1
(1) 1~15번
[SQLP필기풀이]4장 조인튜닝(1)-NL조인
(2) 16 ~ 37번
[SQLP필기풀이]4장 조인튜닝(2)-소트머지조인&해시조인
(3)
[SQLP필기풀이]4장 조인튜닝(3)-스칼라서브쿼리
(4) 45,46번
[SQLP필기풀이]4장 조인튜닝(4)-고급조인기법
[1] 병렬 실행계획
- 안쪽에 있는 게 Inner 테이블이다.
- 이 Inner table을 기준으로 pq_distribute 힌트를 작성한다.
[2] SQL SERVER 조인 힌트
- FROM 절에 테이블을 나열한 순으로 조인하고자 할 때 force order 힌트를 사용한다.
- NL 조인으로 유도할 때 loop join 힌트를 사용한다.
option(force order, loop join) - NL 조인으로 유도할 때 inner loop join 구문을 사용한다.
- 해시 조인으로 유도할 때 inner hash join 구문을 사용한다.
from 주문 o inner loop join 고객 c on (c.고객번호= o.고객번호) inner hash join 결제방식 t on (t.결제방식코드 = 0.결제방식코드)from 주문 o inner hash join 결제방식 t on (t.결제방식코드 = 0.결제방식코드) option(force order)
[3] 최적 인덱스 구할 때 주의할 점
- 무조건 Order by 가 있다고 부분범위 처리를 하는 건 아니다.
[4] 소트 머지 조인 힌트
- 오라클 : use_merge
- sql server
option (force order, merge join)
[5] 소트 머지 조인 특징
- ⭐️ 두번째 테이블은 무조건 따로 정렬을 수행해야함 ~!
- 양쪽 집합을 개별적으로 읽어서 정렬하므로 조인 컬럼에 인덱스가 없어도 상관 없다.
- ⭐️ 두 번째 집합은 반드시 정렬해서 PGA에 저장한 후에 조인을 시작한다.
- 첫 번째 집합도 일반적으로 PGA에 저장하지만, 조인 컬럼에 인덱스가 있어서 그것을 사용한다면 PGA 저장하지 않고 조인을 시작한다.
- ⭐️소트 머지 조인 핵심⭐️ : 대량 데이터를 조인할 때 소트 머지 조인이 NL 조인보다 유리한 이유는 데이터를 PGA 영역에 읽어 들인 후 조인하기 때문이다.
[6] 해시 조인 특징
- swap_join_inputs 힌트가 없으면 leading이나 ordered 힌트에 기재된 첫번째 테이블이 무조건 build input 테이블이 된다.
- 해시 조인도 조인 프로세싱 자체는 NL 조인과 같지만, 건건이 Inner 집합을 버퍼캐시에서 탐색하지 않고 PGA에 미리 생성해 둔 해시 테이블(해시 맵)을 탐색하면서 조인한다는 점이 다르다.
⭐️해시 맵을 이용하므로 조인 컬럼에 인덱스가 없어도 상관 없다.⭐️ - 28번
해시 알고리즘 특성상 한 체인에 여러 개 값이 연결될 수 있는 구조이며, 각 해시 체인에 연결된 값이 많을수록 해시 맵 탐색 효율은 나빠진다.
[7] 해시 조인 힌트 작성법
- 32번,33번,34번,35번,36번
- 해시 조인 순서랑 build input과 Inner 테이블의 관계를 자꾸 헷갈려한다 ㅠㅠ
- 여러 개 테이블이 해시조인할 때는 swap_join_inputs 힌트로 inner 테이블을 분명히한다.
- 해시 조인 힌트 문제를 쓸 땐 인덱스를 적어주도록 한다.(?)
[8] 스칼라 서브쿼리 특징
- 38번
- ⭐️ 조인으로 변환한다고 무조건 아우터 조인은 아니다.ERD를 보거라 !!!!
ERD도 PK를 보는 게 아니라 관계 선을 보아야 한다. ⭐️
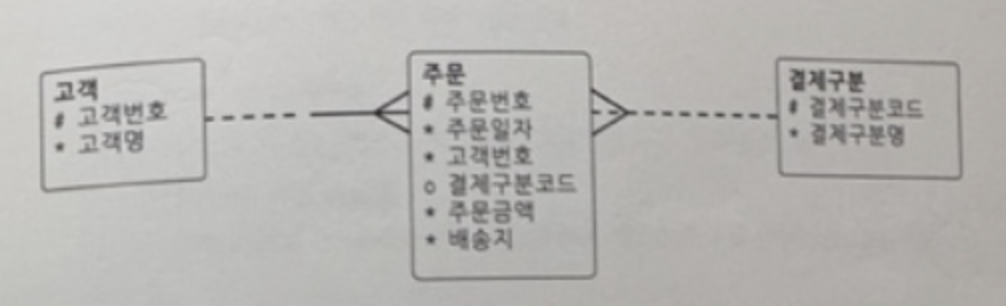
- 주문은 고객을 '꼭' 가지고 있다.
- 또한 성능을 위해서 가급적 Outer 조인보다 Inner 조인을 사용하는 것이 좋다.
[9] ERD 관계선 꼭 알아둘 것
- 주문은 고객을 '꼭' 가지고 있다.
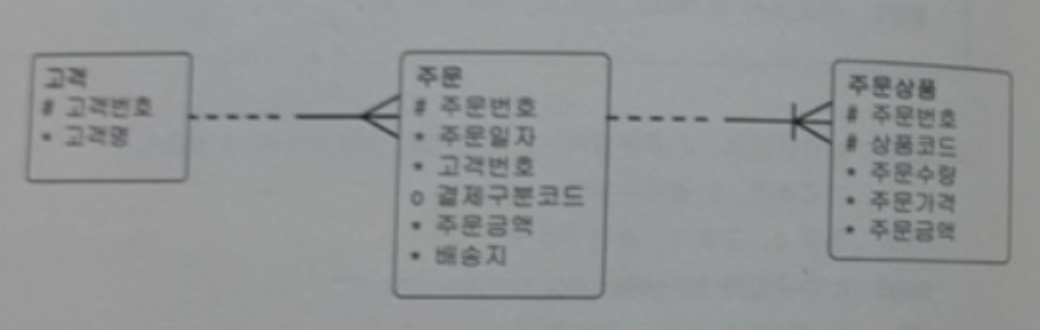
- 주문은 고객을 '꼭' 1개씩 가지고 있다.
- 주문상품은 주문을 '꼭' m:1의 관계로 가지고 있다.
2
(1) 1 ~ 16
[SQLP필기풀이]5장 SQL옵티마이저(1)-SQL옵티마이징 원리
(2) 17 ~ 25
[SQLP필기풀이]5장 SQL옵티마이저(2)-SQL공유 및 재사용
(3) 26 ~ 45
[SQLP필기풀이]5장 SQL옵티마이저(3)-쿼리 변환
[1] ⭐️ 파티션된 테이블 DML 튜닝시 유의점
- ⭐️ 파티션된 테이블 안에서 인덱스 검색시 10% 비중이 넘어가면 그 때는 인덱스가 아니라 FULL SCAN을 실행한다.
[2] ⭐️ 인라인뷰 DML 튜닝시 유의점
[SQLP실기풀이]4장 조인튜닝(4)-고급조인기법 50번
- ⭐️ 인라인 뷰 안에 정렬되어있던 데이터들이 흩어지지 않도록 외부에서 다시한번 Order by를 수행한다.
[3] 비용기반 옵티마이저의 한계
[SQLP필기풀이]5장 SQL옵티마이저(1)-SQL옵티마이징 원리
- 기본적으로 캐싱 효과를 고려하지 않는다. 즉, 모든 블록을 디스크에서 읽는다고 가정하고 디스크 I/O Call 횟수로 실행계획을 선택하는 것은 "오라클 비용기반 옵티마이저의 한계"이다.
- 규칙기반 옵티마이저만의 단점이라고 할 수 없다.
[4] 스스로 학습하는 옵티마이저
- (Self-Learning Optimizer)
Adaptive Cursor Sharing- 처음 실행 시 특정 실행계획으로 실행했다가 바인드 변수에 다른 값이 입력됐을 때
'예상보다 많은 I/O'가 발생하면 다른 실행계획을 추가로 생성 - 이후로 바인드 변수 값 분포에 따라 다른 실행계획을 선택적으로 사용하는 기능
- 처음 실행 시 특정 실행계획으로 실행했다가 바인드 변수에 다른 값이 입력됐을 때
Cardinality Feedback또는Statistics Feedback- 최초 실행계획을 수립할 때 추정했던 카디널리티와 '실제 실행 과정에 읽은 로우 수 간에 차이'가 크다고 판단되면, 조정된 카디널리티 값을 어딘가에 저장해 두었다가 다음번 실행 시에 그것을 사용함으로써 다른 실행계획이 수립되도록 하는 기능이다.
Adaptive Plans- 런타임에 실행계획을 변경
[5] 옵티마이저의 한계
- 시간과 공간을 헷갈리지 말 것 !!! ⭐️
- ⭐️라이브러리 캐시 공간의 크기⭐️는 옵티마이저가 생성하는 실행계획에는 영향을 주지 않는다.
- 다만, 공간이 부족하면 SQL 실행계획이 캐시에서 자주 밀려나므로 파싱과 최적화를 자주 수행함으로 인한 부하가 늘어날 뿐이다.
- ⭐️최적화 시간에 허용된 시간 제약⭐️은 옵티마이저의 한계가 맞다.
[6] I/O 비용 모델 vs. CPU 비용 모델
- I/O 비용 모델의 비용은 예상되는 블록 개수가 아니라 디스크 I/O Call 횟수다.
- CPU 비용 모델에서 비용(Cost)
- 예상 I/O 시간과 예상 CPU 사용시간을 구한 후 Single Block I/O 시간으로 나눈 값이다.
- IO요청 횟수에 시간을 더해 비용을 산정하여 실행계획을 평가한다.
- Single Block I/O에 소요되는 시간과의 상대적인 시간을 표현
- 예를 들어, 실행계획 상 Cost가 100으로 표시됐다면, “우리 시스템에서 100번 Single Block I/O 하는 정도의 시간이 소요될 것으로 옵티마이저가 예상한다"는 뜻이다.
[7] 오라클 히스토그램 유형
■ 도수분포(Frequency) : '값별로 빈도수' 저장
■ 상위도수분포(Top-Frequency) : 많은 레코드를 가진 상위 n개 값의 '빈도수' 저장
■ 높이균형(Height-Balanced) : 각 버킷의 높이가 동일하도록 데이터 분포 관리
■ 하이브리드(Hybrid) : 도수분포와 높이균형 히스토그램의 특성을 결합
[8] 인덱스를 이용한 테이블 액세스 비용
⭐️비용⭐️
= 브랜치 레벨+(클러스터링 팩터 x 유효 테이블 선택도)+(리프 블록 수 x 유효 인덱스 선택도)
[9] 바인드 변수
- 키워드 : ⭐️최적화⭐️
- 바인드 변수를 사용하면 최적화 과정에 컬럼 히스토그램을 사용하지 못한다.
- 조건절에 상수 값을 사용하면 컬럼 히스토그램을 사용할 수 있어 SQL 최적화에 도움이 된다.
[10] 라이브러리 캐시 최적화 방안
- 동시 과도한 파싱 부하 > 해결 : 커서 캐싱 또는 커서 공유
- open_cursors 파라미터는 세션 당 Open 할 수 있는 커서 개수를 '제한'하는 파라미터다. 즉 , 세션 커서 캐싱,애플리케이션 커서 캐싱에서의 '커서'와는 상관없다.
[11] 서브쿼리 unnesting 실행계획
-

-
unnest문은 인라인뷰가 아닌 서브쿼리에서 나온다.(예를들어 Exists문)
-
서브쿼리 unnest를 안 했을 때 (조인 안했을 때) : Filter 문이 나온다.
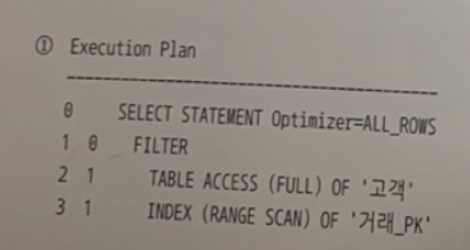
-
서브쿼리 unnest를 했을 때 (조인 했을 때)
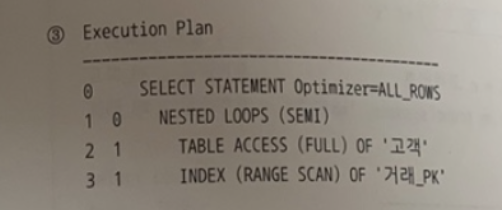
-
- UNNEST(@subq) LEADING(거래@subq) use_nl(c)
[12] 서브쿼리 인라인 뷰
- 인라인 뷰를 Merging 하면 부분범위 처리가 불가능하다.
- 부분범위 처리를 이용해서 빠른 응답 속도를 내고 싶다면, ⭐️ 뷰를 Merging 하지 않은 상태에서 고객을 기준으로 인라인 뷰 집합과 NL 방식으로 조인 ⭐️하면 된다.
- 35번
- no_merge 서브쿼리는 실행계획에 VIEW가 나온다.
- no_merge 서브쿼리는 실행계획에 VIEW가 나오고 인덱스를 잘 살펴봐야한다.
- push_pred 여부를 잘 따져야한다.
[13] 힌트 정리
use_concat: ‘CONCATENATION' 오퍼레이션을 통해 OR Expansion이 작동no_merge: 인라인뷰 따로 수행- 실행계획에 'VIEW' 생김
- push_pred 힌트 같이 쓸 수 있음
merge: 인라인뷰 합침- 실행계획에 'VIEW' 있으면 안 됨
- push_pred 힌트 같이 쓸 수 없음
no_unnest: 서브쿼리 따로- 실행계획에 'Filter' 있음
unnest: 서브쿼리를 조인문으로 합침- 실행계획에 '조인' 있음 (세미 , 해시 , NL 노상관)
- nl_sj , hash_aj 등등 많이 씀
내일 : 33번
3
(1) [SQLP필기문제]3장 인덱스 튜닝-인덱스 기본 원리
(1) [SQLP필기풀이]3장 인덱스 튜닝(2)-테이블액세스최소화1
[1] ⭐️ 파티션된 테이블 DML 튜닝시 유의점
- ⭐️ 파티션된 테이블 안에서 인덱스 검색시 10% 비중이 넘어가면 그 때는 인덱스가 아니라 FULL SCAN을 실행한다.
[2] DECODE문 문법
SELECT 작업일련번호 , 작업자ID ,
DECODE(작업구분코드,'A','개통','B','장애') 작업구분 ,
DECODE(작업구분코드,'A',B.고객번호,'B',C.고객번호) 고객번호 ,
DECODE(작업구분코드,'A',B.주소,'B',C.주소) 주소
FROM 작업지시 A , 개통접수 B , 장애접수 C
WHERE A.방문예정일자 = TO_CHAR(SYSDATE, 'YYYYMMDD')
AND B.개통접수번호(+) = DECODE(작업구분코드,'A',A.접수번호)
AND C.장애접수번호(+) = DECODE(작업구분코드,'B',A.접수번호);[3] 인덱스 수직 액세스와 unique 스캔 관계
- 무조건 수직 액세스라고 해서 Index Unique 스캔은 아니다.
[4] 인덱스 Skip scan 가능 여부
- 중간에 꼭 인덱스 요소가 빠지지 않아도 skip scan은 가능하다.
- 퐁당퐁당이 가능한지 머릿속으로 그려보면 된다.(중간을 건너뛰는지)
- 즉 , 모두 액세스 조건이 되면 Index_ss는 안된다.
[5] 테이블 랜덤 액세스 부하 줄이기
- IOT : 리프블록에 다 있다.
- 파티션 : FULL SCAN으로 부분 테이블을 다 읽어버린다.
- 클러스터 : 같은 키 값(DEPTNO)을 갖는 레코드들이 서로 같은 블록안에 모여있다.
[6] 힌트를 사용하지 않고도 Index Range Scan이 가능한 경우
- OR 조건은 기본적으로 Index Range Scan을 위한 액세스 조건으로 사용할 수 없다. OR 조건으로는 수직적 탐색을 통해 스캔 시작점을 찾을 수 없기 때문이다.
- 다만,CONCATENATION(옵티마이저에 의한 UNION ALL 분기)으로 처리했을 때 각각 수직 탐색을 위한 액세스 조건으로 사용할 인덱스가 있다면, Index Range Scan이 가능하다.
[7] 힌트를 사용해서까지 Index Range Scan을 해야하는 경우
- IN절이나 OR절에서 꼭 Index Range Scan을 유도하려고한다면 UNION ALL을 이끌어내야한다.
- ⭐️ use_concat 힌트 사용 !! ⭐️
[8] 인덱스 스캔 과정에서 비효율이 가장 큰 조건절
- 스캔하는 양이 많으면 비효율적 , 적으면 효율적이 절~대 아니다.
[1] ⭐️ 서브쿼리는 캐싱 기능이 있다.
- 테이블 액세스를 막기 위해 상품분류코드+상위분류코드로 구성된 인덱스를 추가했다.하지만 상품분류는 데이터가 소량이어서 필터 과정에 캐싱 기능이 효과적으로 작동하고 있으므로 ⭐️굳이 인덱스를 추가할 필요가 없다.⭐️
[2] push_subq 힌트 사용
- unnesting 되지 않는 서브쿼리를 먼저 수행하고 싶을 때 사용한다.
4
[1] no_unnest 힌트 사용하는 곳
[SQLP실기풀이]4장 조인튜닝(3)-스칼라서브쿼리 44번
- Exists 서브쿼리
- 스칼라 서브쿼리
[2] 자주 사용하는 힌트 목록
✅ 자주 사용하는 힌트 목록


[3] 버퍼캐시 히트율
✅ 버퍼캐시 히트율(Buffer Cache Hit Ratio, BCHR)을 구하는 공식
BCHR = ( 캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수 ) × 100
= ( (논리적 I/O - 물리적 I/O) / 논리적 1/0) ×100
= ( 1 - (물리적 1/0) / 논리적 I/O)) × 100
- 논리적 I/O는 SQL 수행 과정에 읽은 총 블록수
⭐️ query 항목(=Consistent 모드로 읽은 블록 수)과 current 항목(=Current 모드로 읽은 블록 수)을 더해서 구한다.⭐️ - 읽고자 하는 블록을 먼저 캐시에서 찾고, 못 찾으면 디스크에서 읽는다. 따라서 논리적 1/O 횟수에는 물리적 I/O 횟수가 이미 포함돼 있다
5
[1] 튜닝 쿼리에 괄호가 너무 많으면 줄여야 한다.
[SQLP실기풀이]4장 조인튜닝(4)-고급조인기법 52번
- index fast full scan의 경우 그냥 해시조인하고나서 group by 해도 괜찮다.
- group by 를 하기 위해 서브쿼리로 한번 더 감싸서 2개 이상의 괄호를 만들지 말고 그냥 합칠 것 !
[2] NVL2문과 DECODE문
[SQLP실기풀이]4장 조인튜닝(4)-고급조인기법 53번
- nvl2문 : NVL2 함수는 NULL이 아닌 경우 지정값1을 출력하고, NULL인 경우 지정값2를 출력한다.
NVL2("값", "지정값1", "지정값2")
NVL2("값", "NOT NULL", "NULL") - decode문
DECODE(컬럼, 조건1, 결과1, 조건2, 결과2, 조건3, 결과3..........) [3] 조건 구분값에 따라 조인 대상 테이블이 바뀔 때
[SQLP실기풀이]4장 조인튜닝(4)-고급조인기법 53번
- union all을 이용한다.
- 문제 조건 값을 꼭 읽어라!!( 이건 힌트 사용과 인덱스 재구성을 못하게 했다.)
[4] 오라클 AutoTrace에서 확인할 수 있는 정보
✅ 오라클 AutoTrace에서 확인할 수 있는 정보
- 예상 실행계획
- 실제 디스크에서 읽은 블록 수
- 실제 기록한 Redo 크기
- ⭐️ 오라클 AutoTrace에서 실제 사용한 CPU Time은 알 수 없다.

✅ 오라클 기본 Trace에서 확인할 수 있는 정보
- 예상 실행계획
- 실제 디스크에서 읽은 블록 수
- 실제 사용한 CPU Time
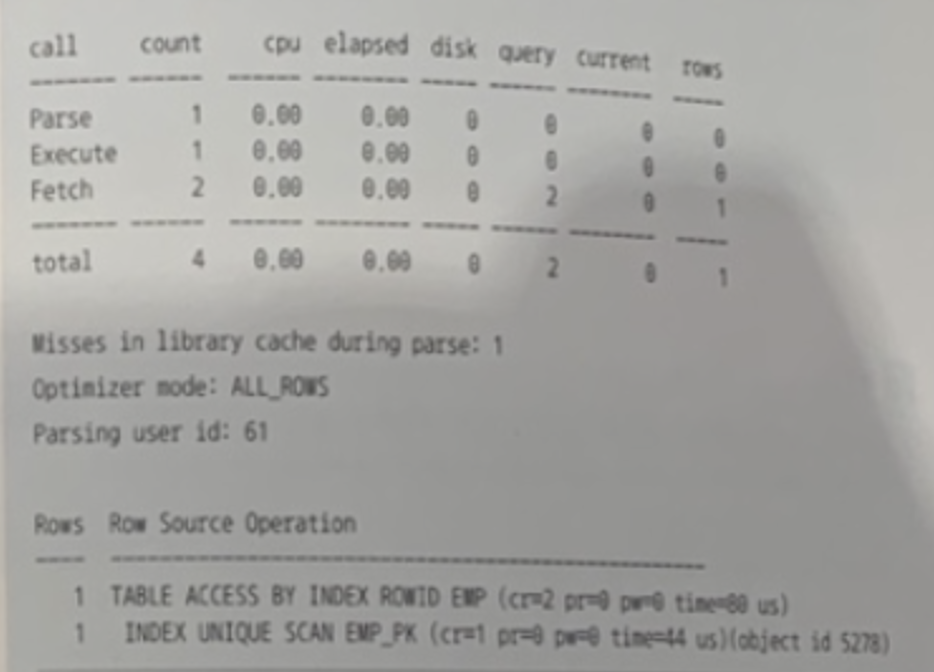
- 오라클의 기본 SQL 트레이스(10046 트레이스)에서 실제 기록한 Redo 크기는 알 수 없다.
- autotrace에서는 실제 사용한 CPU Time을 알 수 없고 오라클의 기본 SQL 트레이스에서는 실제 기록한 Redo 크기를 알 수 없다.
[5] 오라클 AutoTrace에서 사용할 수 있는 옵션
✅ AutoTrace에서 사용할 수 있는 옵션
[키워드 다섯가지를 조합하는 것이다.]
- 공통 문법 : set autotrace
- 선택 문법1(결과출력 여부)
- 결과 출력 : on
- 결과 미출력 : traceonly
- 선택 문법2(실행계획/실행통계)
- 실행계획 : explain
- 실행통계 : statistics
[결과 출력 O (당연히 SQL 실행)]
- set autotrace on
- SQL을 실행
- 결과집합 있음
- 예상 실행계획 및 실행통계를 출력
- set autotrace on explain
- SQL을 실행
- 결과집합 있음
- 예상 실행계획을 출력
- set autotrace on statistics
- SQL을 실행하고
- 결과집합 있음
- 실행통계를 출력
[결과 출력 X]
- set autotrace traceonly
- SQL을 실행하고
- 결과는 출력하지 않고
- 예상 실행계획과 실행통계 출력
- set autotrace traceonly explain
- ⭐️ SQL을 실제로 실행하지 않고
- 예상 실행계획만 출력
- set autotrace traceonly statistics
- SQL을 실행하고
- 결과는 출력하지 않고
- 실행통계만 출력
[6] 오라클 SGA 메모리에 기록한 SQL 트레이스 정보를 출력하기
- SQL에 gather_plan_statistics 힌트를 지정하면, SQL 트레이스 정보를 서버 파일이 아닌 SGA 메모리에 기록한다.
- SGA 메모리에 저장된 트레이스 정보를 dbms_xplan.display_cursor 함수를 이용하면 분석하기 쉬운 형태로 포매팅해 준다.
- 첫 번째와 두 번째 인자에는 SQL 커서의 ID와 CHILD_NUMBER를 입력해야 한다.
- 첫 번째와 두 번째 인자에 null, null을 입력하면 바로 직전에 수행한 커서 ID와 CHILD_NUMBER를 내부에서 자동 선택해 준다.
[7] _DBMS_XPLAN.DISPLAY_CURSOR와 SQL 트레이스 항목 비교
✅ _DBMS_XPLAN.DISPLAY_CURSOR 함수를 통해 추출한 SQL 트레이스 정보
- Starts : 각 오퍼레이션 단계별 실행 횟수
- E-Rows : 옵티마이저가 예상한 Rows
- A-Rows : 각 오퍼레이션 단계에서 읽거나 갱신한 로우 수
- SQL 트레이스 항목에서는 rows
- A-Times : 각 오퍼레이션 단계별 소요시간
- SQL 트레이스 항목에서는 times
- Buffers : 캐시에서 읽은 버퍼 블록 수
- SQL 트레이스 항목에서는 query(=cr) , current
- Reads : 디스크에서 읽은 블록수
- SQL 트레이스 항목에서는 pr
[8] sql server에서 SQL 트레이스 옵션
✅ sql server에서 SQL 트레이스를 확인하고자 설정하는 옵션
- 공통 문법 : set statistics ? on
- 선택 문법
- profile
- io
- time
- 선택 문법2(실행계획/실행통계)
- 실행계획 : explain
- 실행통계 : statistics
- set statistics profile on
- 각 쿼리가 일반 결과집합을 반환하고 그 뒤에는 쿼리 실행
- 프로필을 보여 주는 추가 결과집합을 반환
- 출력에는 다양한 연산자에서 처리한 행 수 및 연산자의 실행 횟수에 대한 정보도 포함
- set statistics io on
- Transact-SQL 문이 실행되고 나서 해당 문에서 만들어진 디스크 동작 양에 대한 정보를 표시
- set statistics time on
-각 Transact-SQL 문을 구문 분석, 컴파일 및 실행하는 데 사용 한 시간을 밀리초 (0.001초) 단위로 표시
[9] 대기이벤트
- 프로세스가 버퍼캐시, 라이브러리 캐시 등 공유 메모리에서 래치를 획득할 때마다 나타난다. 👉 ❌
- 래치를 획득하는 과정에 경합이 발생하면 대기 이벤트가 나타나지만, 경합없이 바로 읽으면 대기 이벤트가 나타나지 않는다.
- library cache lock , library cache pin 대기이벤트는 주로 SOL 수행 도중 DDL을 수행할 때 나타난다.
- free buffer waits 대기 이벤트는 서버 프로세스가 버퍼 캐시에서 Free Buffer를 찾지못해 DBWR에게 공간을 확보해 달라고 신호를 보낸 후 대기할 때 나타난다.
- log file sync 대기 이벤트는 커밋 명령을 전송받은 서버 프로세스가 LGWR에게 로그 버퍼를 로그 파일에 기록해 달라고 신호를 보낸 후 대기할 때 나타난다.
- Latch: shared pool 대기 이벤트는 shared pool 래치를 할당받는 과정에 발생하는 경합과 관련 있으며, 하드 파싱을 동시에 심하게 일으킬 때 주로 나타난다.
[10] 인스턴스 효율성 항목들
- Soft Parse : 실행계획이 라이브러리 캐시에서 찾아져 하드파싱을 일으키지 않고 SQL 을수행한 비율이다. 구하는 공식은 아래와 같다.
(전체 Parse Call 횟수 - 하드파싱 횟수) / (전체 Parse Call 횟수)* 100 - Execute to Parse : Parse Call 없이 곧바로 SQL을 수행한 비율, 즉 커서를 애플리케이션에서 캐싱한 채 반복 수행한 비율이다.
- Parse CPU to Parse Elapsed : 파싱 총 소요 시간 중 CPU time이 차지한 비율이다. 파싱에 소요된 시간 중 실제 일을 수행한 시간 비율을 말하며, 이 값이 낮다면 파싱 도중 대기가 많이 발생했음을 의미한다.
6
(1) [SQLP필기풀이]3장 인덱스 튜닝
(2) [SQLP필기풀이]4장 조인 튜닝
[1] 선분이력으로 조인해서 가져오기
[SQLP실기풀이]4장 조인튜닝(4)-고급조인기법 60번
- 직전 종료일자에 -1초를 배서 로우수를 하나로 만들어 조인처리해 가져오도록 한다.
- 이렇게 하면 부분범위처리하는 서브쿼리를 따로 만들지 않아도 된다.
[2] Index Skip Scan
▶ 인덱스 구성 : 할인구분코드 + 상품코드 + 업체코드 + 상품유형코드
SELECT 주문일자, 상태코드, 정상가, 할인가, 할인구분코드
FROM 상품공급
WHERE 상품유형코드 = 'A'
AND 업체코드 = '2956'
AND 상품코드 = 'A0113509056'
AND 할인구분코드 BETWEEN 'A' and 'C'
ORDER BY 주문일자 DESC- 선두 컬럼의 NDV 는 적고 후행 컬럼의 NDV는 많을 때 BETWEEN 조건의 인덱스 선두 컬럼을 IN 조건으로 변경하면 성능 향상에 큰 도움이 된다.
[3] 동적 SQL
SELECT * FROM 거래
WHERE 고객ID LIKE #CUST_ID# || '%'
AND 거래일자 BETWEEN #OT1# AND #DT2#- 고객ID가 NULL이면 AND 거래일자 BETWEEN #OT1# AND #DT2# 조건절만 적용되게 만들고 싶은 건데
이 때 . 고객ID가 선두 컬럼인 인덱스를 Range Scan 하는 실행 계획이 수립되면, #CUST_ID 변수에 값을 입력하지 않았을 때 인덱스에서 '모든' 거래 데이터를 스캔하는 불상사가 생긴다.
[4] 클러스터 정의
- 클러스터는 값이 같은 레코드를 한 블록(데이터가 많을 경우 연결된 여러 블록)에 모아
서 저장한다.
[5] or 조건절이 있지만 Index Range Scan이 가능한 경우
- OR 조건은 기본적으로 Index Range Scan을 위한 액세스 조건으로 사용할 수 없다.
- OR 조건으로는 수직적 탐색을 통해 스캔 시작점을 찾을 수 없기 때문이다.
- 다만,CONCATENATION(옵티마이저에 의한 UNION ALL 분기)으로 처리했을 때 ⭐️각각⭐️ 수직 탐색을 위한 액세스 조건으로 사용할 인덱스가 있다면, Index Range Scan이 가능하다.
[6] ⭐️ use_concat 주의할 점
- ⭐️ use_concat 힌트는 or절이 있는 SQL에 써야하는것이다.
- 그냥 in절만 있는 경우는 in list로 풀리겠지만 이에 use_concat을 쓰면 안된다!!!
- in list 변환도 union all 로 처리된다.
[7] merge 조인
- merge 조인 힌트에도 순서랑 대상 테이블을 정한다.
- 소트 머지 조인이 빠른 이유는 첫 번째 집합을 기준으로 두 번째 집합을 반복 액세스할때는
⭐️ 버퍼캐시를 탐색하지 않고 PGA에서 데이터를 읽기 때문이다.⭐️ - ⭐️ 따라서 두 번째 집합은 반드시 정렬해서 PGA에 저장한 후에 조인을 시작한다.⭐️
- 첫 번째 집합도 일반적으로 PGA에 저장하지만, ⭐️ 조인 컬럼에 인덱스가 있어서 그것을 사용한다면 PGA 저장하지 않고 조인을 시작한다. ⭐️
[8] 해시 조인 튜닝 핵심
- ⭐️ 해시 체인이 일어나지 않도록 조건절을 바꾸는 것 !
7
(1) [SQLP필기풀이]5장 SQL옵티마이저(1)-SQL옵티마이징 원리
(2) [SQLP필기풀이]5장 SQL옵티마이저(2)-SQL공유 및 재사용
(3) [SQLP필기풀이]5장 SQL옵티마이저(3)-쿼리 변환
[1] unnest를 해야 조인이 가능해진다.
- 서브쿼리에 unnest를 써야지 조인이 가능해진다!!
- no_unnest를 쓰면 조인처리는 안되고 필터처리가 된다.
- ⭐️ rownum이 있으면 unnest되지 않는다.
[2] 인덱스를 이용한 테이블 액세스 비용
비용 = 브랜치 레벨+(클러스터링 팩터 x 유효 테이블 선택도)+(리프 블록 수 x 유효 인덱스 선택도)
- 브랜치 블록 수는 비용 공식에 포함되지 않을 뿐만 아니라 통계정보로 미리 수집해 두지도 않는다.
[3] 서브쿼리 쿼리 블록
- UNNEST(@subq) LEADING(거래@subq) use_nl(c)
[4] 어김없이 틀림
[5] 실행계획에 VIEW 존재여부 꼭 확인하기
- 실행계획에 VIEW가 없으면 조건절 push down은 일어나지 않는다.
- 또한 조건절 push down이 일어나면 실행계획에 VIEW PUSH PREDICATE가 나온다.
- 근데 없다 ? 그럼 쿼리 변환이 일어난 것이다 !! 즉, ⭐️ 쿼리 변환이 일어나면 실행계획에 안 나온다 . ⭐️
8
