Markov Decision Processes
Lesson 1: Introduction to Markov Decision Processes
Markov Decision Processes


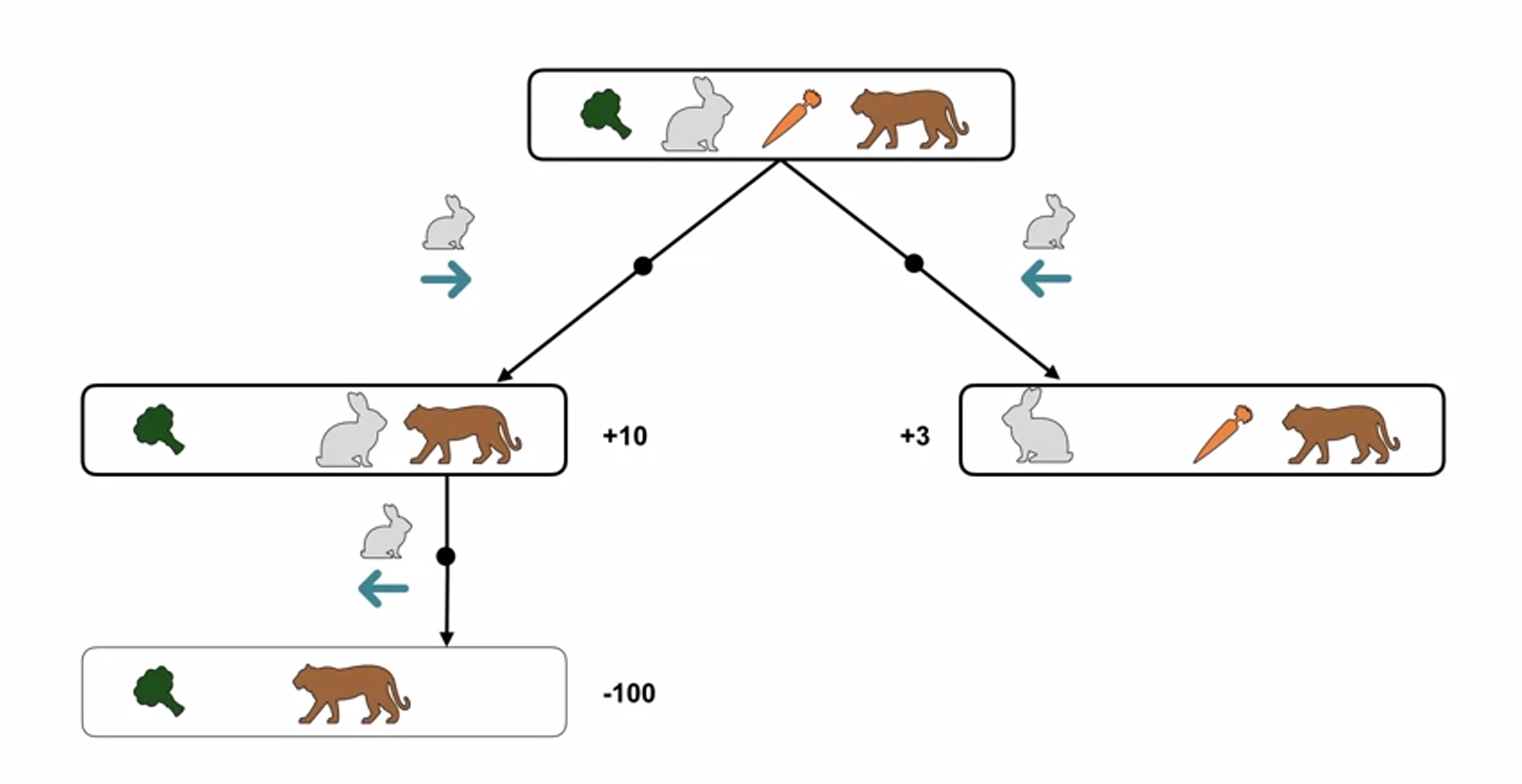
- broccoli rabbit carrot tiger ; state
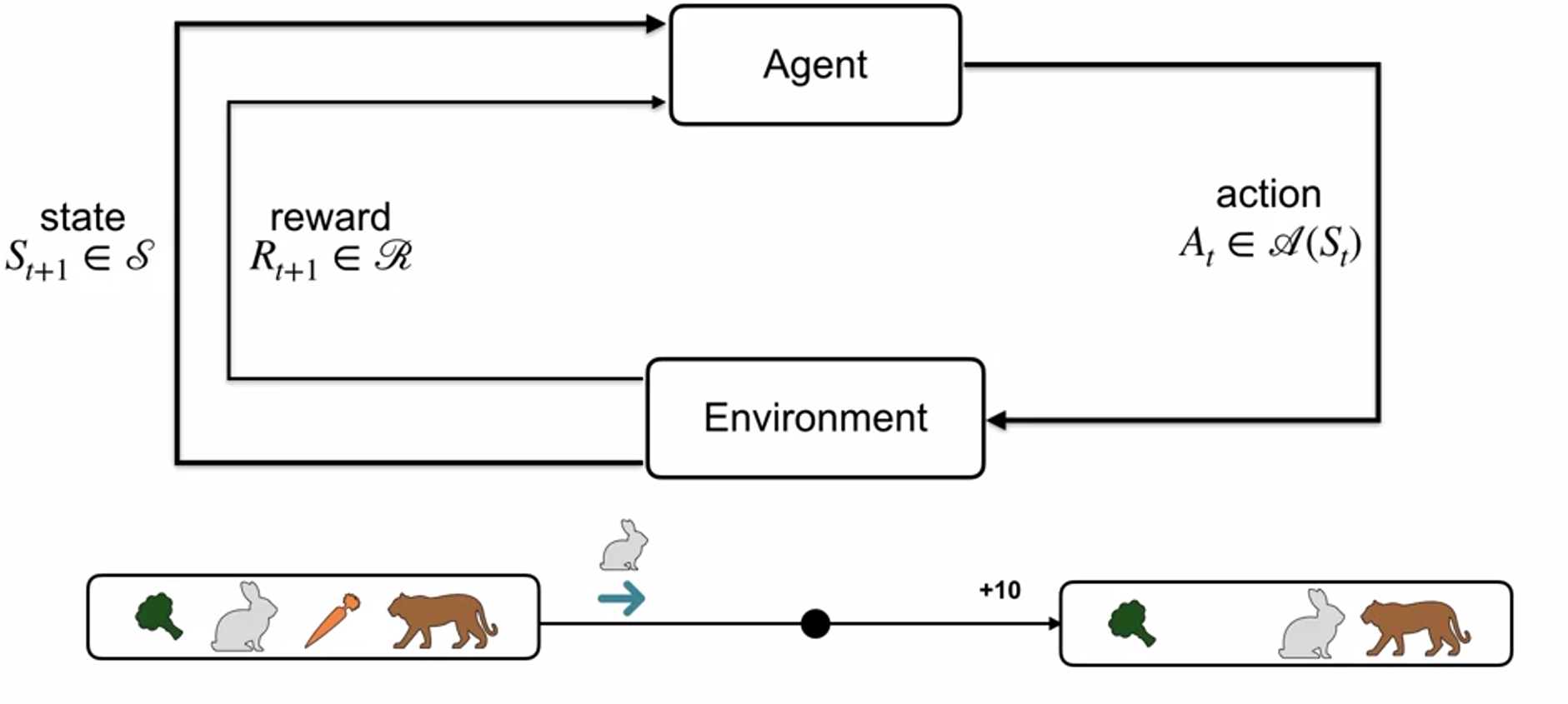
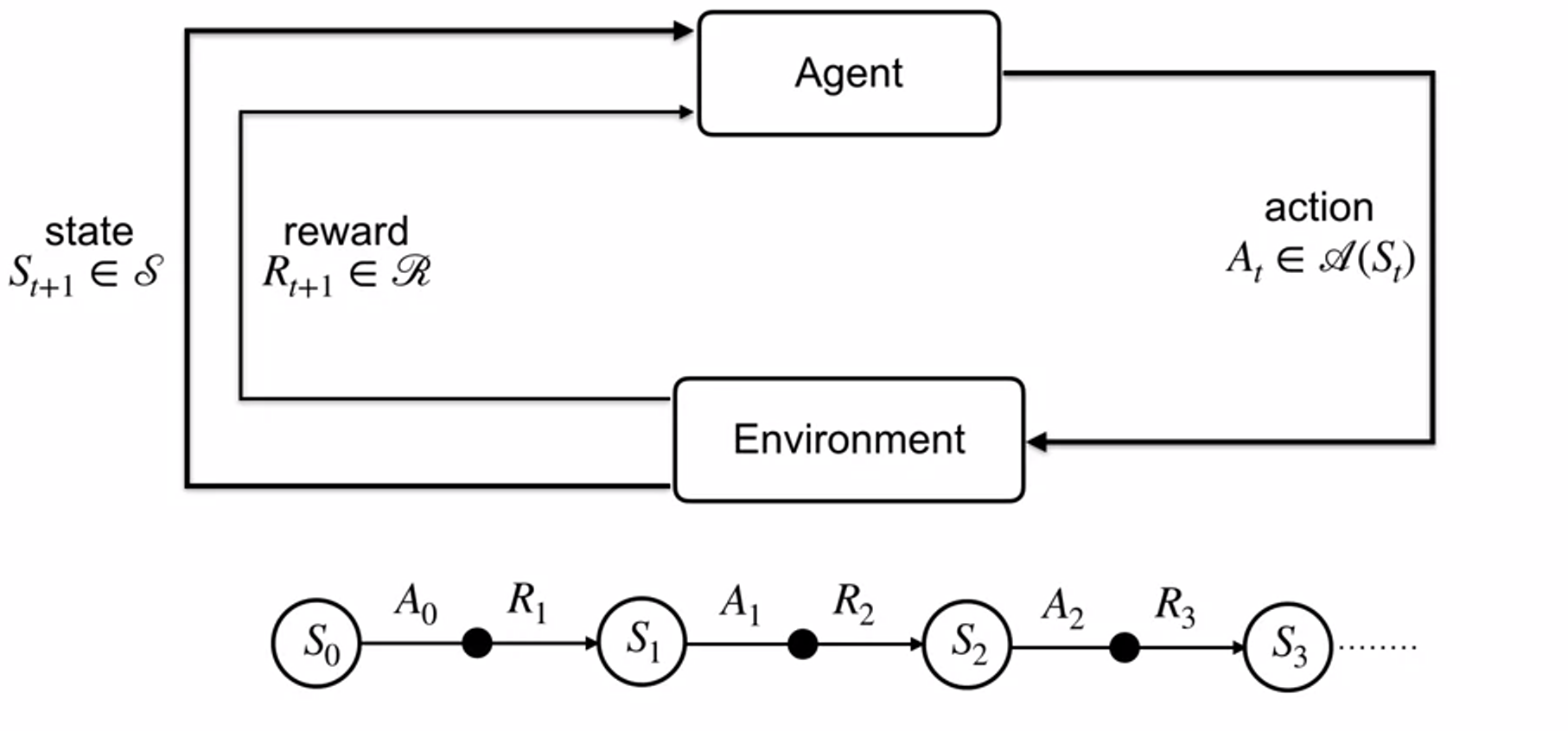

- transition dynamics function p
- Markov property
- future state and reward only depends on the current state and action
- present state is sufficient and remembering earlier states would not improve prediction
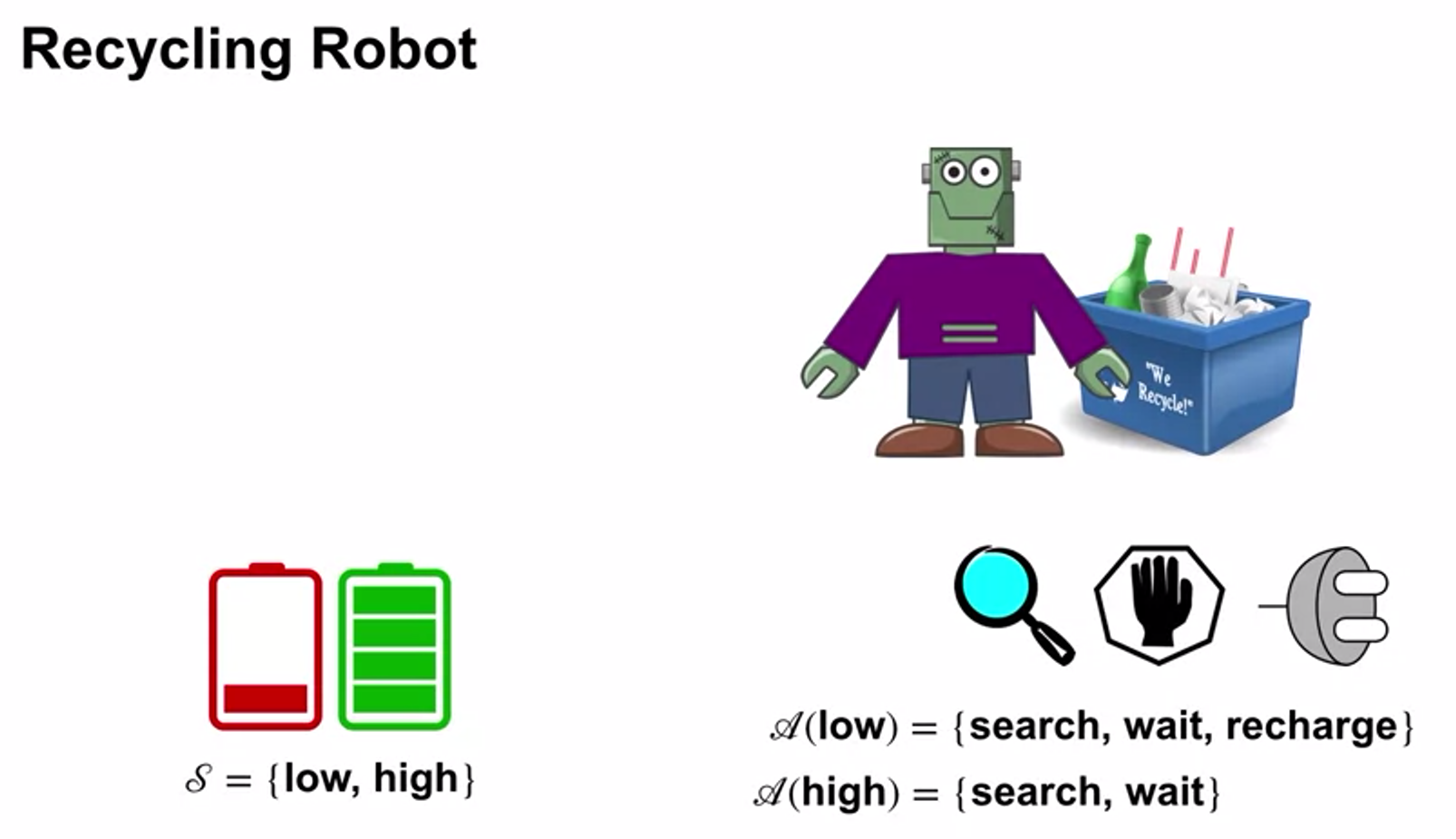
Examples of MDPs
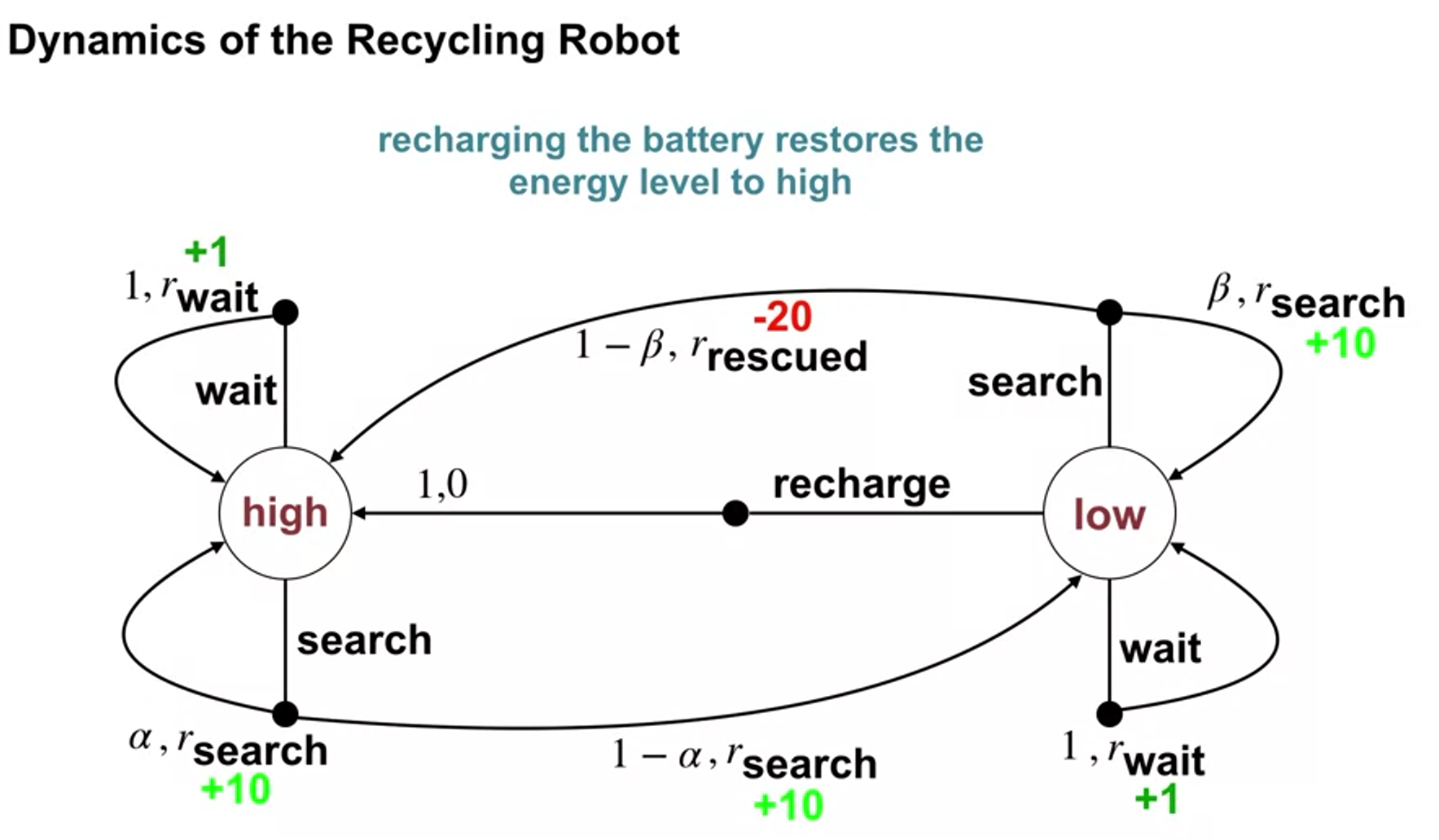

-
return is random variable because
- the dynamics of MDP can be stochastic확률론적

- the dynamics of MDP can be stochastic확률론적
-
to be well defined the sum of rewards must be finite
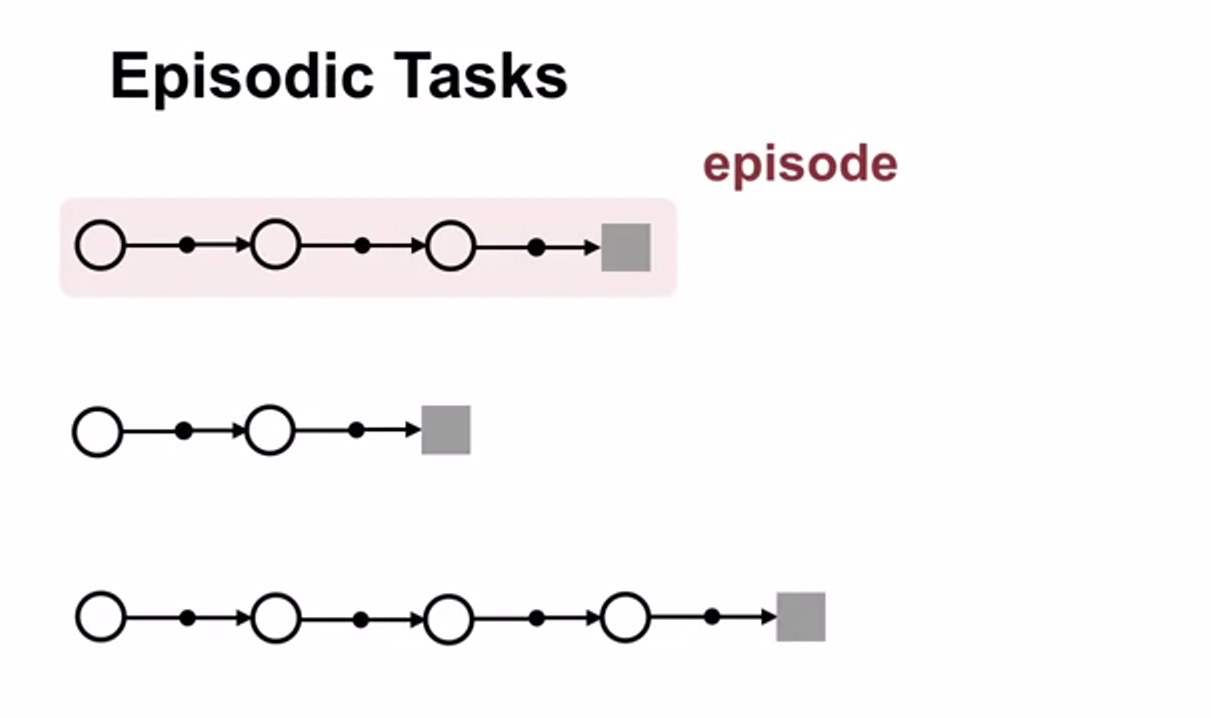
-
when interaction ends
- interaction breaks into chunks called episode
- each episode begins independently of how previous ended
- At termination the agent is reset to start state
- every episode has terminal state(final state)
-
we call these tasks episodic tasks
Lesson 2: Goal of Reinforcement Learning
Michael Littman: The Reward Hypothesis
- even if we accept reward hypothesis still need to define right reward
- point the agent right direction


