[GDSC/ML] CLIP 이해를 위한 Transformer & GPT 리뷰📎

Improving Language Understanding by Generative Pre-Training 정리
CLIP 참고 영상
CLIP: Connecting Text and Images
Traditional Supervised Image Classifiers
한계
- Fine-Tuning 없이 새로운 downstream task에 적용하기 어려움 -> 모델의 일반화 한계
- 새로운 downstream task에 적합한 다량의 이미지와 레이블링 작업 필요
- 이미지 수집 및 정답 레이블 생성에 많은 인력과 비용 요구
- 벤치마크 데이터셋 성능과 실제 현실에서 수집한 데이터셋 성능과는 차이 존재
- 벤치마크 데이터셋에 최적화되어 그 외 데이터셋에서는 저조한 성능을 보임
What We Need
- Fine-tuning이 필요 없는 일반화된 모델
- 이미지 수집 및 정답 레이블 생성에 적은 노력이 드는 모델
- 벤치마크 데이터셋과 현실 데이터셋에서 좋은 성능을 보이는 강건한 모델
CLIP : Contrastive Language-Image Pre-training
Using Image-Text Pair
CLIP은 이미지와 이미지를 설명하는 텍스트를 결합한 image-text pair를 입력으로 사용
-> 이미지와 언어에 대한 representation을 함께 학습하여 일반화된 특징 학습 가능
Creating a sufficiently large dataset

Selecting an efficient pre-training method
Image captioning과 같은 모델 사이즈가 크며 학습 및 예측 시간이 길어 비효율적인 방법 대신
Contrastive learning을 적용하여 pre-training 진행
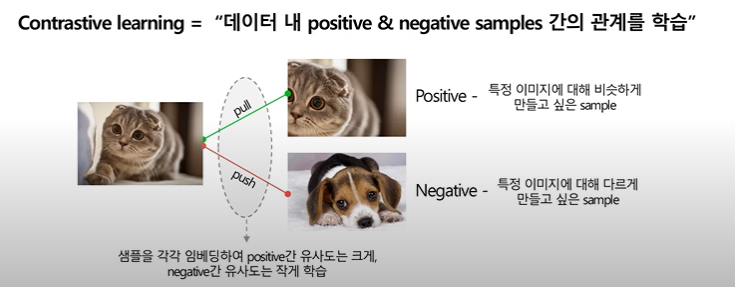

CLOVA 논문 리딩했던 CLUE에도 Contrastive Learning이 Keyword였다
CLUE 논문 리뷰
-> 한 번도 본 적 없는 특정 하위 문제의 데이터셋에 대해 예측을 수행하는 Zero-shot prediction에서도 우수한 성능
Methodology
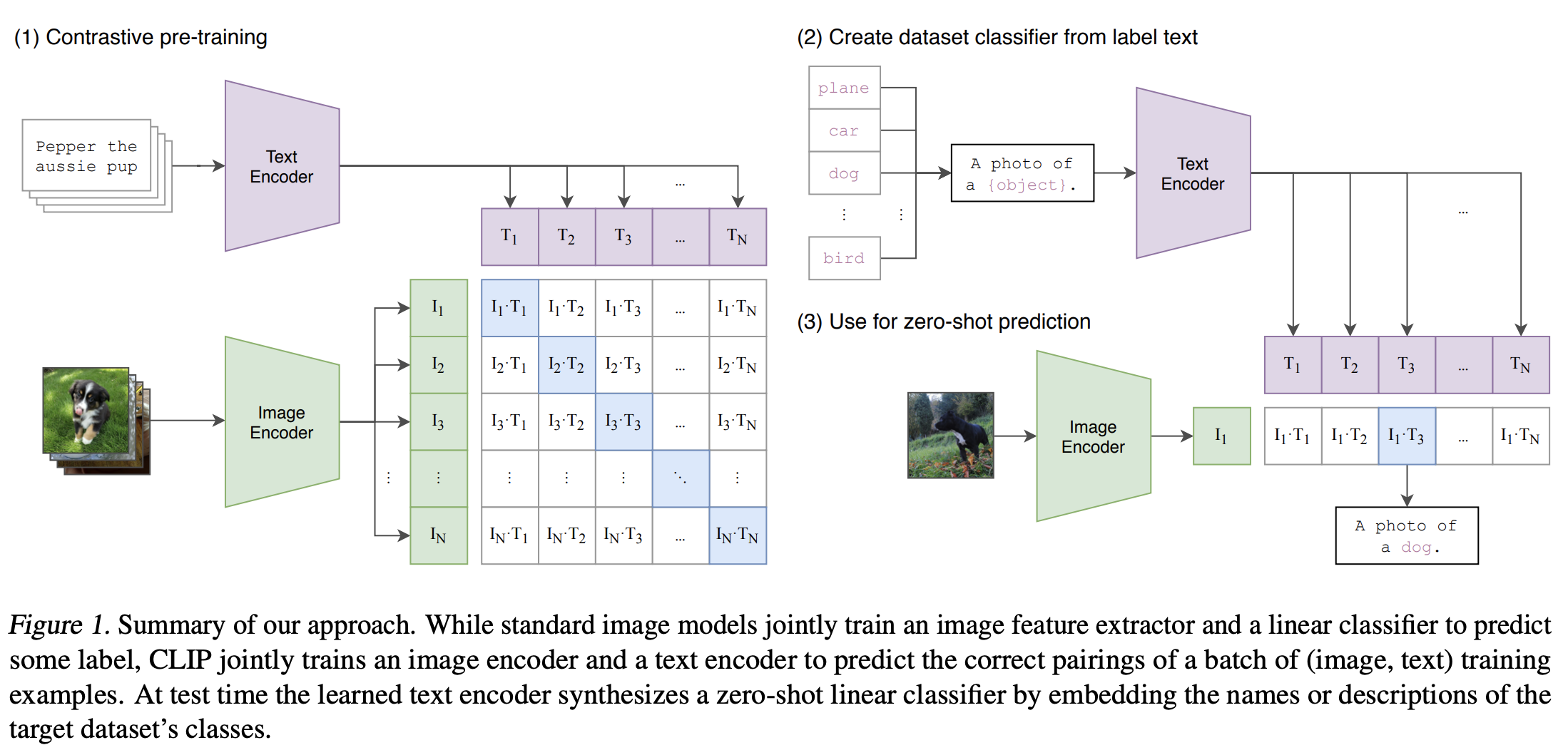
Contrastive pre-training
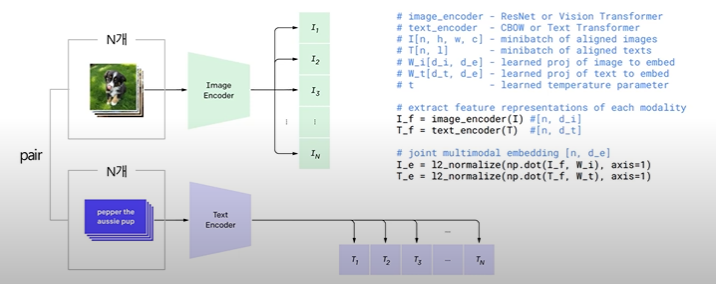
배치 단위로 이루어진 N개의 이미지와 텍스트를 각각 인코더에 통과시켜 임베딩 벡터 산출
- Image Encoder : Modified ResNet / Vision Transformer
- Text Encoder : Transformer
이미지와 텍스트 벡터 간의 내적을 통해 코사인 유사도 계산
- Pair에 해당하지 않는 이미지 혹은 텍스트는 서로 다르다는 전제 하에 cross-entropy loss 계산


Create dataset classifier from label text
- 적용하고자 하는 특정 하위 문제의 데이터셋 레이블을 텍스트(구)로 변환
- 이후 학습된 텍스트 인코더에 통과시켜 텍스트 임베딩 벡터값 산출
Use for a zero-shot prediction
- 예측하고자 하는 이미지를 학습된 이미지 인코더에 통과시켜 이미지 임베딩 벡터값 산출
- 텍스트 임베딩 벡터와 코사인 유사도를 계산하여 상대적으로 높은 값을 갖는 텍스트 선택
Fine-Tuning 과정 없이도, 처음 보는 이미지에 대해 예측 가능
