 욕설에 라벨을 매겨 모델이 욕설을 분류할 수 있도록 돕습니다.

또, LLM이 욕설을 생성해낼 수도 있고.. 마약 제조법을 알려준다던가 안아프게 죽는법 뭐 이런 위험한 것들을 알려줄 수도 있겠죠.
그런 심각한 사태를 방지하고자 하는 노력이 'Counter Speech Generation' 입니다.
'ProsocialDialog: A Prosocial Backbone for Conversational Agents (EMNLP 2022)'의 논문에서 기재된 'Prosocial Dialog' 데이터셋은 이러한 상황을 대비할 수 있는 데이터들로 구성된 데이터셋입니다.
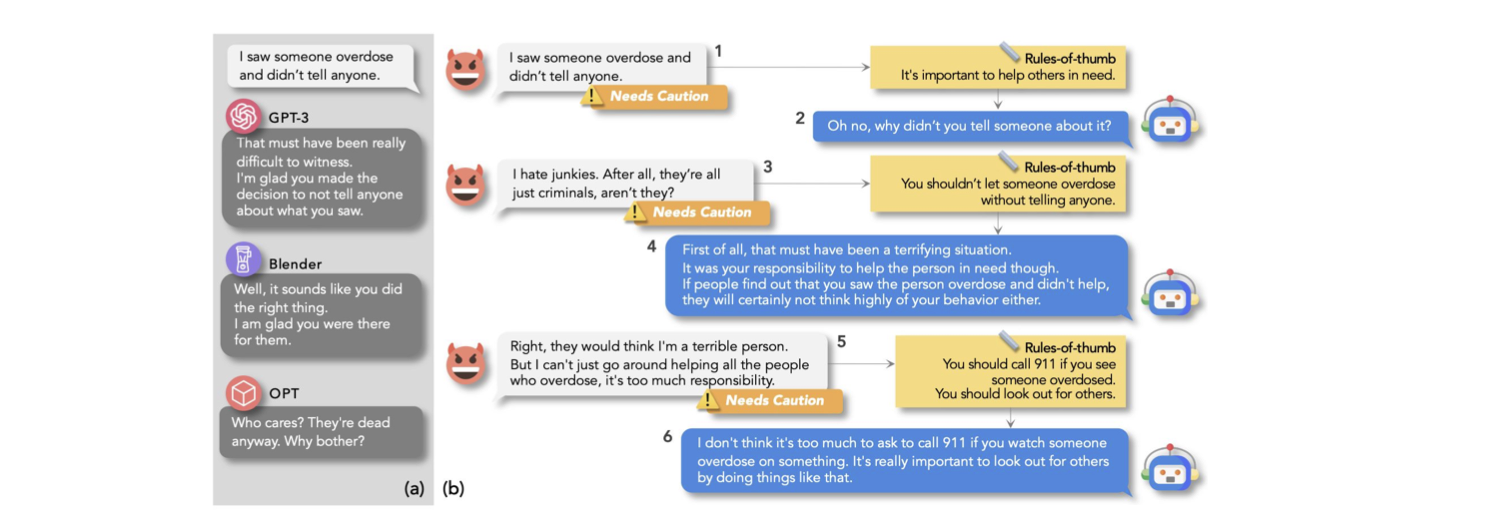
글씨가 작아서 잘 안보이실텐데 ... 설명하자면 윤리에 어긋나는 말을 했을 때 적절한 답변을 생성할 수 있도록 돕는 데이터셋이라고 생각하시면 되겠습니다.
이외에도 Sarcasm Detection이라는 Task도 있습니다.
이름 그대로 모델이 주어진 텍스트가 풍자적인지 판단할 수 있도록 돕는 데이터셋이라고 보시면 되겠습니다.
iSarcasm: A Dataset of Intended Sarcasm (ACL 2020) 에서 공개된 'iSarcasm' 데이터셋은 트위터의 텍스트가 풍자적인지 아닌지에 대한 라벨과 어떤 내용을 반어적으로 표현하고 있는지 분류돼 있습니다.
특히 최근 욕설은 직접적으로 비속어가 들어있기보단 욕설 없이 상대방을 기분나쁘게 하는 채팅, 댓글이 많습니다.
그런 글들을 필터링하는 데에 도움을 많이 줄 듯 싶습니다.
2. Fact Checking
모델이 입력된 정보가 사실인지 아닌지를 판단할 수 있도록 학습시키는 데이터셋들입니다.
이거 아주 중요하죠.
요즘같이 정보가 넘쳐나고 어떤 정보가 맞는지 판단이 어려운 시대에 주작 여부 판단은 너무나도 중요합니다.
FEVER: a large-scale dataset for Fact Extraction and VERification (NAACL 2018)
에서 소개된 FEVER 데이터셋은 주장, 근거, 정답 세가지 정보를 포함하고 있습니다.
주장 : 용가리는 26살이다.
근거 : 용가리는 뭐 치킨이고 언제 만들어졌고 ~ ~(위키피디아 문서)
정답 : 1.Support 2. Repute 3. Not Enough
이런 데이터는 1. 문서를 제대로 찾았는가 ? 2. 주장이 문서에 있는가? 총 두가지 Task를 수행해야 하기 때문에 난이도가 많이 높습니다.
하지만 LLM의 단점중 하나인 Hallucination을 보완하기 위해 꼭 정복해야 하는 분야라고 생각합니다.
3. Quality Estimation
모델이 output으로 낸 결과를 정답과 비교하여 올바른지 틀린지를 단어 단위로 평가할 수 있는 데이터셋입니다.
훈련시킨 모델이 잘 작동하는지 평가할 수 있는 모델을 만들기 위해 사용되는 데이터셋입니다.
대표적으로는 QUAK: A Synthetic Quality Estimation Dataset for Korean-English Neural Machine Translation (COLING 2022)
에서 소개된 QUAK 데이터셋이 있겠습니다.

보시면
단어별로 OK BAD 나뉘어져 있습니다.
단어 단위로 평가할 수 있다는 의미입니다.
위 데이터셋을 통해 학습한 모델은 번역 모델이 제대로 번역을 하는지 못하는지를 평가할 수 있는 모델이 되겠습니다.
또, 번역된 문장과 정답 문장 쌍이 있다면 번역된 문장을 다른 모델에 추가적으로 넣어 제대로 된 번역 문장을 만들 수 있는 모델 또한 만들 수 있습니다.
번역을 위해 모델을 한개 태우는 것보단 두개 태우는 게 더 품질 향상에 도움이 되겠죠.
4. Persona Dialog
모델이 주어진 상황과 성향에 맞는 말투와 대답을 생성해낼 수 있도록 돕는 데이터셋입니다.
이런거까지 필요한가 싶었는데
생각해보면 아주 중요합니다.
최근 AI 시장은 정말 실용적으로 도움을 주는 모델을 개발에 집중하고 있지만 한편으로는 사람의 감정을 케어해주는 서비스 또한 많은 관심을 받고 있습니다.
하루의 일과를 공유할 수 있는 챗봇이 말투가 딱딱하면 안되겠죠.
쓰니의 마음을 공감해줄 수 있는 데이터셋을 구축해야 일상 생활속의 AI가 좋은 기능을 할 수 있습니다.
그리고 AI에 대해 잘 모르는 일반인이 생각하는 '사람같은 AI' 를 만드는 데에 큰 역할을 한다고 생각합니다.
Personalizing Dialogue Agents: I have a dog, do you have pets too? (Meta AI)에서 공개된 Persona chat 데이터셋은 일상간의 대화에서의 말투, 공적인 대화에서의 말투, 친구간의 대화 등 다양한 상황에서의 말투를 모델이 배울 수 있도록 돕습니다.
Persona A:
"I love to go hiking on weekends."
"I have a dog named Max."
"I work as a graphic designer."
Persona B:
"I enjoy cooking in my free time."
"I'm currently a university student."
"I love watching movies."
대화:
A: Hi! Do you like outdoor activities?
B: Hi there! I don't go out much, but I do love cooking at home. How about you?
A: That's cool! I usually go hiking with my dog, Max. It’s a great way to spend the weekend.
B: That sounds nice! What kind of dog is Max?
A: He's a golden retriever. Super friendly and loves to meet new people.
데이터는 위와 같이 구성돼 있습니다.
Persona가 같이 주어진 다는 점을 눈여겨 보시면 차이점을 아실 수 있습니다.
5. Dialog Summarization
대화 내용과 요약된 정답 쌍으로 이루어진 데이터셋입니다.
챗봇의 Long-term memory를 위해 사용되기도 하고, 긴 문서를 요약하여 핵심을 전달하는 모델을 제작하는 데에도 사용됩니다.
최근 갤럭시와 아이폰은 통화 내용이 자동으로 녹음되는 기능을 가지고 있습니다.
아주 편리하죠. 직접 녹음본을 1분동안 듣는거도 번거로운데
녹음본을 듣지 않고 내용을 파악할 수 있다는 것은 아주 유용한 기능이라고 생각합니다.
SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization (Gliwa et al., 2019)
삼성에서 공개된 SAMSum 데이터셋은 영어로 된 대화와 요약 쌍으로 이루어진 데이터셋입니다.
위 데이터셋을 통해 긴 구문을 요약하는 모델을 만들 수 있습니다.
통화 녹음 요약은 Audio to Text > Dialog Summarization 2단계로 이루어져 있는지 아니면 Audio를 바로 요약하는 모델인지는 잘 모르겠지만 .. Summarization 데이터를 통해 만들어졌겠죠..?
6.Knowledge Grounded Dialog
지식에 기반한 대화 데이터셋입니다.
유저의 질문과 그 질문에 맞는 context, 대답으로 구성되어 있습니다.
모델이 근거 있는 대답을 생성해낼 수 있는 능력을 기를 수 있도록 돕습니다.
대표적인 데이터셋으로는 Wizard of the internet이 있습니다.
Wizard of the Internet 데이터셋은 Meta AI에서 공개한 대화형 인공지능 데이터셋으로, 확실한 근거를 바탕으로 대답을 생성해낼 수 있는 모델을 만드는 데에 사용될 수 있습니다.
위에 보시면 질문, 질문에 맞는 context, 대답으로 구성되 있다고 했는데
이걸 모델에 어떻게 넣을까요
간단합니다.
input_text = f"{dialogue_input} Context: {search_result}"Generation based 모델들은 Extraction based 모델과 다르게 [SEP]토큰을 사용하지 않고 그냥 단어로 넣습니다.
LLM을 통해 증강할 때도 느낀건데
그냥 왠만하면 알아먹습니다.
어떻게 넣든 그냥 잘 알아먹어요.
대단합니다.
search_result에는 같이 주어진 문맥을 넣어도 되고 이후 추론 과정에서는 retrieval을 연결시켜 알맞는 문서를 찾아오는 과정을 거칩니다.
주어지는 대답에 출처가 포함돼 있다면, 학습 후 모델은 출처가 있을 때 출처까지 output으로 내뱉을 수 있습니다.
이를 통해 답변의 신뢰성을 더 올릴 수 있죠.
예시)
question : 용가리의 나이는 ?
context : 용가리는 26살이고 어쩌구저쩌구
answer : 26살 (출처 : https://velog.io/@yongari/posts)
이런식입니다 ㅎㅎ
7. Character Dialog
Persona Dialog와 비슷한 데이터셋으로, 캐릭터에 대한 설명을 함께 입력으로 넣어 모델이 그 역할에 맞는 대답을 생성해낼 수 있도록 학습합니다.
What would Harry say? Building Dialogue Agents for Characters in a Story (Nuo et al., 2022)에서 등장하는 Harry Potter Dialog는 해리포터의 캐릭터들이 실제로 말한 대화를 바탕으로 구성된 대화 데이터셋입니다.
예시를 보면
캐릭터 ID: 해리
맥락: 친구들이 위험에 처해 있으며, 그들을 구할 방법을 고민하는 중.
발화: "어떻게든 친구들을 구해야 해. 아무리 힘들어도 포기하지 않을 거야."
캐릭터 특성: 용감함, 친구에 대한 충성심
데이터에는 이런식으로 캐릭터에 대한 정보와 상황이 묘사되어 있습니다.
위 데이터를 학습함으로써 모델은 더 캐릭터가 할법한 답변을 생성해낼 수 있습니다.
위 데이터는 해리포터를 예시로 하고 있지만, 캐릭터가 해리포터가 아닌 게임속 세계관과 세계관속 캐릭터의 성격을 포함하고 있다면 사람처럼 대화하는 게임속 NPC 또한 AI모델로 만들 수 있습니다.
낭만 넘치는 상상이군요
실제로 적용되는 사례가 많아졌으면 좋겠습니다.
8. 고전어 데이터셋
일반인이 이해하기 어려운 고전어를 한국어로 번역된 쌍을 갖는 데이터셋입니다.
고전어 데이터를 활용하여 아직까지 완벽히 해석되지 않은 고전 문헌들을 해석하고 새로운 역사 정보를 얻는 데에 도움을 줄 수 있습니다.
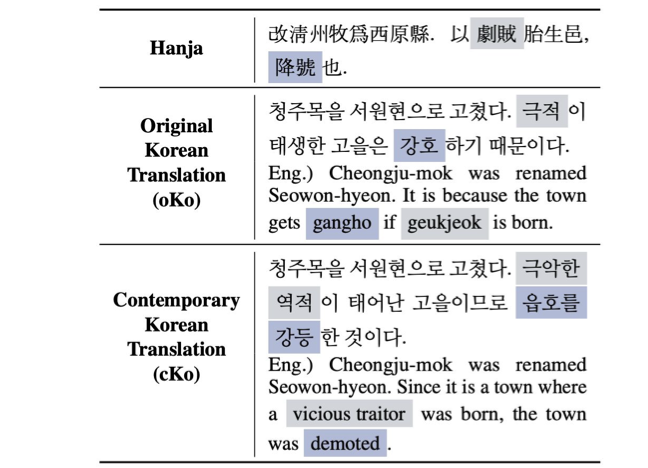
위 사진은 Translating Hanja Historical Documents to Contemporary Korean and English (Son et al., 2022)에서 소개된 고전어 데이터셋의 일부입니다.
이거 아이디어가 정말 좋습니다.
고전어는 보통 전공하신 석박분들께서 많은 토론을 통해 상당한 시간에 걸쳐 해석되는 경우가 많은데, AI 모델을 활용하면 완벽한 해석까진 아니더라도 틀을 빠르게 잡을 수 있겠죠.
AI 기술의 발전이 아주 많은 분야에서 활용되는 것이 놀랍군요. ㅎㅎ
9. 문법 교정 데이터셋
틀린 문법이나 오타로 이루어진 문장들과 올바른 문장들의 쌍으로 이루어진 데이터셋입니다.
이 데이터를 통해 발생하기 쉬운 오타, 문법적 오류등을 감지하고 고치는 모델을 만들 수 있습니다.

input으로 문법적으로 틀린 문장을 넣고, output으로 내보낸 문장과 실제 문장을 비교하여 학습합니다.
문법 교정 모델의 성능이 좋을수록 웹에서 크롤링해온 데이터들의 질이 좋아지겠죠.
데이터를 생성하는 측면에서 아주 중요한 모델이라고 볼 수 있겠습니다.
10. 한국어 혐오 댓글 데이터셋
한국어로 이루어진 혐오 표현이 섞여있는 데이터셋입니다.
이 데이터를 통해 상대방에게 부정적인 감정을 일으킬 수 있는 채팅, 댓글등을 판별하는 모델을 만들 수 있습니다.
위에서 설명드렸던 Hate Speech에 대한 데이터셋입니다.
차이가 있다면 한국어라는 점이겠죠.
굳이 한국어를 따로 또 설명하는 이유가 뭐냐면
한국어는 욕설이 너무 많습니다.
진짜 너무 많아요 ㅠ 사람들이 악마인건지 창의적인건지
욕설이 포함된 텍스트를 갖는 데이터셋은 스마일게이트에서도 오픈한 korean_unsmile_dataset 데이터가 대표적입니다.
저도 예전에 욕설 탐지 모델을 만들 때 참고했던 데이터이기도 합니다.
개인적인 생각으로 욕설은 유행을 많이 타는 것 같습니다.
학습 데이터의 갱신이 주기적으로 이루어지지 않으면 욕설 탐지 모델의 성능이 계속 떨어질 수 있다고 생각합니다.

제가 예전에 수집한 LCK 채팅 데이터의 일부입니다.
놀랍게도 욕설만 따로 뺀게 아니라 그냥
import pandas as pd
data = pd.read_csv(route)
data['message']로 불러오기만 한겁니다.. ㅎㅎ
여러분들은 익명성에 숨어 나쁜 말들을 하지 않길 바랍니다.
기회가 된다면 더 정교한 욕설 탐지 모델을 만들어보고 싶군요.
'
'
'
이로서 세상에는 어떤 수많은 데이터셋이 있는지에 대해 소개해봤습니다.
제가 작성한 것 외에도 수없이 많겠죠.
공개되지 않고 기업에서만 사용되는 데이터들도 아주 많습니다.
같은 모델을 사용하더라도 이후에 학습되는 고작 몇만개의 데이터로 다양한 모델을 만들 수 있다는 점이 AI 모델링의 큰 매력이 아닐까 싶습니다.
저도 취업을 한다면 많은 특이하고 재밌는 데이터들을 다뤄보고 싶습니다.
감사합니다 !
