(2020/01/18 작성한 글)
Motivation
Recommender System as Matrix Completion
추천 시스템은 사용자가 좋아할 만한 아이템을 제시해주는 일을 한다. 주로 사용되는 방법은 사용자의 이전 history를 활용하여 아직 평가하지 않은 아이템 중 좋아할 만한 아이템을 제안하는 방법이다.
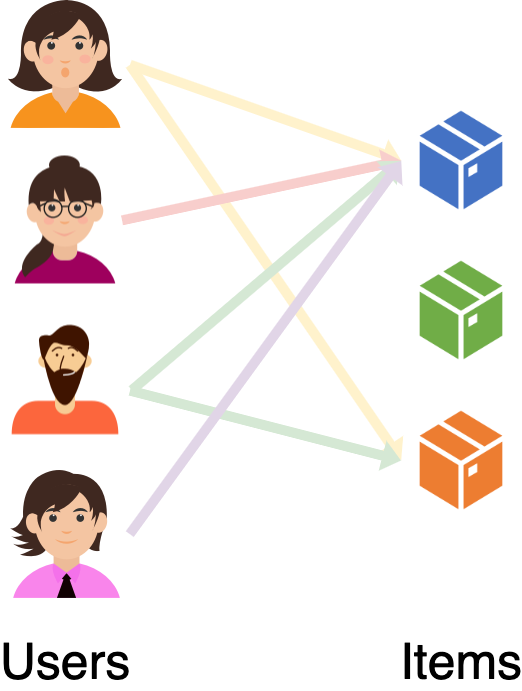
사용자와 아이템의 interaction은 bipartite graph로 표현 할 수 있다.
사용자와 아이템이 Node가 되고 둘 간의 interaction history는 edge가 된다. 그래프의 모든 Edge가 양쪽에 각각 사용자와 아이템을 두기 때문에 Bipartite graph라고 볼 수 있다. 이 관점에서 추천이란 U-I Bipartite Graph에서 두 Node사이의 Edge가 존재하는 지를 맞추는 Link prediction으로 치환된다.
한편, 그래프는 인접 행렬(Adjacency matrix)로 표현할 수 있다. 인접 행렬의 관점에서 추천은 인접 행렬의 값을 채우는 matrix completion 문제가 된다.
Transductive VS. Inductive Learning
기계 학습은 여러 기준에 따라 다양하게 분류될 수 있지만, 학습과 추론에 대한 접근 방식에 따라 Inductive, Transductive로 분류할 수 있다. (deductive는 이 논문의 scope를 벗어나 언급하지 않겠다.) 둘 간의 가장 큰 차이는 test case를 이미 알고 있느냐에 달려있다. Transductive는 특정한 학습 데이터로부터 "특정한(Specific)" test case를 추론한다. 반면 Inductive는 학습 데이터로부터 임의의 함수를 추론하여 "일반적인 (General)" test case를 추론한다.
그렇다면 현재 많이 사용되는 추천 알고리즘들은 Transductive일까 Inductive 일까? 하나의 예로, Matrix Factorization(MF)를 생각해보자. MF는 사용자와 아이템의 embedding을 dot product 등으로 곱하여 rating을 맞추고자 한다. 만약에 학습 단계에서 한번도 보지 못한 사용자가 자신이 좋아하는 아이템들을 보여주고 추천해달라고 한다면 MF는 새로운 사용자에 대한 embedding은 가지고 있지 않기 때문에 답을 해줄 수 없다. Transductive인 것이다. 만약 추천 알고리즘이 Inductive 하다면, 임의의 사용자 (혹은 아이템)에 대해 모두 추론을 해 낼 수 있어야한다.
Inductive Matrix Completion with GNNs
이 논문은 추천을 Matrix Completion의 관점에서 정의하고 최근 많이 각광받는 Graph Neural Networks(GNN)을 이용하여 Inductive 추천 알고리즘을 고안한다. 사용자, 아이템 Embedding처럼 사용자, 아이템 모두를 개별적으로 표현하지 않고 전체 Graph가 아닌 Subgraph의 패턴을 학습하여 학습하지 않은 데이터가 오더라도 평점을 예측해내는 능력을 갖췄다.
Proposed Method
Overview
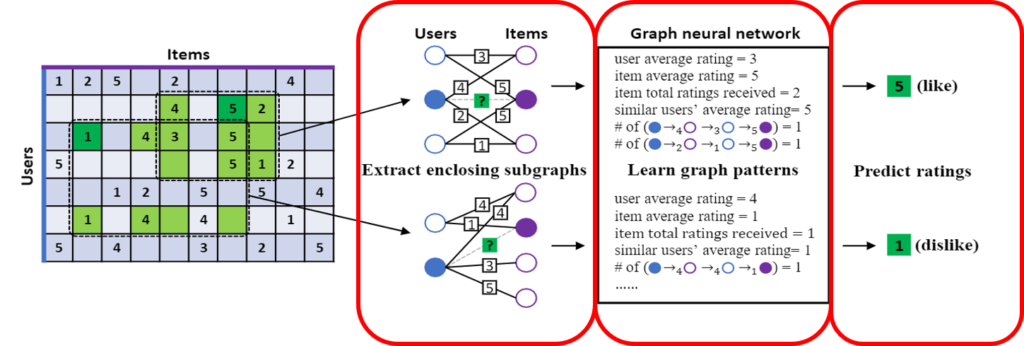
제안 모델의 전체 그림은 위와 같다. 크게 세 부분으로 나눌 수 있다:
1) Subgraph extraction and labeling
2) Subgraph feature extraction
3) Rating prediction
1)에서는 전체 사용자, 아이템 그래프에서 평점을 예측하고자 하는 사용자, 아이템을 중심으로 subgraph를 추출한다. 그 후, Global context를 지우기 위해 Node마다 labeling을 새로하여 Index를 부여한다. 2)에서는 GNN을 이용하여 Subgraph의 패턴을 추출한다. 3)에서는 추출한 패턴으로 평점을 회귀한다.
Enclosing Subgraph Extraction

전체 Bipartite graph에서 특정 사용자, 아이템을 중심으로 이웃으로 확장하며 Subgraph를 만든다. Pseudo-code는 위와 같다. 현재 사용자, 아이템 집합과 연결된 새로운 Node를 집합에 추가해 나간다. 새로운 아이템과 사용자를 집합에 추가하여 Subgraph Node 집합을 확장하고 전체 그래프에서 이 집합에 속하지 않는 Node와 연결된 Edge들을 삭제한다. 마지막으로 평점을 예측하고자 하는 Target 사용자, 아이템 사이의 Edge를 삭제한다.
Node Labeling
모델이 Inductive하려면 Global context를 떨처내야한다. Node가 사용자 Index를 필요로 한다면 Index를 부여받은 적 없는 새로운 사용자는 모델이 소화할 수 없다. 따라서 Subgraph의 패턴만을 읽기 위해 새로운 Label을 달아준다.
- Target User = 0
- Target Item = 1
- Users in hop 1 = 2
- Items in hop 1 = 3
- Users in hop 2 = 4...
이 Node labeling scheme은 1) Target Node와 Context Node를 구분하고, 2) User와 Item Node를 구분하며, 3) 서로 다른 Hop에 추가된 Node를 구분한다. 이 방법을 통해 모델은 오로지 Subgraph만을 고려할 수 있게되며 Inductive learning이 가능하게 된다.
Passing Graph Neural Networks
위에서 만든 Subgraph의 특징을 GNN을 이용하여 추출한다. 각 Node는 부여된 Label의 고유한 embedding을 갖게 된다. 많은 GNN 모델이 있지만 이 논문에서는 Relational-GNN (R-GNN)을 사용한다. R-GNN은 GNN을 Edge(혹은 relation)의 type에 따라 다른 특징을 파악하도록 확장한 모델이다. 평점 예측 문제는 평점이 Relation이 된다. 일반적으로, GNN은 여러 층의 GNN Layer를 통과하는데 모든 layer의 output을 concat하여 Node의 최종 representation으로 정의한다.
Rating Prediction
R-GNN을 통해 파악한 Node의 feature vector중 평점을 예측하고자 하는 사용자와 아이템의 feature vector를 concat하여 subgraph의 최종 표현으로 정의한다. 이를 MLP prediction layer에 통과시켜 평점을 회귀한다.
Model Training
모델 학습은 크게 2가지 Loss로 학습한다. 첫번째로 regression에 많이 쓰이는 Mean Square Error (MSE) Loss이다. 두번째는 Adjacent Rating Regularization (ARR) Loss다. ARR Loss의 아이디어는 각 평점 마다 다른 weight matrix를 사용하는데 가까운 평점의 weight는 적어도 먼 평점의 weight보다 비슷해야 한다는 것이다. 이를 위해 인접한 rating의 weight에 Frobinous norm loss를 취한다.
Experiment
Overall Performance
제안 모델은 표에서 볼 수 있듯 여러 Transductive, inductive 모델들과 대등하거나 더 나은 성능을 보인다. Transductive 모델은 test case를 미리 알고 있기 때문에 general function approximation을 하는 inductive 모델보다 더욱 쉽게 문제를 품에도 불구하고 제안 모델은 Transductive 못지않은 성능을 보인다.
Transfer Learning
Inductive 모델은 Function approximation을 하기 때문에 한번도 보지 못한 사용자 혹은 아이템에도 추론을 할 수 있다. 따라서 한 데이터셋에서 학습한 뒤 다른 데이터셋에서 추론을 할 수 있다. 본 논문에서는 ML-100k에서 학습한 모델을 다른 데이터셋에 추론을 시켜보았다. 그 결과 다른 Inductive보다 좋은 성능을 보였으며 심지어는 특정 데이터셋에서는 일부 transductive 모델들보다 더욱 좋은 성능을 보이기도 한다.
Visualization
마지막으로, 학습한 모델이 어떤 패턴을 읽은 것인지 보기위해 가장 높은/낮은 평점을 매긴 5개의 case의 실제 관계를 시각화하였다. 실제로 높은 평점을 매긴 case는 아이템이 대부분 좋은 평을 받는 경우였고, 반대의 경우 사용자가 거의 모든 아이템에 낮은 평점을 주는 패턴이 두드러졌다. 다소 쉬운 패턴들이지만 subgraph만으로도 평점 예측을 하는데는 충분하다는 것을 보인다.
Conclusion
이 논문은 GNN을 이용하여 inductive한 추천 모델을 제안한다. 성능 비교, Transfer learning 능력, 시각화 등 여러 측면에서 모델의 효과를 잘 보였다고 생각한다. 자연어의 경우 단어는 데이터에 무관하게 같은 단어지만 추천의 사용자 혹은 아이템은 데이터마다 상이하다. 이 점이 추천에서의 inductive learning을 힘들게 하는 부분이라고 생각한다.
이 논문을 확장하여 대량의 추천 데이터로 학습시킨다면 자연어의 BERT와 같은 Pretrain-RecSys가 가능하지 않을까? 이 전에 제안된 논문들도 있지만, 이 논문의 직관적이고 어렵지 않은 아이디어는 개인적으로 인상깊었고 코드와 함께 더 생각해 볼만 하다고 느낀다.
