
생성형 AI(Generative AI)는 기존 데이터를 학습해 새로운 데이터를 생성하는 인공지능 기술입니다.
이 기술은 텍스트, 이미지, 음성, 영상 등 다양한 형태의 콘텐츠를 창의적으로 만들어낼 수 있습니다.

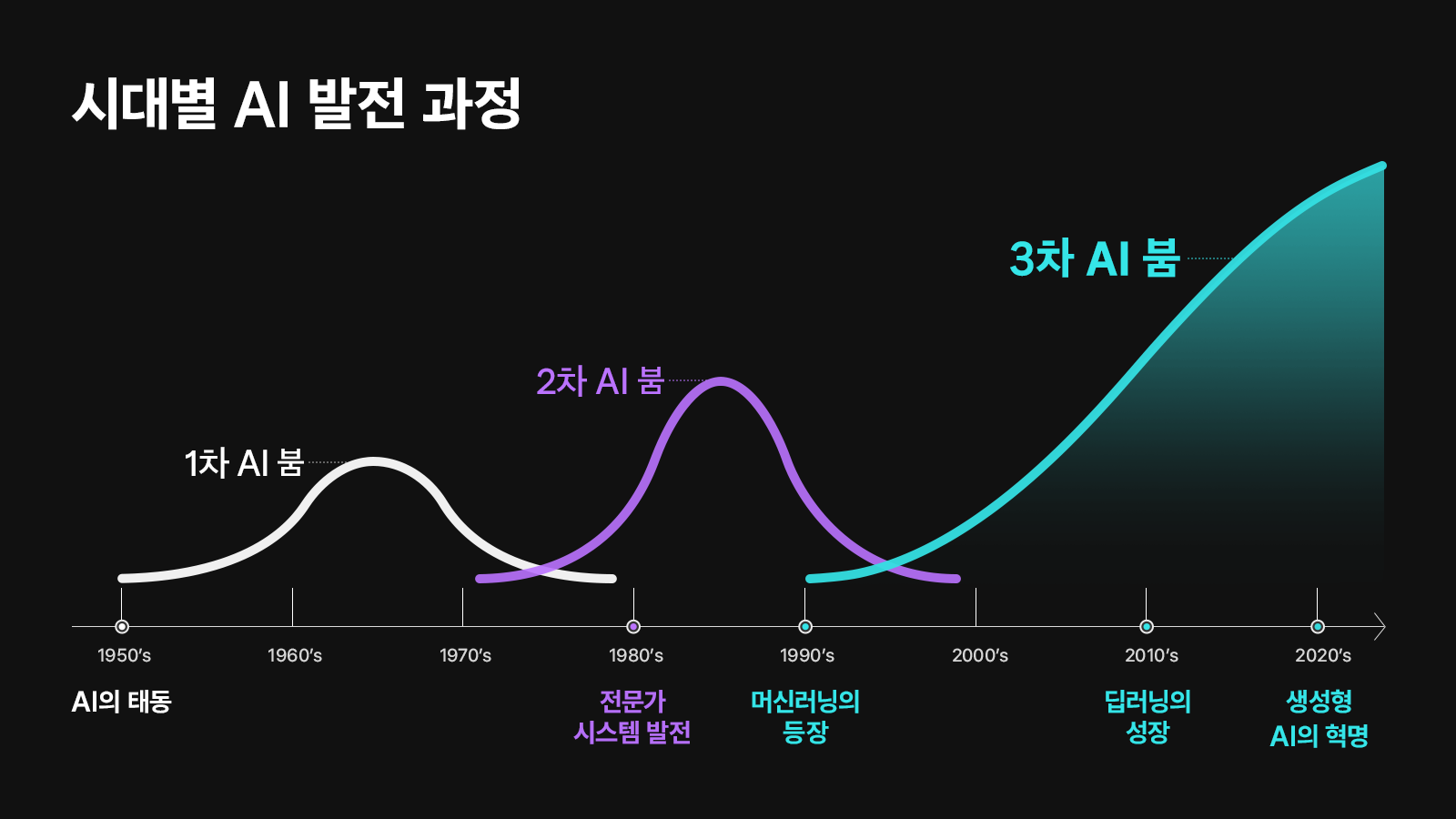
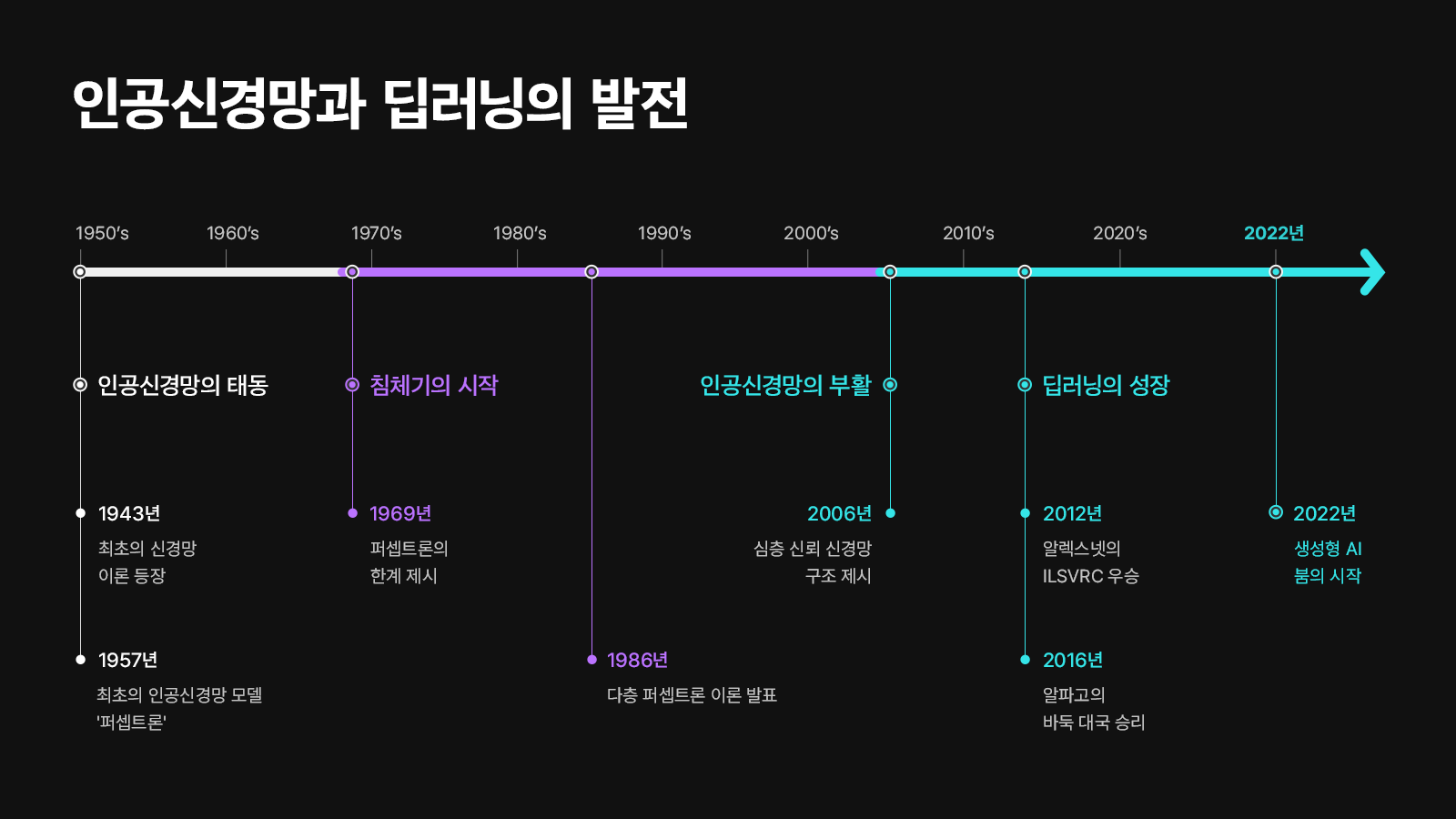
📍AI 발전 과정
SK 하이닉스 블로그(AI의 시작과 발전 과정, 미래 전망)
📍 LLM (Large Language Model) — 대규모 언어 모델
LLM은 대량의 텍스트 데이터를 학습하여 자연어(사람들이 일상적으로 사용하는 언어)를 이해하고 생성하는 딥러닝 모델입니다.
- 대표 모델: GPT 시리즈, PaLM, Claude, LLaMA, Mistral 등
- 기반 구조: Transformer (Vaswani et al., 2017)
🔧 작동 원리
- 입력 텍스트를 받아들임
- 다음에 올 단어의 확률을 예측
- 문장/문단/코드/지식 등의 텍스트를 생성
“오늘 날씨가” → LLM은 그 다음 단어로 “좋다”를 높은 확률로 생성할 수 있습니다.
🌟 특징
- 자연어 처리의 범용 엔진 (요약, 번역, 질의응답 등)
- 확률적 텍스트 생성기 (문장의 일관성과 문법 유지)
- 수십억~수조 개의 파라미터 보유 (GPT-3: 175B, GPT-4: 더 큼)
📍 GAN(Generative Adversarial Network) — 적대적 생성 신경망
GAN은 두 개의 신경망(생성자 G, 판별자 D)이 서로 경쟁하며 실제 같은 데이터를 생성하는 모델입니다.
• 처음 제안: Ian Goodfellow (2014)
• 대표 적용: 이미지 생성 (얼굴, 예술, 스타일 전환 등)
🔧 작동 원리
- 생성자(Generator): 노이즈를 받아 가짜 데이터를 생성
- 판별자(Discriminator): 진짜인지 가짜인지 구분
- 두 모델이 경쟁하면서 점점 더 정교한 데이터를 생성
🎯 목표: 생성자는 판별자를 속이고, 판별자는 생성자를 간파하려고 함 → 적대적 학습
🌟 특징
• 현실적인 이미지/영상/오디오 생성에 강함
• 고해상도 이미지, Deepfake, 스타일 전환 등에 사용
• 훈련이 어려움 (불안정한 수렴, 모드 붕괴 등 이슈 존재)
📍 VAE
Variational Autoencoder(VAE, 변분 오토인코더)는 단순한 함수 변화 추적보다는 확률 분포를 인코딩하고, 그 분포에서 샘플링해 재구성하는 확률 기반의 생성 모델입니다.
‼️핵심 개념
“잠재 공간(latent space)(ex. 벡터 z)“의 분포를 배우는 인코더
- 일반 오토인코더는
입력 → 벡터 z → 복원을 진행 - VAE는
입력 → 정해진 분포(보통 정규분포)에 대한 매개변수(μ, σ)를 구해 → 이 분포에서 샘플링하여 z를 얻고 → 복원합니다.
즉,단일 지점을 인코딩하는 것이 아니라,
“입력 데이터를 잘 설명하는 분포”를 추정해서 그 분포를 인코딩하는 것입니다.
이 과정이 “변분 추정(Variational Inference)“입니다. 그래서 이름이 Variational Autoencoder입니다.
📍멀티 모달 AI
MMLM(Mulytimodal Large Language Model)
멀티모달 AI는 텍스트, 이미지, 음성, 영상 등 다양한 형태의 데이터를 동시에 이해하고 생성할 수 있는 인공지능 모델입니다.
크게 대표되는 예시로 제가 가장 많이 사용하는 멀티모달 AI로는 Chat GPT4o, Gemini, Claude가 있습니다.
전 이미 인공지능 없이는 살아가기 힘든 몸이 되었습니다...🥲
• “모달(modal)” = 데이터의 형태(양식)(예: 텍스트, 이미지, 소리, 센서 데이터 등)
• “멀티모달” = 다양한 모달리티를 함께 처리🔧 작동 원리 (기본 구조)
멀티모달 모델은 여러 입력 양식을 하나의 공통된 표현(latent space)으로 인코딩하고, 그걸 바탕으로 다양한 출력 양식을 디코딩합니다.
예: 텍스트+이미지를 처리하는 구조
[이미지] → Vision Encoder ─┐
│ → 공동 임베딩 → 디코더 → [텍스트 생성]
[텍스트] → Text Encoder ──┘최신 모델들은 이 과정을 Transformer 기반의 통합 모델로 수행합니다.
특히 LLM 기반으로 멀티모달을 통합하는 게 주류입니다 (예: GPT-4o, Gemini, Claude).
🌟 멀티모달의 특징

[참고 문헌]
