Introduction
Specialization Introduction
- What a team! ㅋㅋ
Course Introduction
- incremental learning증분학습
Meet your instructors!
Your Specialization Roadmap
- course 1
- multi-arm bandit problems
- Markov decision processes
- course 2
- Monte Carlo methods
- temporal difference learning
- Q learning
- course 3
- feature construction, neural network learning, policy gradient methods, and other particularities of the function approximation setting
- final course
- Capstone project
The K-Armed Bandit Problem
- 산적문제
Sequential Decision Making with Evaluative Feedback
-
The value is the expected reward
-
Goal : Maximize the expected reward
Estimating Action Values
Learning Action Values


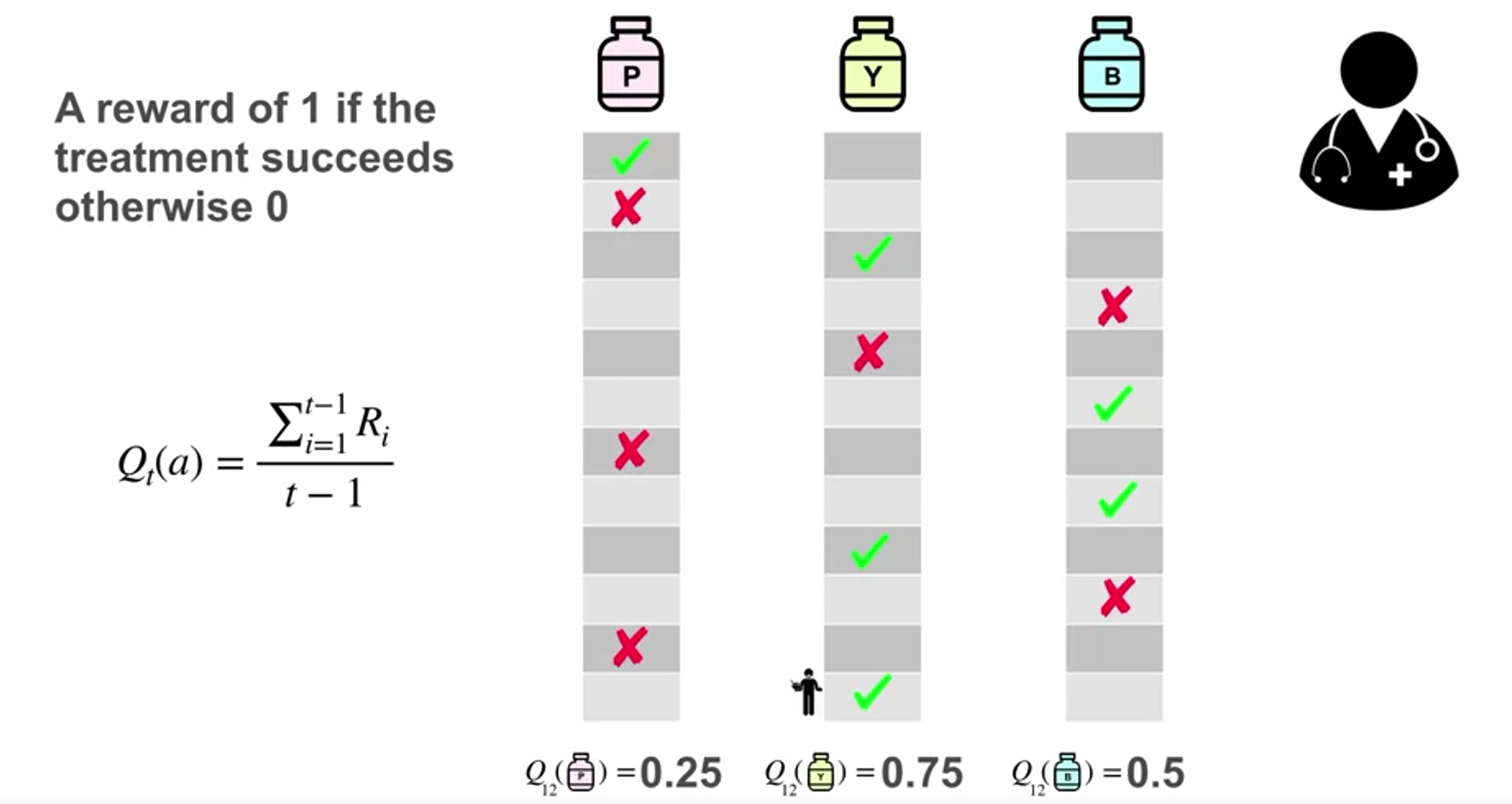


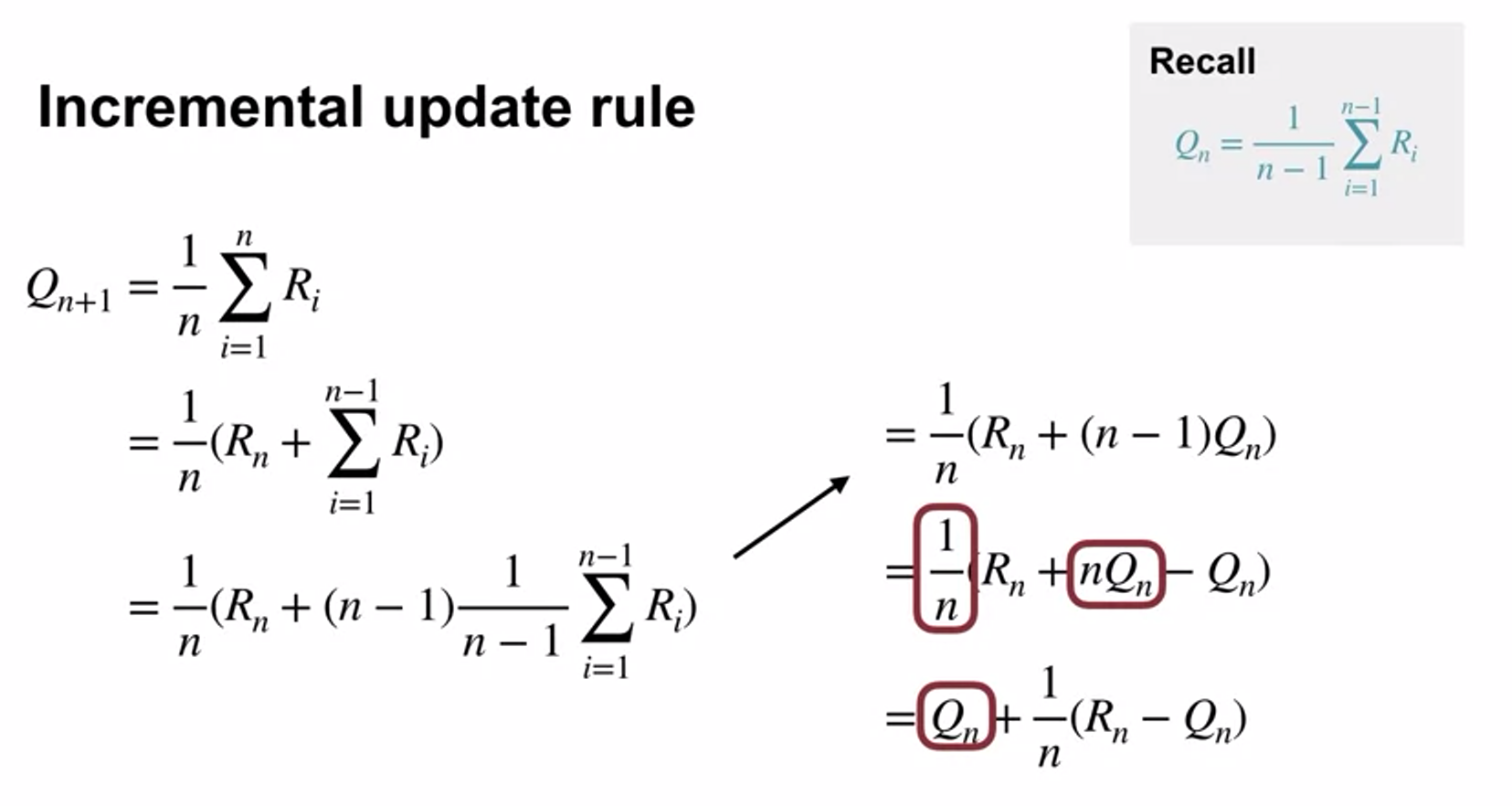
Estimating Action Values Incrementally

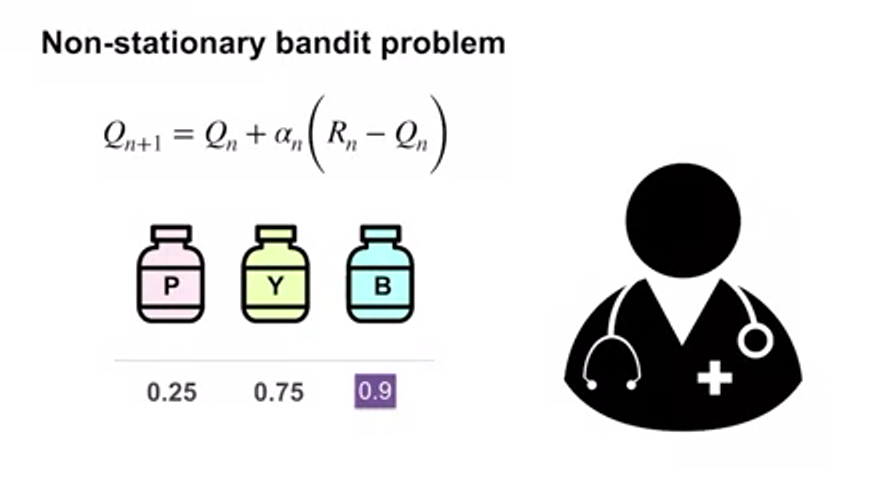
- 이 non-stationary bandit problem은 시간에 따라 reward distribution이 달라진다
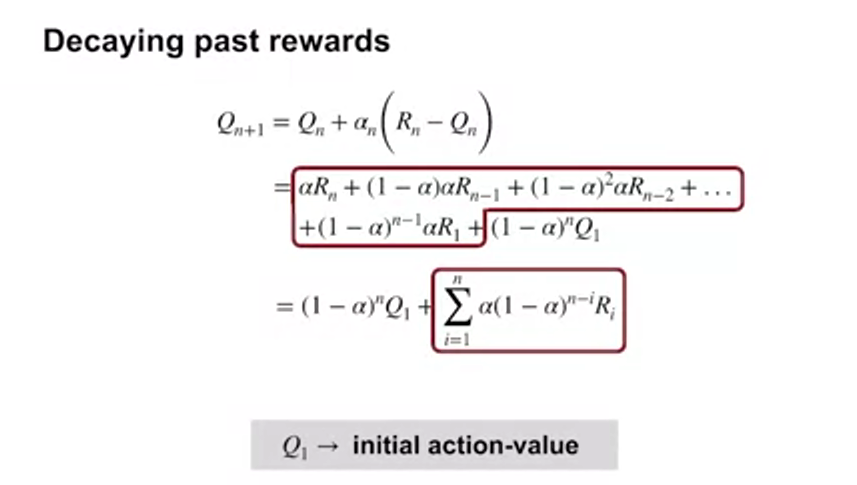
- 뒤로 갈수록 최근의 보상이 가장 큰 영향력

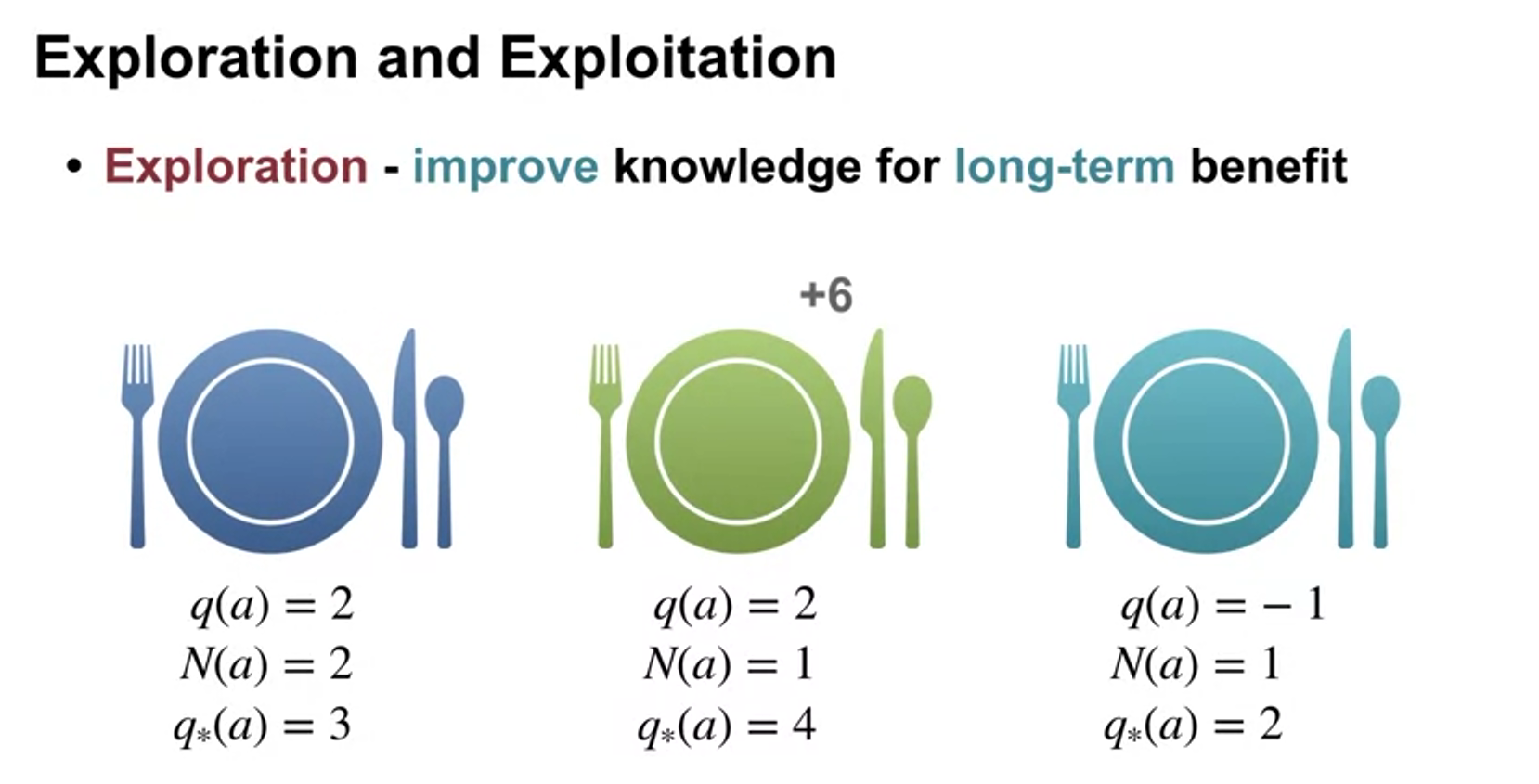
Exploration vs Exploitation Tradeoff
What is the trade-off?


- choose randomly
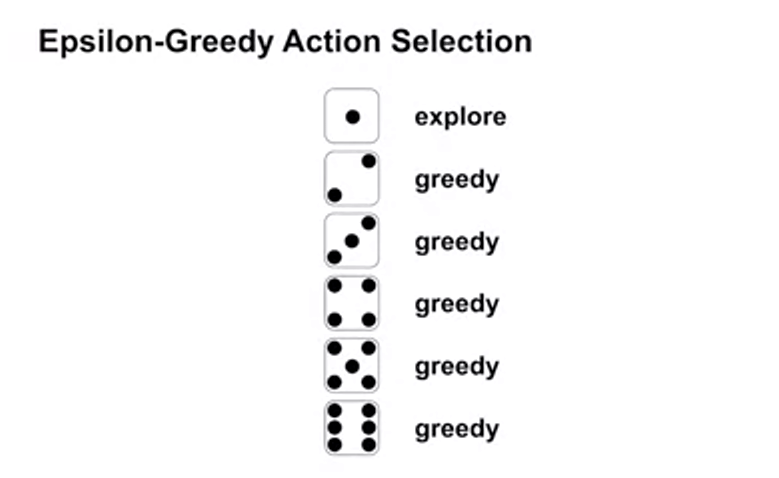
- Epsilon-Greedy
- many noises, hard to conclude
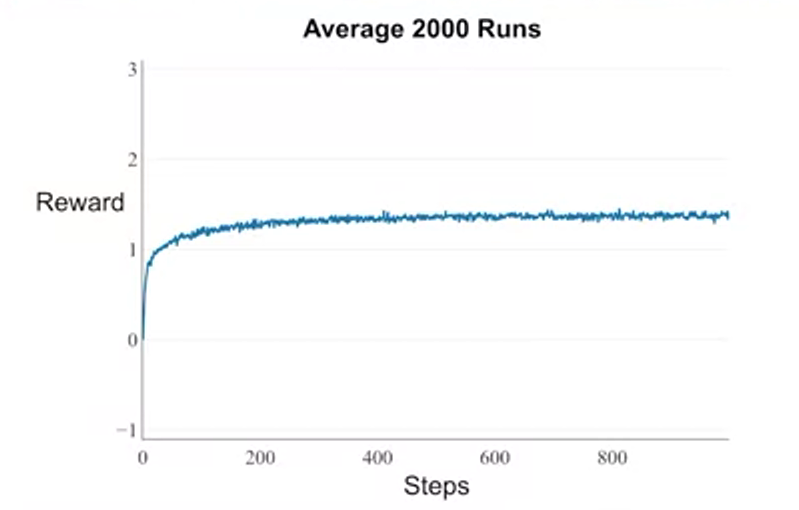
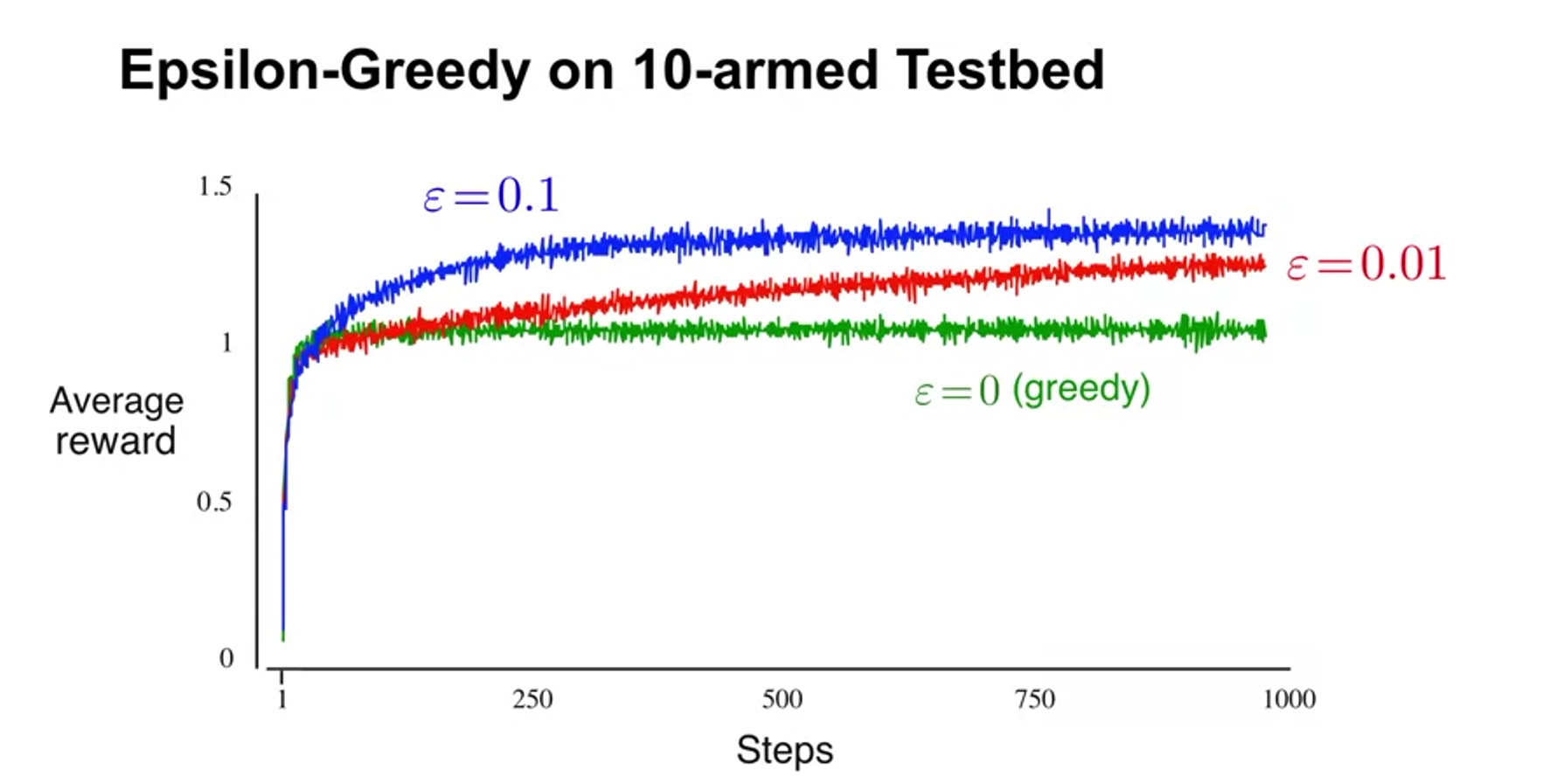
-
epsilon = 0 -> only greedy
-
epsilon-greedy for balancing exploration and exploitation
Optimistic Initial Values
- how optimism affect action-selection

- optimistic initial value encourages exploration ealry in learning
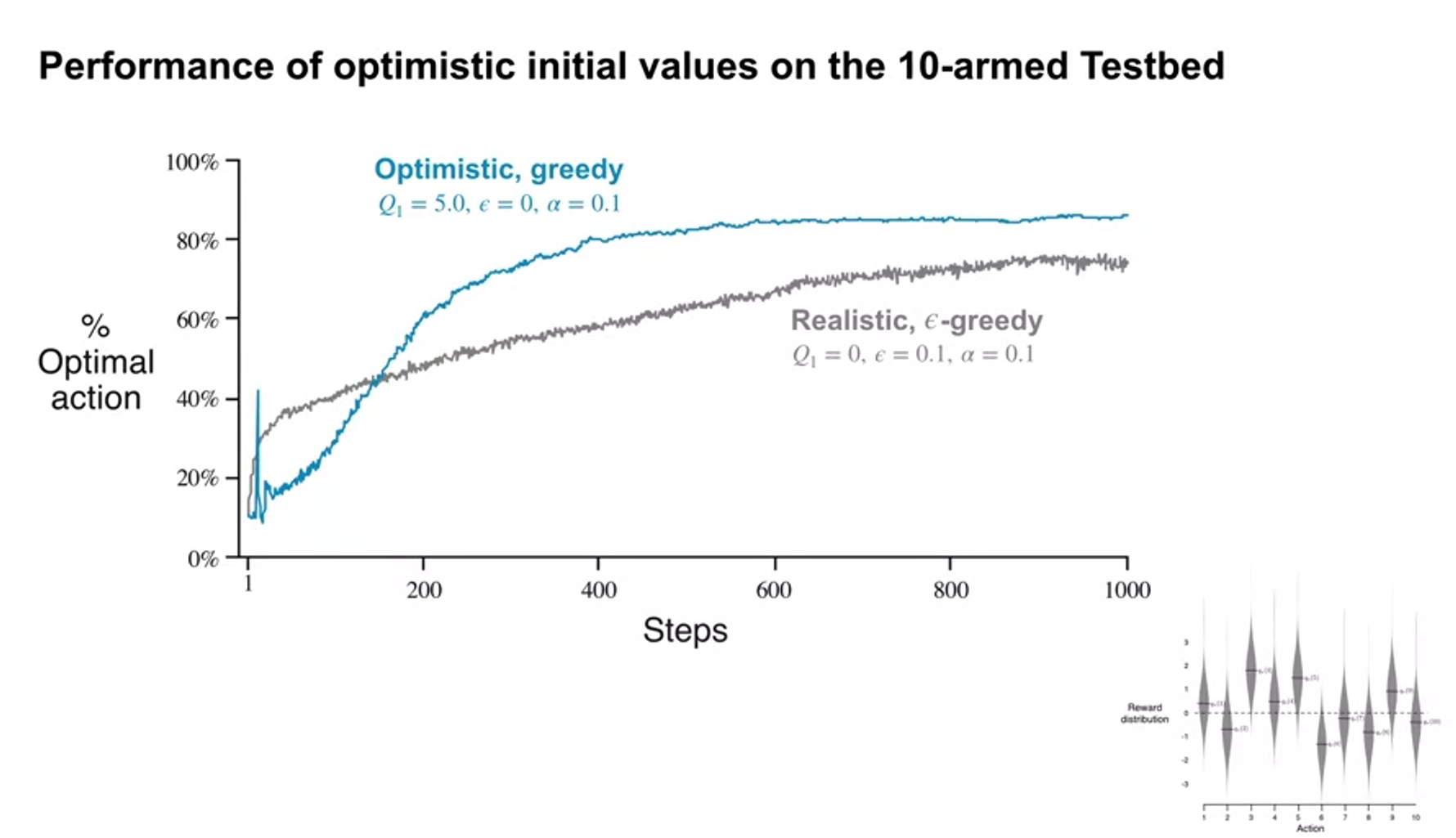

Upper-Confidence Bound (UCB) Action Selection
-
upper-confidence bound action selection
-
how ucb drive to exploration

- epsilon-greedy에서는 확률로 uniformly selected
- value estimates에 uncertainty 개념을 도입하면 more intelligent way select
- region in between lower-bound and upper-bound is confidence interval
- represents uncertainty
- if region is small we are very confident
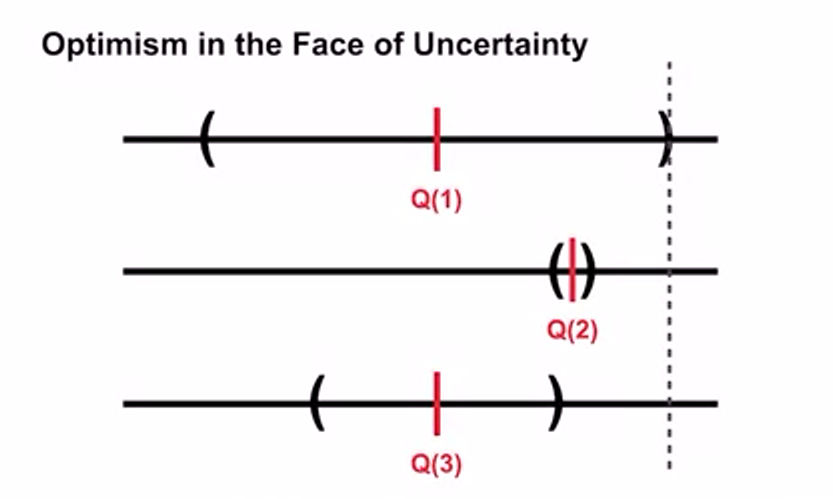
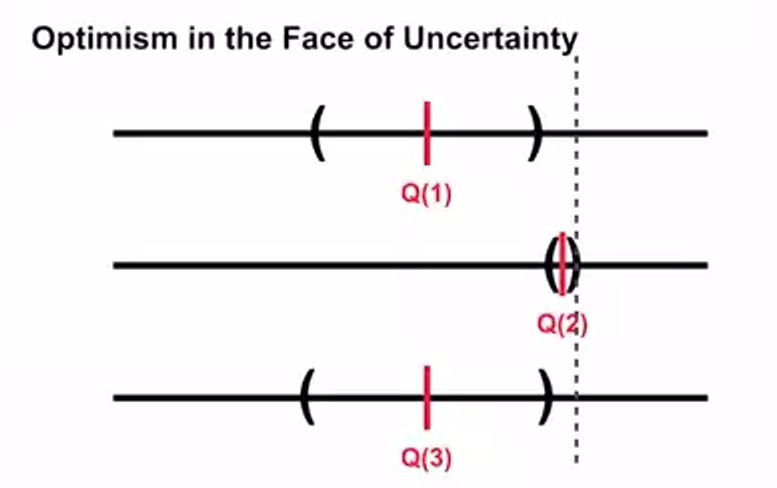
- Q(2) interval is smallest but highest upper-confidence bound
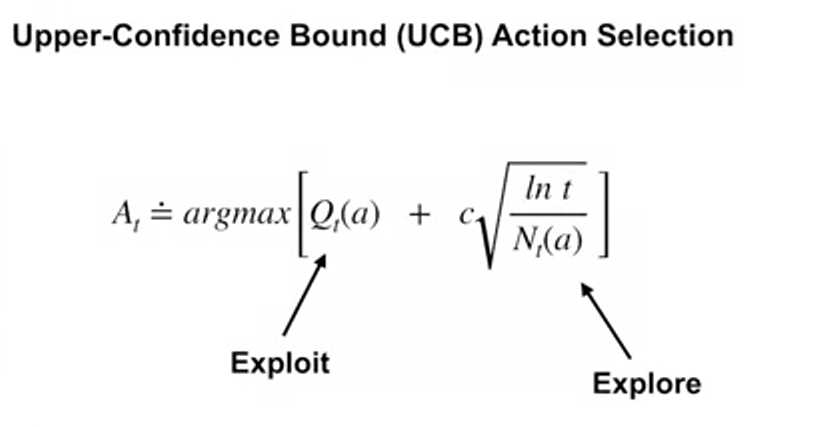
- C parameter : user specified parameter controls amount of exploration
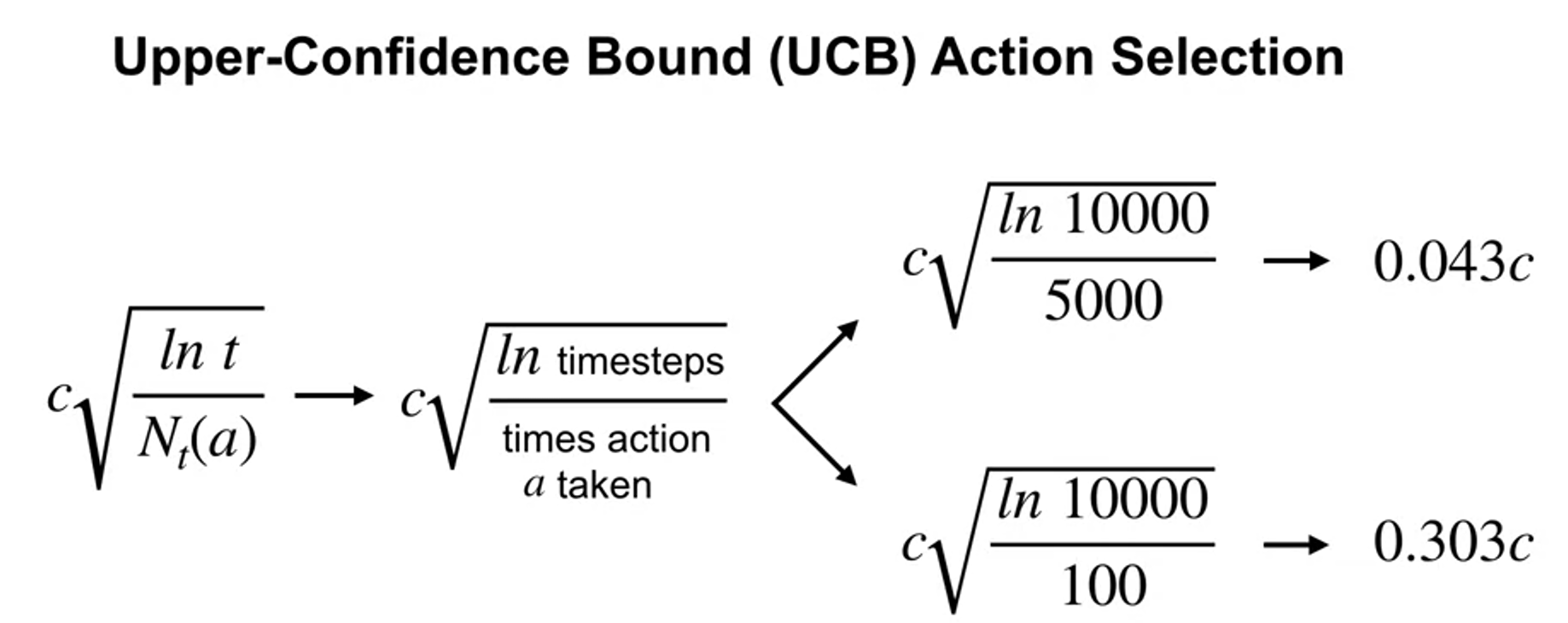
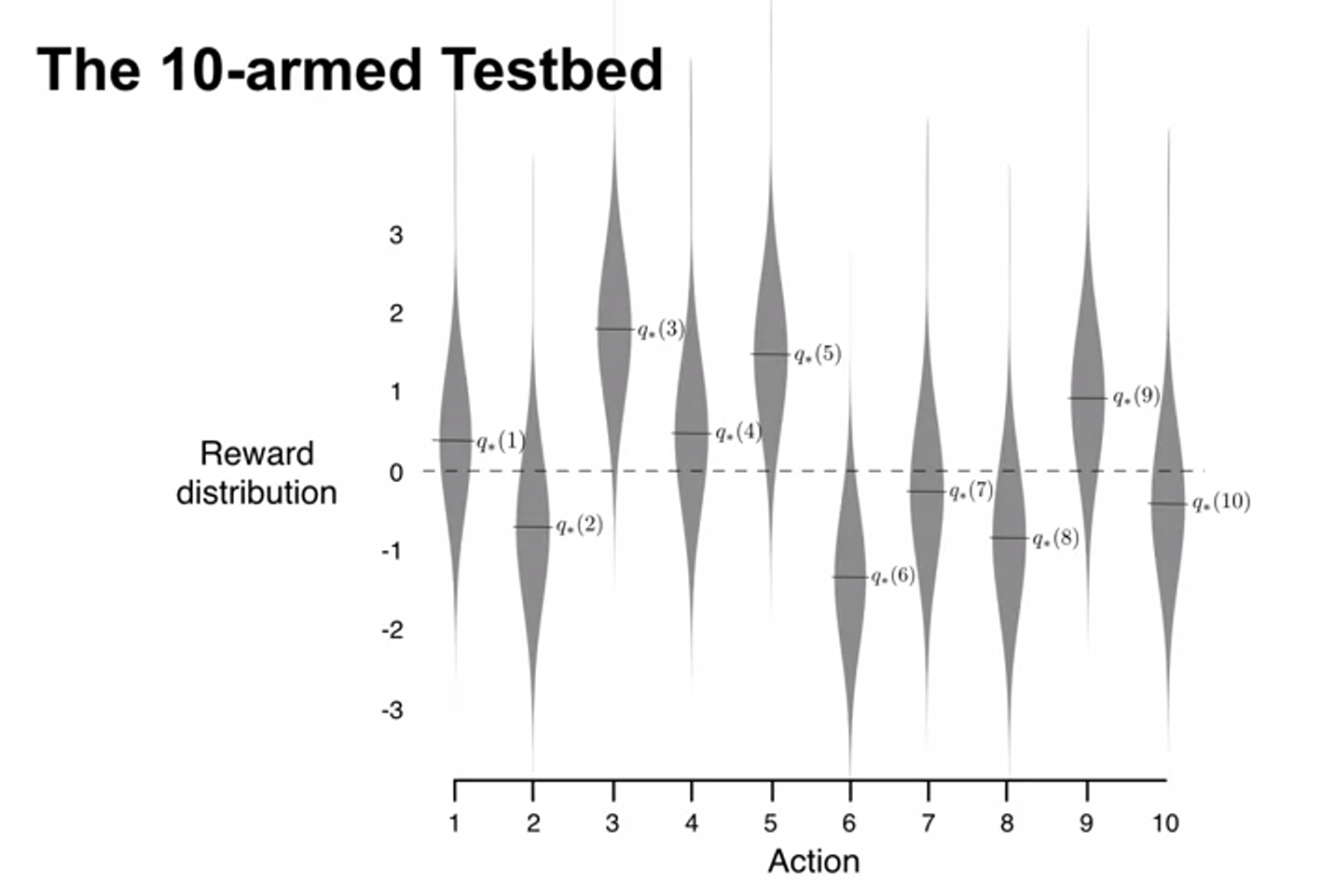
-
normarly distributed with the mean zero and standard deviation one.
-
rewards are sampled from univariance normal with mean
-
, compare UCB and epsilon-greedy
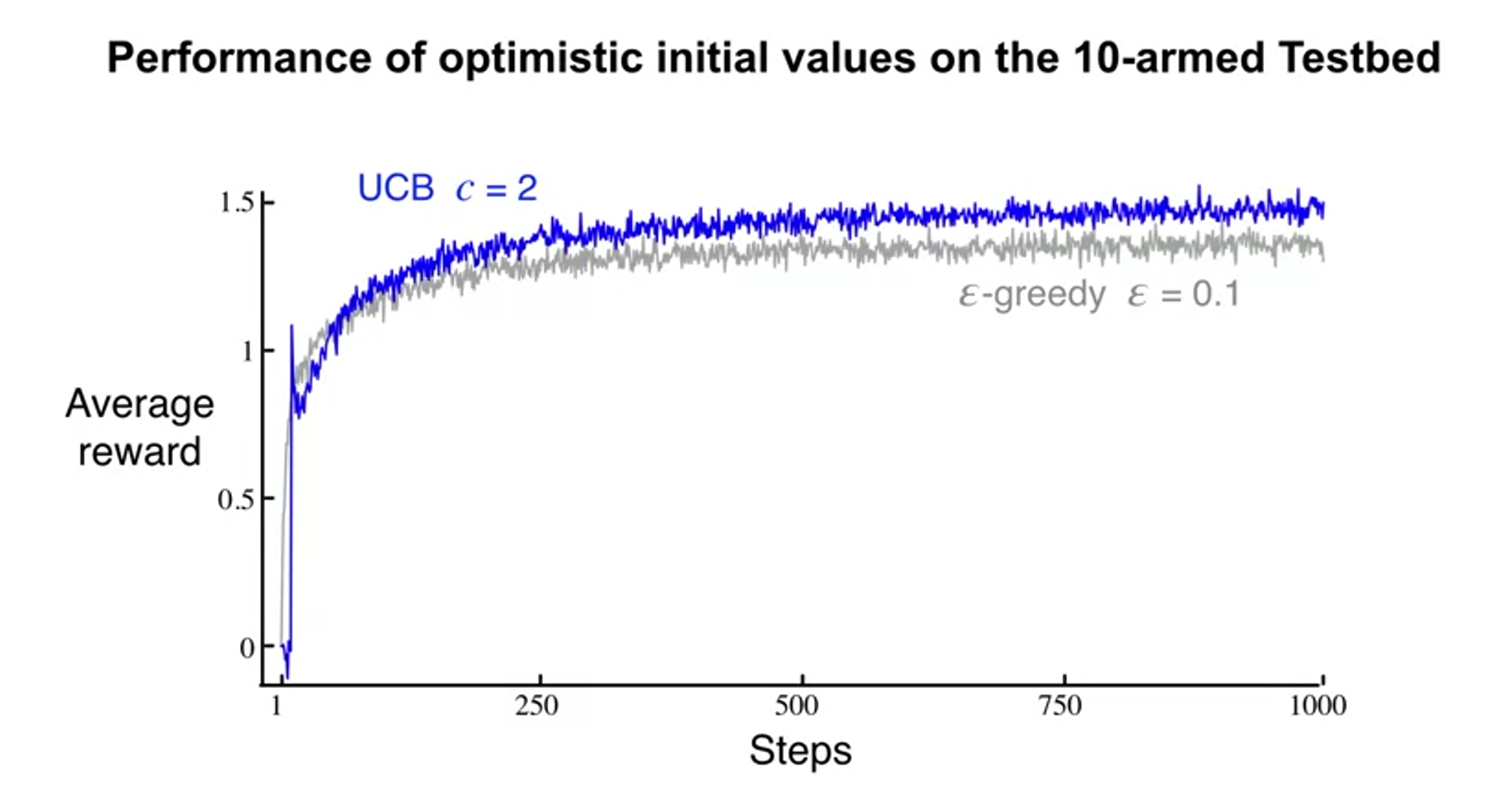
Jonathan Langford: Contextual Bandits for Real World Reinforcement Learning
- RW typically environment controls you.

