반갑습니다.
MRC에 대해 알아볼까 합니다.
MRC는 정말 많은 분야가 존재한다고 하네요.
저는 이번에 처음 배웠습니다.
정말 어렵습니다 ㅠ
포스팅이 늦어진 이유이기도 합니다.
MRC가 뭐죠 ?
MRC란, Machine Reading Comprehension의 약자로, 주어진 지문 (Context)를 이해하고 주어진 질의(Question)의 답변을 추론하는 문제입니다.
간단히 살펴보면
Q : 용가리는 몇살이니?
Context : 용가리는 경기도에서 1999년에 태어났으며, 그는 26살의 나이에 Extraction Based MRC 모델을 일주일째 만들어 제출했으나 Baseline 코드가 40점짜리인 대회의 리더보드에 5점을 기록했다.
이라는 입력이 주어졌을 때
A : 26살
라는 정답을 내뱉는 과정을 MRC라 합니다.
MRC는 다양한 종류가 있습니다.
데이터셋을 기준으로 살펴보면
1) Extractive Answer Datasets
질의 (Question)에 대한 답이 항상 지문 안에 존재하는 데이터셋입니다.
SQuAD 1.0 데이터셋(SQuAD(Stanford Question Answering Dataset), 한국어 버전으로는 KorQuAD(Korean Question Answering Dataset)등이 있습니다.
이 경우, 정답이 반드시 지문 안에 존재하기에 지문을 잘 찾는다면(retrive) 높은 성능을 보여줄 수 있지만, 어떤 지문이든 반드시 답을 찾는다는 bias가 존재합니다.
이상한 지문을 갖다줘도 꾸역꾸역 답을 찾는다는 의미가 되겠습니다.
이런 편향을 고치기 위해 SQuAD 2.0 데이터셋은 답이 없는 경우의 데이터도 존재합니다.
SQuAD 1.0보다 어렵겠죠.
2) Descriptive / Narrative Answer Dataset
답이 지문 내에서 추출된 span이 아니라 질의를 보고 생성된 sentence의 형태를 가지는 데이터셋입니다.
무슨소리냐면
답이 어느 특정 부분의 단어가 아닙니다.
예를들어 동화책의 내용을 context로 주고 그에 대한 질문을 주었을 때 특정 부위에서의 단어가 정답이 아니라 책의 내용을 잘 요약하거나 설명하는 것이 정답이 됩니다.
context의 여러 부분을 종합적으로 판단하여 답을 내야 하기에 Extractive Answer Dataset보다 어렵다고 볼 수 있겠습니다.
이러한 특징을 갖는 데이터셋은
MS MARCO, Narrative QA 가 있겠습니다.
3) Multiple-choice Datasets
질의에 대한 답을 answer candidates(보기)에서 고르는 형태의 데이터셋입니다.
Context : 뫄뫄뫄뫄뫄뫄 ~
Question : 1) 뫄뫄 2) 뭄뫄 3) 뭄무
이런 식으로 내면 하나의 답을 고르는 형태입니다.
Multiple-choice Datasets로 학습한 모델은 오지선다 문제들이 많은 한국에서 문제를 풀 때 유용하겠군요 ㅎㅎ
이런 보기문제 데이터셋은
MCTest, RACE, ARC 등이 있겠습니다.
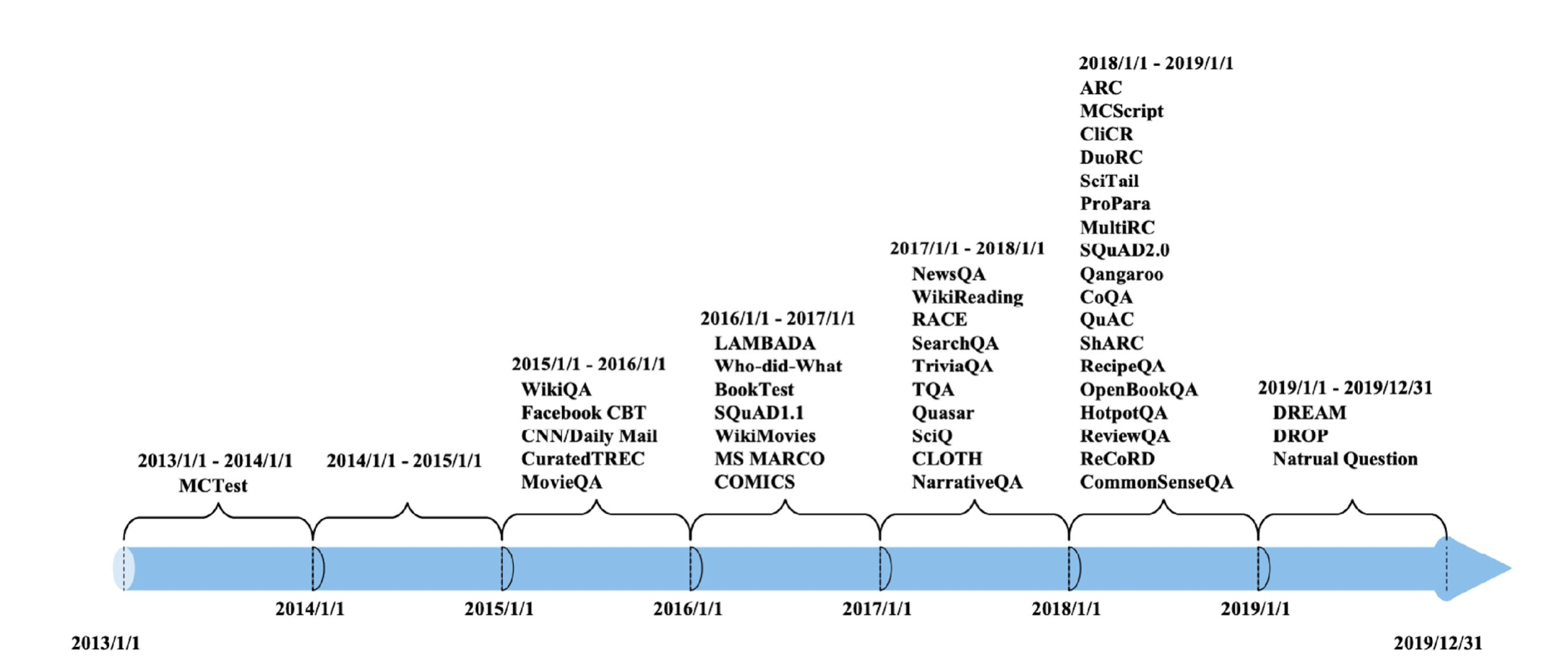
MRC 데이터셋들의 역사입니다.
시간이 지날수록 슬슬 많아지더니 2018년에는 아주 많은 양의 데이터셋이 나왔네요.
2017년에 'Attention is all you need' 논문이 나왔으니 그때부터 좀 활발해진 듯 싶습니다.
MRC의 접근법은 아주 다양합니다.
기본적인 틀을 생각해보면
사용자가 질문을 던지면 (Query) 그 질문과 관련된 문서 (Context)를 찾아서 그 문서속에서 답(Answer)을 찾아내는 형태입니다.
하지만 이 과정 하나하나에 많은 어려움이 있는데요.
어려움을 해결하는 방법들도 다양합니다.
나열해보면
- 찾아온 문서가 이상해서 답이 없다?
➡️ 답이 없다고 낼 수 있도록 하자 (SQuAD 2.0같이) - 추론을 해야 답을 얻을 수 있다?
ex) 사람은 밥을 먹어야 살아갈 수 있다. > 나는 사람이다 > 나는 밥을 먹어야 살아갈 수 있다
이런 추론과정을 통헤 답을 얻어야 할 때도 있습니다.
➡️ HotpotQA, QAngaroo 같은 추론능력을 기르는 데이터셋 활용 - 단어의 뜻은 같은데 표현이 다르다?
ex) 나는 밥을 먹는다. / 나는 맘마를 먹는다.
➡️ 단어 / 문서를 밀집 벡터로 표현하자 !
기술이 발전함에 따라 Task가 점점 어려워지고, 그 수준이 인간이 평소 사고하는 과정과 비슷한 수준의 난이도가 돼가고 있는 듯 합니다.
MRC 모델의 평가 방법
이것도 중요하죠.
MRC 모델의 어떤 면을 보고 평가를 진행해야 할까요
단답형으로 답이 딱 나오는 문제들은 Accuracy를 활용해 직관적으로 표현할 수 있겠지만 추론이 필요하거나 대답을 길게 설명해야 하는 문제들은 평가하기 쉽지 않습니다.
-
Exact Match
예측한 답과 정답이 완벽히 일치할 때 점수를 주고, 그렇지 않다면 0점을 줍니다.
-
F1 Score
예측한 답과 정답 사이의 일치 수를 통해 Recall, Precision을 계산하고, 이를 조화평균하여 F1 Score을 냅니다.
단답형이나 한두단어로 끝나는 문제들은 위와 같은 평가지표를 통해 평가할 수 있습니다.
그렇다면 정답이 아주 길다면 ??
https://velog.io/@yongari/Rouge-BLEU-Score가-뭐죠
를 통해 아실 수 있을겁니다
ㅎㅎ
'
'
'
MRC 모델에 대해 알아봤습니다.
다음 포스팅부터는 MRC 모델의 구성 요소 하나하나를 잘 설명해보도록 하겠습니다.
MRC 모델부터는 모델의 구조가 하나가 아닌 최소 2개 이상을 엮어서 구현해야 하다보니 많이 어렵고 힘듭니다.
저도 잘 안돼서 우울해요.
블로그를 작성하면서 지식을 정리하는 시간을 가져야겠습니다.
감사합니다 !
