Reinforcement Learning
1.Deep RL Course
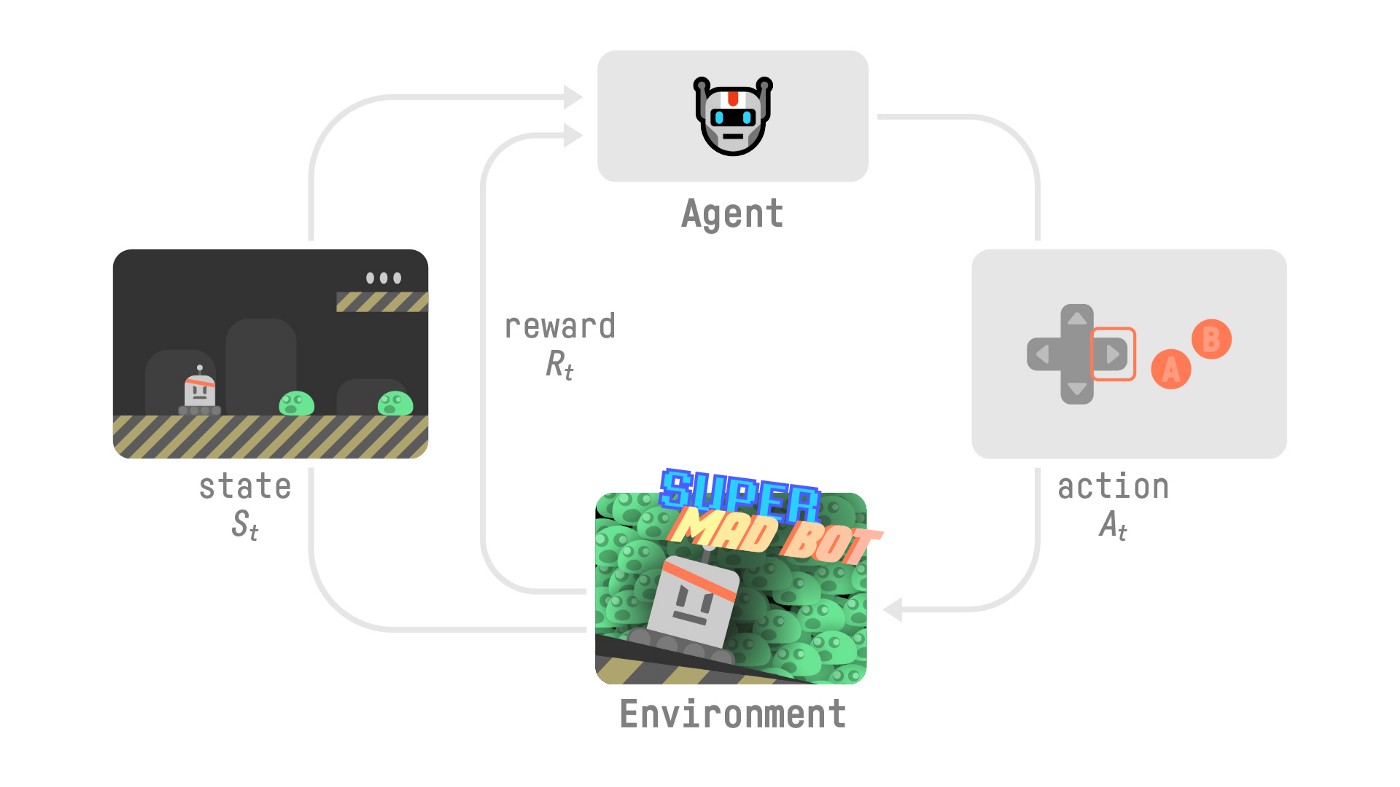
The RL Processsqeuence of state, action, reward, next state.Reward hypothesis : maximization of the expected cumulative reward.Markov PropertyRL proce
2. Fundamentals of Reinforcement Learning - Week 1

What a team! ㅋㅋincremental learning증분학습course 1multi-arm bandit problemsMarkov decision processescourse 2Monte Carlo methodstemporal difference learni
3.Fundamentals of Reinforcement Learning - Week 2

broccoli rabbit carrot tiger ; statetransition dynamics function pMarkov propertyfuture state and reward only depends on the current state and actionp
4.RL Course by David Silver - Lecture 2: Markov Decision Process

David silver youtube\-Markov Reward Process(MRP)Markov Decision Process(MDP)state s fully characterizes your future rewardsso we don't care about rewa
5.RL Course by David Silver - Lecture 3: Planning by Dynamic Programming

Breaking down overall problem to simpler pieces.subproblems occur many times - recursiveBellman equation : how to recursive decompositionVFS
6.RL Course by David Silver - Lecture 4: Model-Free Prediction

TD($$\\lambda$$)
7.RL Course by David Silver - Lecture 5: Model Free Control

off-Policy Learning

9.RL Course by David Silver - Lecture 7: Policy Gradient Methods

Policy Gradient Introduction Finite Difference Policy Gradient Monte-Carlo Policy Gradient Actor-Critic Policy Gradient