-Markov Reward Process(MRP)




- Markov Decision Process(MDP)

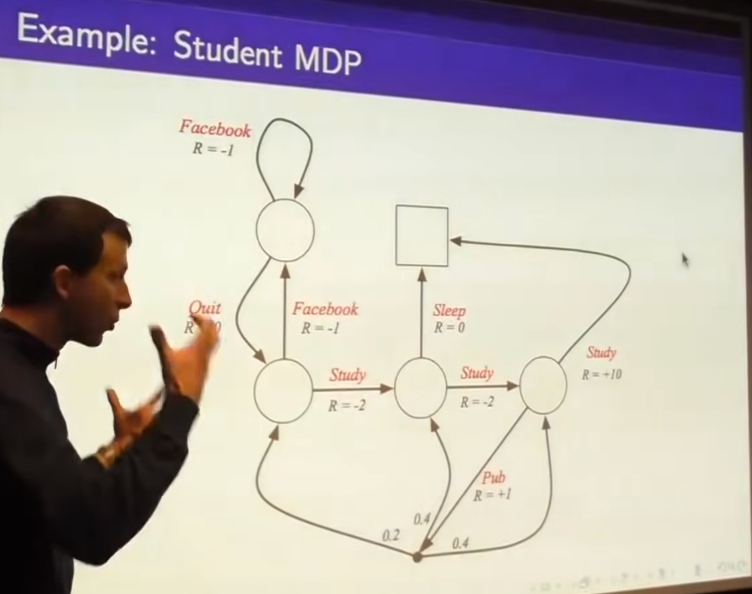

- state s fully characterizes your future rewards
- so we don't care about reward past because it's already consumed
- What we want is maximize the reward from now on


- how good is it to be in state s if I following policy


- white to black possibility is defined by policy
is q value(action value)

- state value function
action value function

- put two together
- is relative to
- reculsive relationship

- you can do it to action values
- as well is relative to
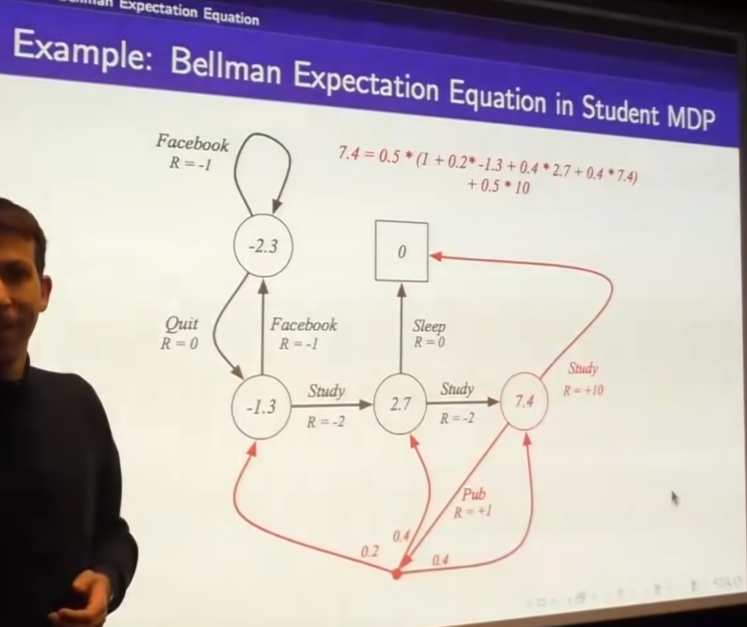
- beneth black dot is to show the process


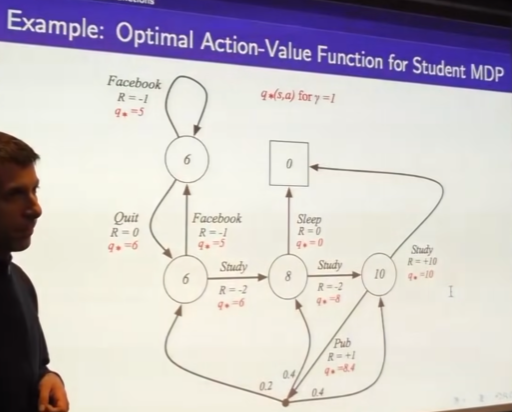

-
there is always at least one optimal policy p* that is better than or equal to all other policies
-
It is possible there is more than one optimal policies same action take you to the same state.


-
we get q we can calculate MDP but how to arrive at q, figuring out q*
-
Bellman optimality equation
-
look at the value of each action you can take and pick the max of them.
-


- look optimal value we end up, back these things all the up to

- just reordering for q*
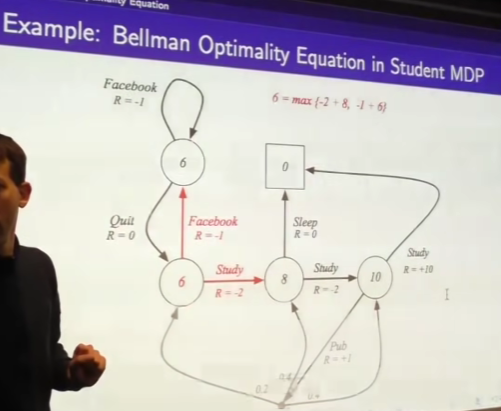
- 귀납적으로Inductively

- dinamic programming method will solving these resculsive equation
