RL Course by David Silver - Lecture 4: Model-Free Prediction

Monte-Carlo Learning

- Caveat(warning) : this only works with episodic MDP






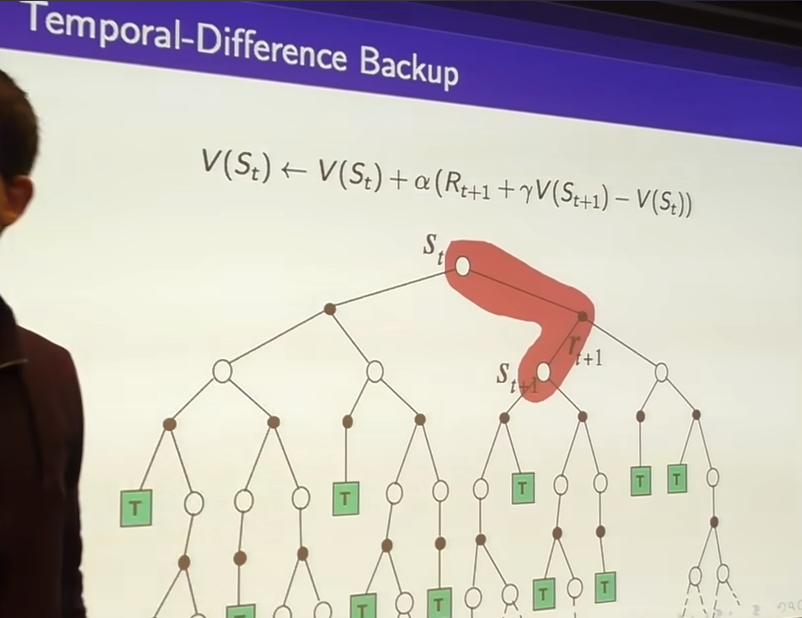
Temporal-Difference Learning


- TD target : Rt+1+γV(St+1)
- When driving you almost crashed toward other card but didn't. Monte carlo doesn't update because didn't crashed.

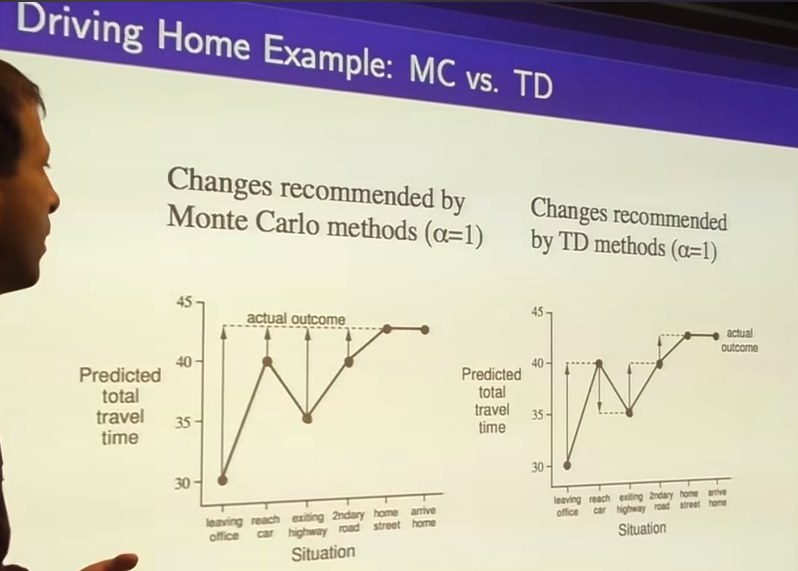
- with Monte carlo learning you update toward actual outcome, wait until you finally get there.
- with TD learning immediately update.
- there is no actions here we just trying to do policy estimation.

- during the TD learning all of your guesses are progressively becoming better and that information backs up such that you get the correct value function.

- TD target much lower variance because we're only looking at the noise over the first step
- the state that you see is noisy but the value function that

- we are not bootstrapping from initial value
- what is bootstrapping?
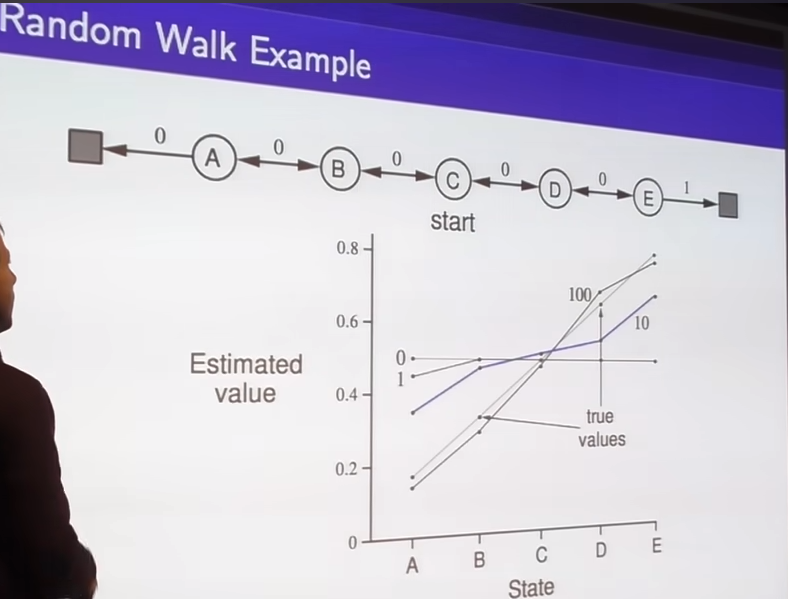
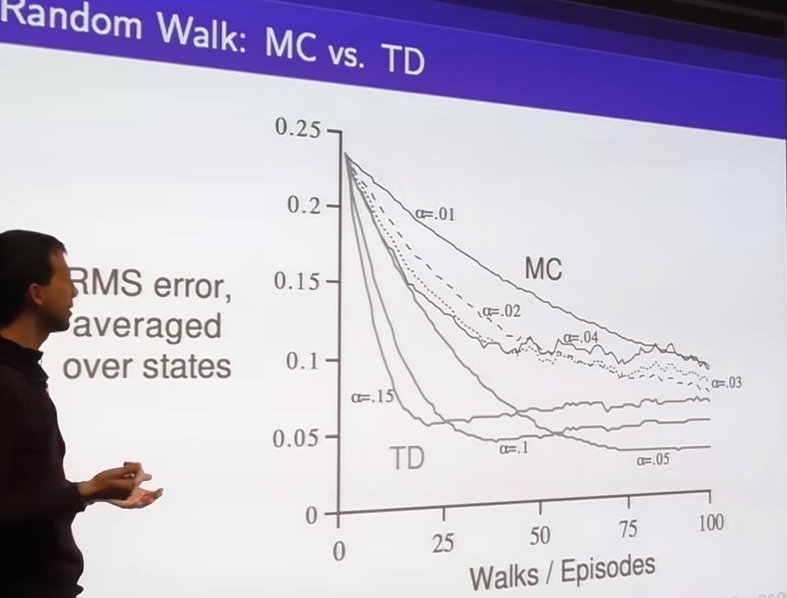
- when appropiately chosen step sizes, TD continues to do better than monte carlo.
- effect of bootstrapping, as above linked blog if you chose wrong step size, for example large step size you will oscillate(vibrate?) around the True Value function. you dont guaranteed to converge all the way to the optimal solution.




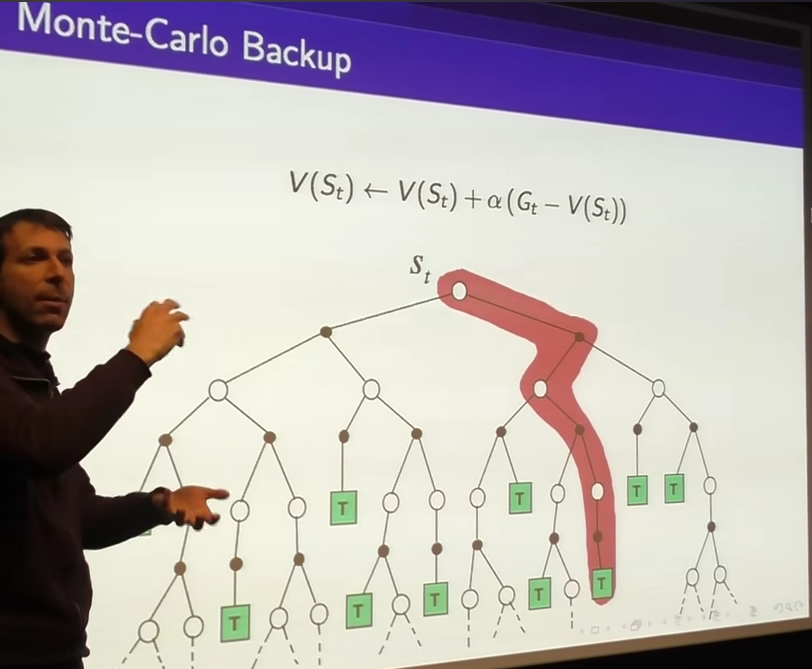


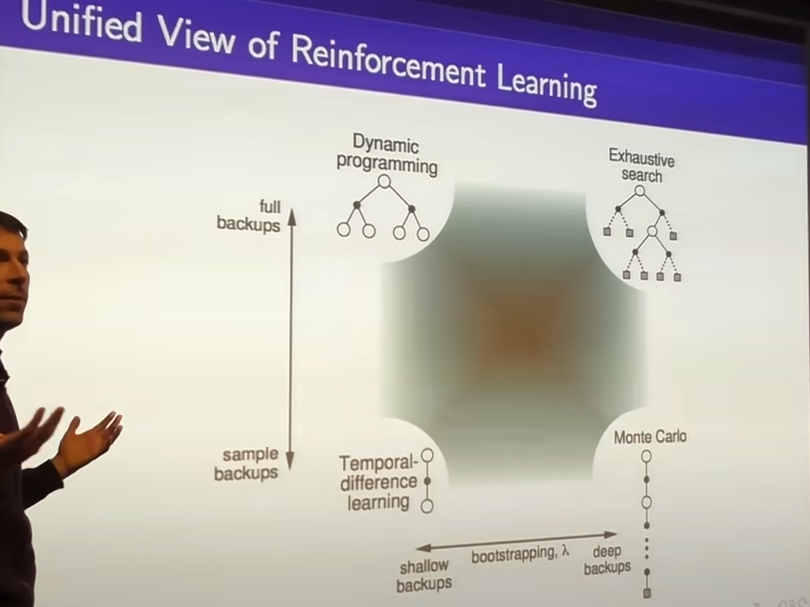
TD(λ)
