[SIGIR 2020] AR-CF: Augmenting Virtual Users and Items in Collaborative Filtering for Addressing Cold-Start Problems
paper-review
(2020/09/04 작성)
- AR-CF: Augmenting Virtual Users and Items in Collaborative Filtering for Addressing Cold-Start Problems
- Dong-Kyu Chae, Jihoo Kim, Duen Horng Chau, Sang-Wook Kim
- Georgia Institute of Technology, Hanyang University
- Paper
Motivation
추천 시스템의 데이터는 몇 가지 주요 특징을 갖고 있습니다. 첫째로, 모든 사용자가 모든 아이템을 보고 평가할 수 없기 때문에 데이터가 아주 Sparse 합니다. 둘째로, 소수의 아이템과 아이템이 다수의 평점을 점유합니다. 사용자별로 평가하는 아이템의 수가 천차만별이며, 어벤져스와 같은 블록버스터 영화는 유명하지 않은 영화에 비해 압도적으로 많은 평가 수를 갖게 됩니다.
이로 인해 추천 시스템은 추천에 여러 어려움을 겪게 되는 데, 큰 문제 중 하나는 Cold-start 문제입니다. 이는 평가 수가 적은 사용자 혹은 아이템에 대한 추천 정확도가 크게 떨어지는 문제를 말하는데, 그 원인은 적은 평점으로 인한 Collaborative Signal의 부족이 있습니다.
이를 해결하기 위해, 여러 방법이 제시되었는데 나이, 국적 혹은 장르와 같은 사용자, 아이템의 Additional Information을 활용하거나, Crowdsourcing을 이용해 비슷한 사용자/아이템을 찾습니다. 하지만 이는 그러한 정보와 가용 자원이 있어야만 가능합니다.
이 논문은 추가적인 정보가 없는 pure-CF (Collaborative Filtering)상황을 가정하고 Conditional GAN (CGAN)을 활용하여 정보가 부족한 사용자, 아이템에 도움이 되는 새로운 사용자와 아이템을 만들어 직접적으로 문제를 해결하고자 합니다.
Proposed Method: AR-CF
제안 방법은 1) AR-Step과 2) CF-Step의 두 단계로 나누어집니다. AR-Step은 CGAN을 활용하여 가상의 사용자, 아이템을 생성하는 단계이며 CF-Step은 생성된 사용자와 아이템으로 추천을 향상하는 단계입니다.
AR-Step
AR-Step은 1) CGAN 학습, 2) CGAN을 통한 데이터 생성으로 나누어집니다.
이 글에서는 User-side를 설명하며 Item은 같은 방법으로 적용 가능합니다.
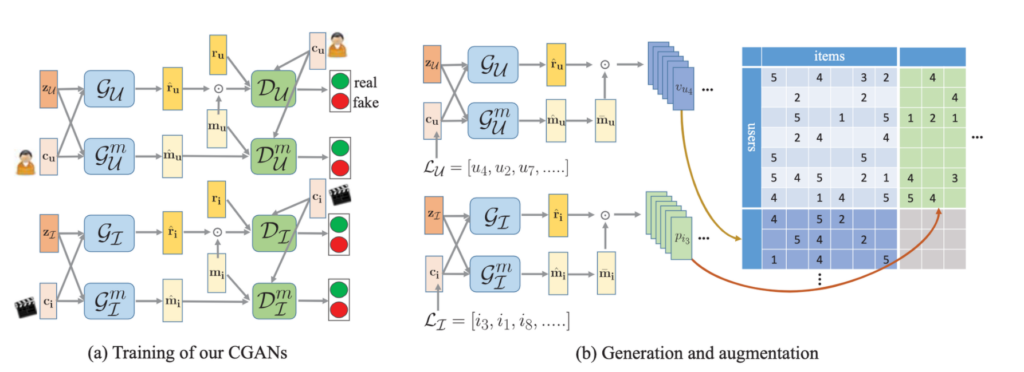
CGAN 학습
GAN은 간단히 말해 Generator와 Discriminator의 mini-max 게임을 통해 Generator가 실제 데이터와 비슷한 가상의 데이터를 생성하고 Discriminator는 진짜와 가짜를 구분합니다. Discriminator가 구분을 하지 못하게 되면 학습이 종료되고 Generator는 그럴듯한 데이터를 생성할 수 있게 됩니다. 이 논문에서는 특정 사용자 (e.g. cold-start)를 고려한 Neighbor를 생성하기 위해 조건을 고려한 생성이 가능한 CGAN을 사용합니다.
논문에서는 2개의 CGAN을 학습합니다. 하나(G_U, D_U)는 Condition인 사용자의 선호도와 유사한 가상의 사용자를 생성합니다. 임의의 CF모델인 G_U는 생성한 user의 rating vector가 실제 rating vector를 모방하도록 학습하며 D_U는 실제 user (1)와 가상의 user (0)를 구분하도록 학습합니다.
다른 하나(G_U^m, D_U^m)는 사용자의 Sparsity 패턴 (missingness), 즉 어떤 아이템을 평가했을 지를 생성합니다. 이 때는, rating이 아닌 사용자가 아이템을 평가했는지 여부를 생성하고, 구분하도록 학습하며 방법은 앞과 같습니다.
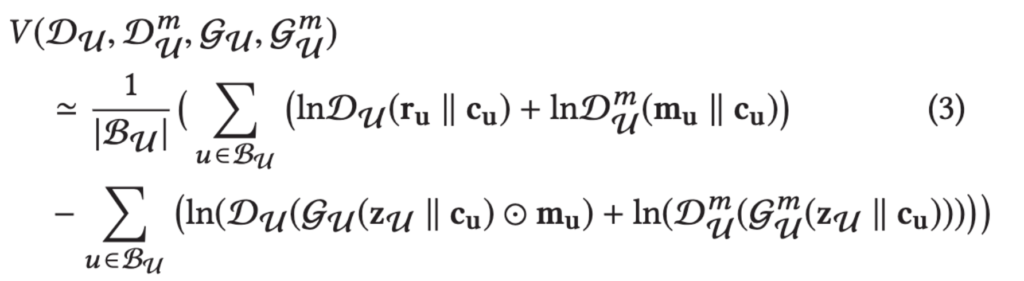
데이터 생성, 증강
CGAN 학습이 끝난 후, Generator를 통해 가상의 사용자와 아이템을 각각 \delta_u, \delta_i개 (혹은 비율) 생성합니다. (hyperparameter). 생성은 random noise에 실제 사용자의 condition vector를 Generator에 넣어주어 '실제 사용자와 유사한 임의의 사용자 (u')'를 생성합니다.

어떤 사용자를 condition으로 줄 것인가는 cold-start 문제 해결을 위해 "1 / popularity"의 확률로 sampling을 합니다. 즉, rating이 많은 사용자, 아이템보다 적은 (cold-start) 사용자가 더 높은 확률로 sampling 되도록 합니다. 또한, floating number인 \hat{m}_u를 binarize mask로 만들 때, 얼만큼을 1로 할 것인지를 k (hyperparameter)로 정하며 실험에선 사용자, 아이템당 평균 평점 수로 정했습니다.
CF-Step
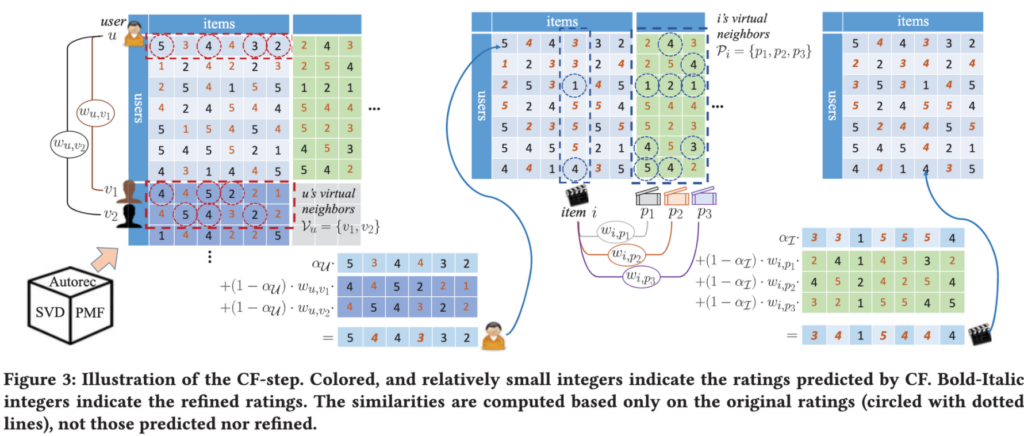
CF-Step은 생성된 사용자, 아이템으로부터 실제 사용자-아이템 평점을 향상시키는 단계입니다. 기본적인 아이디어는 Memory-based Method (e.g. KNN)과 같이 유사도가 높은 가상의 사용자의 평점을 weighted sum하는 방식입니다.
먼저 임의의 모델로 증강된 Rating matrix를 학습합니다. 논문에서는 AutoRec, SVD를 사용하였습니다. 그 후 matrix의 빈 곳의 값을 예측합니다. 위 그림에서 주황색으로 쓰여진 값이 예측값입니다.
다음으로 가상의 사용자의 정보를 활용합니다. 각 사용자별로 가상의 사용자와의 유사도를 계산하여 가중치w_uv를 구합니다. 가중치를 활용하여 자신의 예측과 가상의 사용자의 예측을 weighted sum하여 최종 예측값을 구합니다. 이 때, 실제 사용자와 가상의 사용자의 예측이 최종 예측에 반영되는 비율을 a_U로 조정하며 이는 hyper-parameter 입니다. 유사도로는 Pearson correlation coefficient를 사용하였습니다.
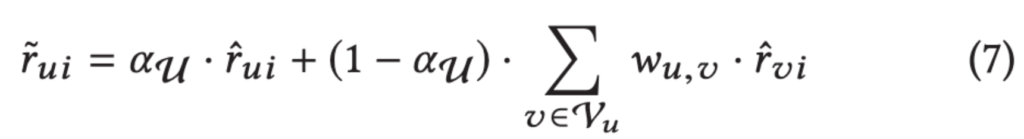
마지막으로, 가상의 아이템 정보를 위와 같은 방법으로 활용합니다. 각 아이템과 가상의 아이템 사이의 유사도를 구한 뒤 weighted sum 하여 최종 예측을 구합니다.
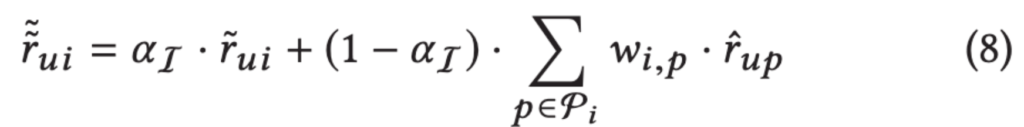
Experiment
실험은 총 4개의 데이터셋 (ML-100k, 1M, CiaoDVD, Watcha)으로 진행되었습니다. (대부분 다소 작은 데이터를 사용한 점은 다소 아쉬운 점이네요.) 주된 Research Question은 2가지로 볼 수 있습니다: 1) AR-CF가 Cold-start 문제를 해결하는가? 2) State-of-the-Art 모델보다 우수한 성능을 보이는가?
Cold-start를 해결하는 AR-CF
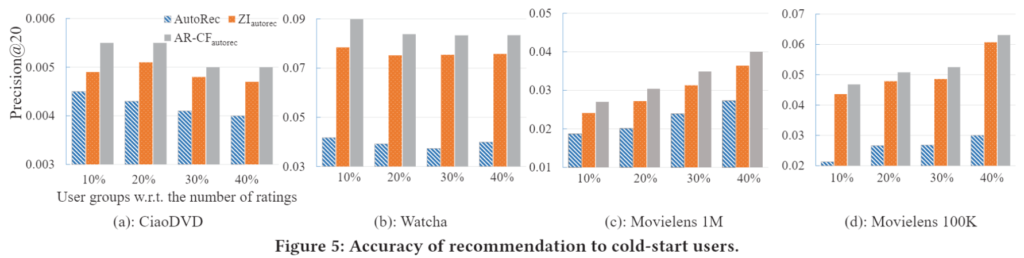
위 그래프는 사용자 그룹에 따른 AutoRec(Base), ZI(Imputatoin), AR-CF(Proposed)의 성능입니다. 모든 그룹에서 ZI가 AutoRec보다는 성능 향상을 가져오지만 제안 모델이 그보다 더 성능 향상을 가져오는 것을 볼 수 있습니다. 글에는 생략했지만 Item에서도 그룹별 성능 향상을 볼 수 있었으며, 덜 유명한 아이템을 추천 모델이 더 추천 하는 것을 확인할 수 있습니다.
SOTA 모델과의 비교
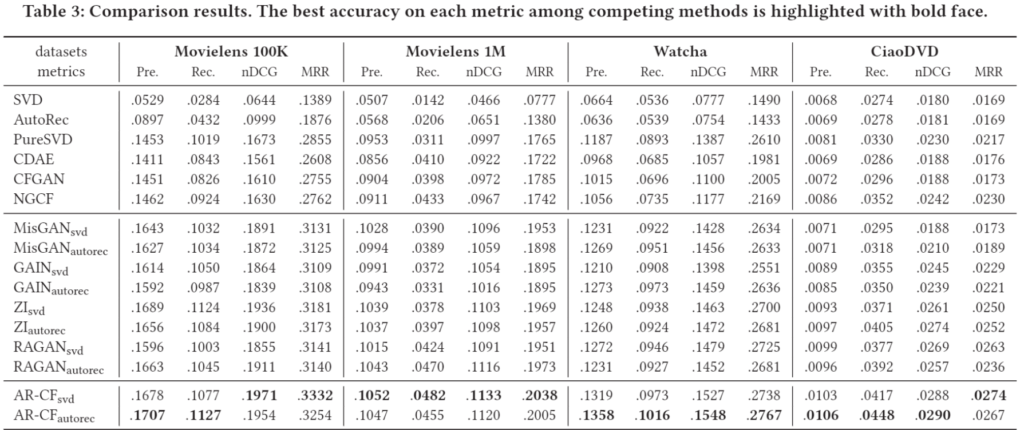
제안모델이 비교 모델들에 비해 큰 성능 향상을 보이는 것을 확인할 수 있습니다. Imputation, Augmentation 추천 논문을 처음 봐서 그런지 다소 단순한 SVD, AutoRec에 Augmentation을 했더니 NGCF등의 더욱 복잡한 모델의 성능을 크게 상회하는 것이 놀랍네요.
이 논문과는 벗어난 얘기지만, CDAE의 경우 모든 데이터셋에서 PureSVD보다 떨어지는 성능을 보이는데, 개인적으로도 CDAE가 더욱 단순한, 때로는 사용자 표현을 제외한 DAE 보다 성능이 떨어지거나 학습이 불안정한 모습을 보이는 것을 경험해서 이 부분은 여전히 왜 그런지 의문입니다.
Conclusion
이 논문은 추천 시스템의 오래된, 그리고 중요한 문제인 Cold-start 문제를 CGAN을 이용한 가상의 사용자, 아이템 생성을 통해 해결한다. 부족한 데이터를 적절히 늘린다면 성능 향상이 올 것이라는 기대는 어찌보면 당연한데, 그 어떻게, 적절히가 정말 어려운 법이다. CGAN에게 그 일을 맡긴 부분이 인상적이었습니다.
궁금한 점이 있다면 훨씬 큰 데이터 (e.g. ML-20M, Netflix)에도 AR, CF-Step으로 이어지는 과정을 다 감당할 수 있을 것인지, Cold-start를 추가했을 때 Warm-start 사용자의 정확도는 얼마나 변하는 지가 궁금합니다. 또한, 구현을 하면 할 수 있을 것 같지만 공개된 코드가 있다면 더 좋을 것 같습니다.
