(2020/10/24 작성)
들어가며...
추천 모델에는 여러 종류가 있겠으나, 최근은 깊은 (또는 복잡한) 구조와 Gradient Descent로 무장한 딥러닝 추천 모델 (Neural Recommender)이 연구에서 인기를 끌고 있다. 하지만 이와 더불어 신경망 (Neural)이 비신경망 (Non-neural)에 비해 더 우위를 보일 것으로 기대하지만, 이런 직관에 반대되는 연구결과[8]도 많이 나오고 있다.
개인적으로 생각하기에, 이러한 현상에 많은 원인 중 하나는 SOTA (State-Of-The-Art) chasing 연구에 있다고 본다. "ML-20M에서 State-of-the-art에 비해 NDCG@10기준 5%의 성능 향상을 가져왔다." 와 같은 문장은 빈번하게 보이지만 "우리 모델은 Sparse한 데이터에 특히 잘되며, ItemKNN과 비교해 unpopular한 사용자, popular item 등에 강점을 보인다. 또한, 초반에는 popular한 사용자가, 후반에는 unpopular한 사용자가 학습된다." 와 같 은 모델에 대한 심층적인 이해는 덜 빈번하다.
이러한 동기와 개인적인 호기심으로 질문 하나를 던져보았다. "Neural 추천 모델이 학습 epoch에 따라 target item을 top-k에 올려놓는 것이 어떻게 변화할까? 이걸 시각적으로 보면 어떨까?"
관찰 방법
사실, 제목과 서두에 비해 내용은 큰 것이 없다. 해보고자 하는 내용은 아래와 같다.
추천 모델의 Long-tail 특성에 따라 사용자 인기도 기준 상위 20%를 Popular 사용자, 나머지를 Unpopular한 사용자로 정의한다. 시각화에는 Top-popular 30명, Bottom-popular 30명을 뽑는다. X축을 Top-k, Y축을 사용자 ID, 값은 Target item을 맞추었는지 여부로 하여 Grid를 그린다. Epoch에 따라 Grid가 변화하는 과정을 Animation으로 만든다.
설명은 다소 복잡하지만 그림으로 보면 이해가 어렵지 않다고 본다. 대상 모델은 간단한 Non-neural 계열: PureSVD[1], EASE[2], Neural 계열 DAE[3], MultVAE[4], 데이터셋은 많이 사용되는 MovieLens-1M (ML-1M)로 실험하였다. Top-k는 최대 100까지 확인하였다. Hyperparamter 튜닝은 특별히 하지 않았다.
관찰 결과
실험 결과를 그린 플롯들은 아래와 같다. 왼쪽과 가운데는 Epoch에 따른 Loss와 NDCG@100 수치이다. 가운데 그림의 파란선은 전체 정확도, 주황선은 Popular사용자 정확도, 초록선은 Unpopular 사용자 정확도이다. 오른쪽은 Epoch에 따라 Popular 사용자 (0~29)와 Unpopular 사용자 (30~59)의 Top-100추천 중 정답 (노란색)의 위치 변화를 시각화한 그림이다. 노란색이 정답 아이템의 위치를 가리킨다.
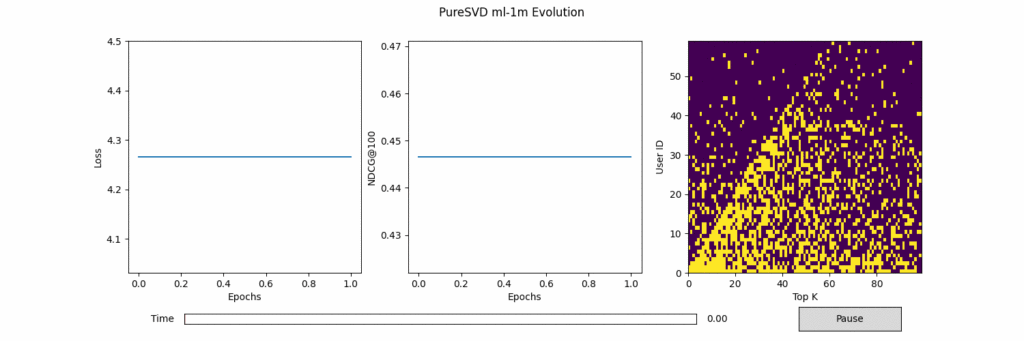
그림 1. ML-1M에서 PureSVD 결과
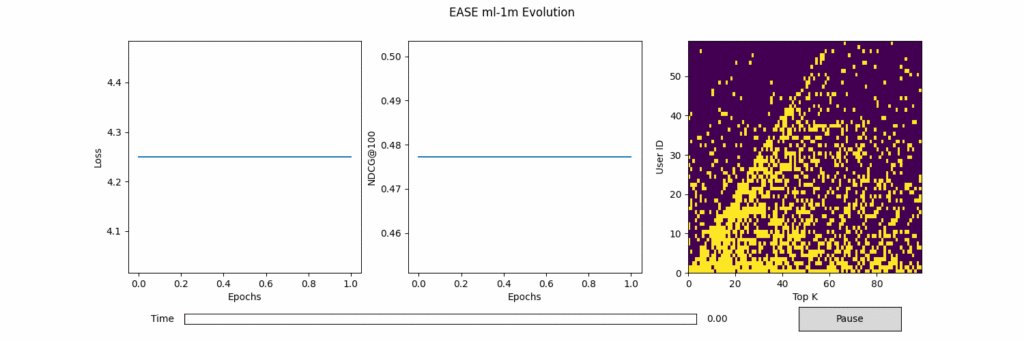
그림 2. ML-1M에서 EASE 결과
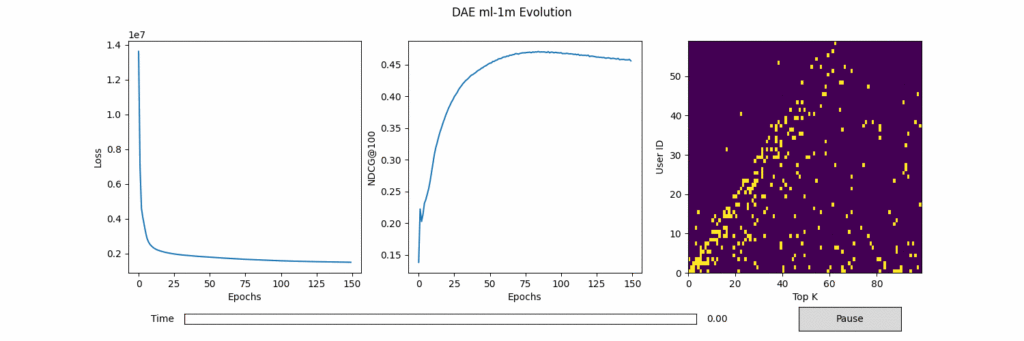
그림 3. ML-1M에서 DAE 결과

그림 4. ML-1M에서 MultVAE 결과
위 결과로부터 얻은 점은 다음과 같다.
1. (당연하게도) 모든 모델이 평점이 많은 Popular한 사용자의 정확도가 Unpopular한 정확도보다 훨씬 높다.
머신러닝은 데이터로 부터 학습하기 때문에, 평점이 많은 사용자 위주로 학습이 이루어질 수 밖에 없고, 이 사용자에 높은 추천 정확도를 보이는 것은 당연한 결과이다. 다만, DAE, MultVAE가 비선형 모델인 PureSVD, EASE보다 약간 높은 Unpopular 정확도를 보인다.
2. Unpopular한 사용자의 정답을 최상위 N까지 올려놓는 것은 아주 어렵다.
이것 또한 당연한 말이다. 가장 Unpopular한 사용자의 정답을 모든 모델이 아예 못맞추지는 않는다. 100위 안에는 들어있다. 하지만, 일반적으로 우리는 100번째까지 추천을 기다리지 않는다. Top-20을 기준으로 보면 왠만한 모델들은 하나도 적절한 추천을 하지 못한다. Neural과 Non-neural을 비교하자면 Neural이 Non-neural보다는 최상위에 올려놓는 비율이 높다. 학습이 진행됨에 따라 Target item들이 앞쪽 N으로 올라오는 모습이 관찰되나 Top-40~60사이에 머무는 데 그치는 경우가 많다.
3. Neural 모델은 Personalization-Generalization Trade-off가 있다.
가장 좋은 추천은 개개인 모두에게 personalized된 모델로 추천을 하는 것이라고 볼 수 있다. 하지만, 모든 사용자를 모두 고려하여 학습해나가기에 Personalization과 Generalization 사이의 균형이 중요하다. DAE와 MultVAE모두 학습 초기, 심지어는 10 epoch전에 popular사용자의 정확도가 0.7 이상으로 아주 높고 epoch이 지남에따라 크게 증가하지 못하고 감소한다. 반면 Unpopular한 사용자의 정확도는 그 와중에도 상승하는 것을 보인다. 이는 상대적으로 쉬운 popular한 사용자 위주로 fitting된 모델이 generalization을 하면서 popular사용자의 Personalization에 희생을 감수한다는 것을 의미한다.
마무리하며
최근 논문 작업을 마무리하고 쉬던 중 갑자기 생각이 나서 간단히 실험해보았다. 추천 시스템은 참 어렵다. 사용자에 적합한 추천을 하는 것도, 적합한 추천을 모두에게 잘 하는 것도 어렵다. 특히나 별다른 정보가 주어지지 않은 사용자에게 추천하는 것은 노력대비 return이 좋지 않다. 그럼에도 더 잘하기 위해 끊임없이 방법을 연구하는게 연구자인가...
최근, 사람들의 관심사 또한 단순 Accuracy 개선에서 더욱 나은 평가 방법[5], 실제 추천 환경과 연구 환경의 격차[7]를 줄이기위한 방법, Personalization-Generalization 사이의 균형[6] 등 다음 단계로 가고있다는 느낌을 받는다. 개인적으로도 5%의 NDCG 상승이 과연 얼마나 도움이 되는 일인가에 대해 일종의 회의를 느끼고 있는 와중에 반가운 흐름이라 결론은... 더욱 열심히 하자...
Reference
- Cremonesi et al., Performance of Recommender Algorithms on Top-N Recommendation Tasks. RecSys 2010.
- Steck, Embarrassingly Shallow Autoencoders for Sparse Data. WWW 2019.
- Wu et al., Collaborative denoising auto-encoders for top-n recommender systems. WSDM 2016.
- Liang et al., Variational Autoencoders for Collaborative Filtering. WWW 2018.
- Yang et al., Unbiased Offline Recommender Evaluation for Missing-Not-At-Random Implicit Feedback, RecSys 2018.
- Chen et al., Trading Personalization for Accuracy: Data Debugging in Collaborative Filtering, NeurIPS 2020.
- Beel et al., A Comparative Analysis of Offline and Online Evaluations and Discussion of Research Paper Recommender System Evaluation, RecSys 2013.
- Davrema et al., Are we really making much progress? A worrying analysis of recent neural recommendation approaches. RecSys 2019.
