
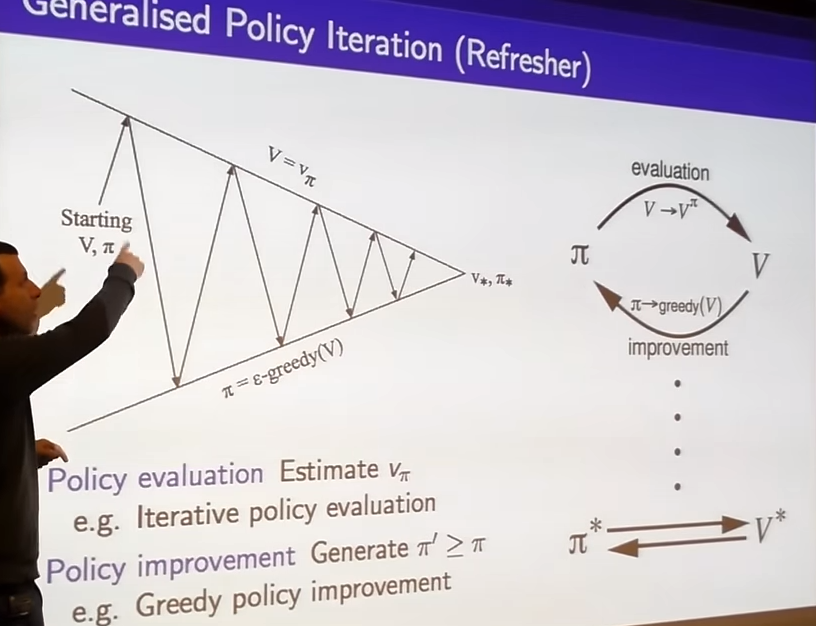
On-Policy Monte-Carlo Control

- by caching the values of our actions we kind of reduce the burden of what we required from our model
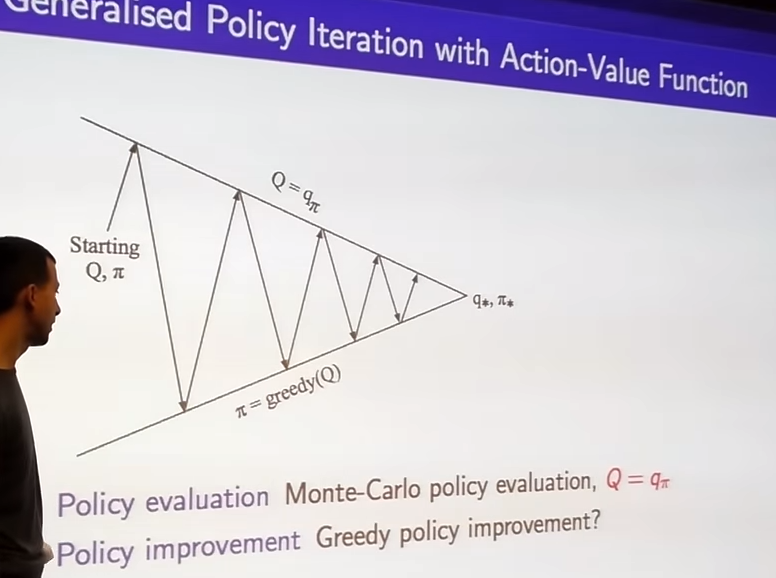
- the issue raised from we're acting greedily as our policy improvemnet step
- you act greedily you can get stuck, you can actually not see the states which you need in order to get a correct estimate of the value function.

- greedy action selection!
- Monte-carlo estimatie of the value stuck to right door in this case
- Is this real best choice in real world?
- You don't have to explore again?

- Wow! E psilon-greedy algorithm!
- This might seem naive but it has some nice properties
It guarantees that you continue to explore, that actually improve your policy
- This might seem naive but it has some nice properties

- prove that -greedy really progress
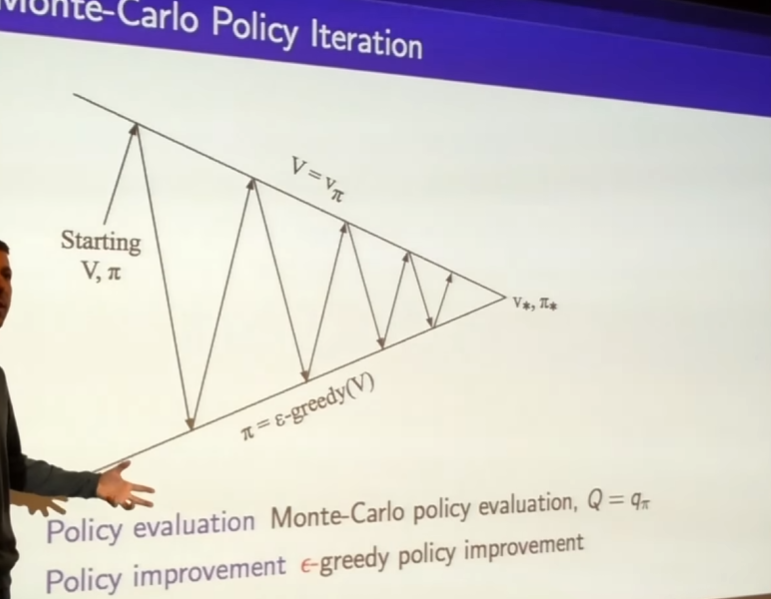
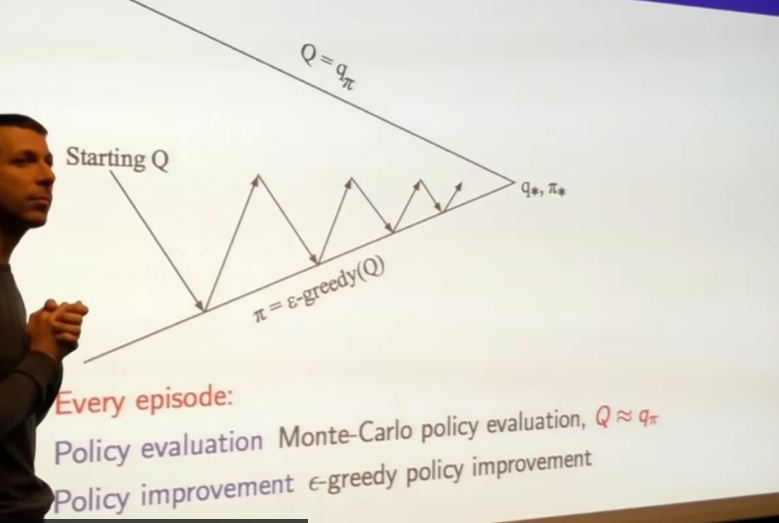
- why not do this every single episode?
- one episode -> update Q value
- update policy

-
how can we guarantee that we find the best possible policy
-
we have to balance two different factors
- we continue exploring to find better thing
- we make sure that asymptotically점진적 we arrive at best policy that not explore anymore

- GLIE idea
- every action from reachable states will be tried
- needs to become greedy to staisfy the Bellman equation; Bellman optimality equation requires a Max in there
- one simple idea is choose epsilon-greedy and decaying epsilon slowly

- start off by sampling episodes
- we run one episode that generates a trajectory of states actions rewards until we get to some terminal state
- we sample that from our current policy pi
- for each of those states and actions we update our action vaalue
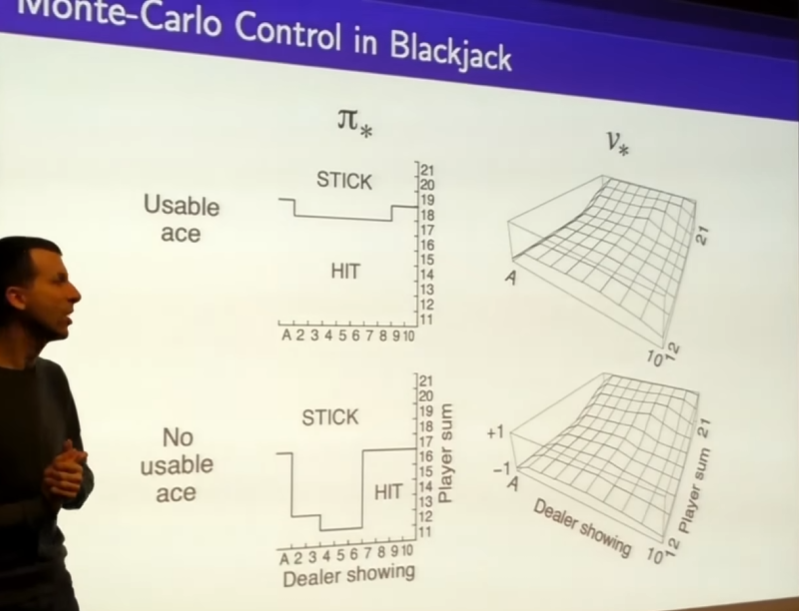
- out of these value functions really characterize exaxtly the optimal behavior in this domain. ends up with something which is the optimal policy

-
how can we actually gain efficiency by boorstrapping
- 강화학습에서 부트스트래핑이란, 예측값을 이용해 또다른 값을 에측하는것을 말한다.
"내일 날씨가 흐릴것 같으니, 모레는 아마 비가오겠네"
- 강화학습에서 부트스트래핑이란, 예측값을 이용해 또다른 값을 에측하는것을 말한다.
-
always using the most recent value function to pick your action -> increase the frequancy of our policy improvement to be evey single time step we're going to improve our policy

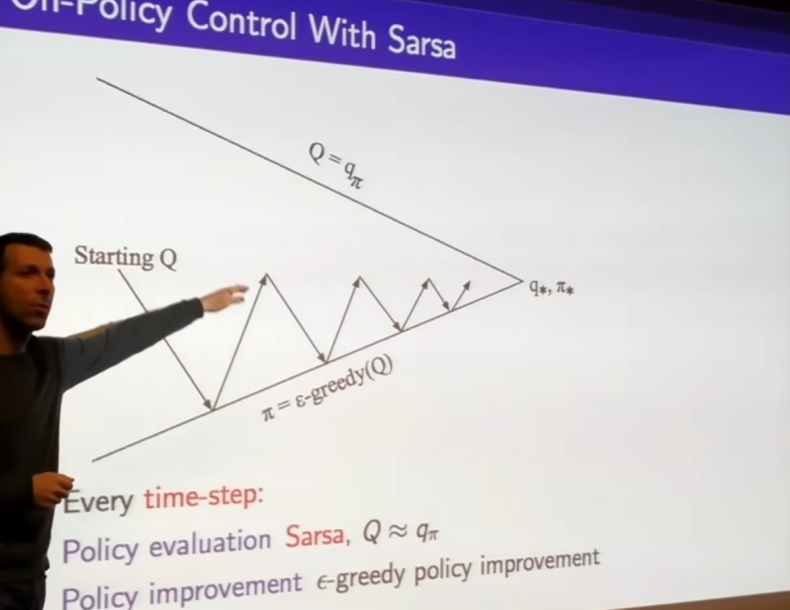
- we're going to plug sarsa update in to out generalized policy iteration framework

- Target (R + Q(, )) is sample of Bellman equation
- we want to consider an expectation over everything which happens in the environment over one step (= Reward + next state)
- we want to know what would happen under our own policy, want the expectation under our own policy from that state onwards = what we're trying to evaluate with Q - > that why we select action using the policy that we're trying to evaluate = on policy algorithm
즉 we're selecting actions and evaluating policy

- empirical result; in practice sarsa will working without knowing this knowledge. this is theory
- if stepsize are sufficiently large you can move Q value as far as you want

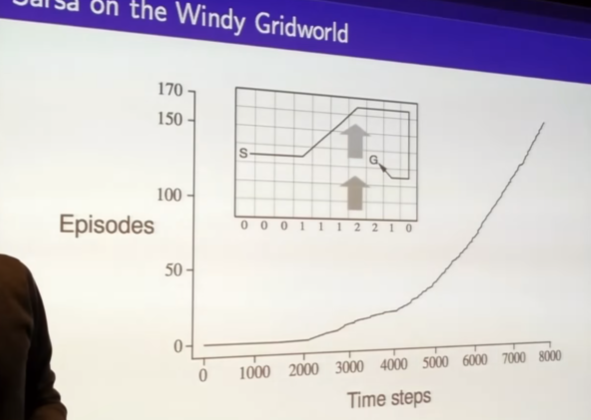
- naive version of sarsa

-
all the way until the end of the episode never bootstrap from value function
-
target : n step reward
-
Q is expected total reward you get - start in state and take action and then follow policy for subsequent actions
- n step reward is just our target

-
가중평균
-
build a spectrum between MC and TD so we've got variant of sarsa that can look all the way out to the future
- if we set lambda to 1 it turns into MC learning if set to 0 familiar sarsa
- problem is that we're kind of looking forward in time. this isn't online. we have to wait until the end of the episode to able to compute Q lambda

- Eligibility Trace
- at the end of episode you get a big carrot
- eligibility trace is estimate of which state and actions were responsible for receiving that carrot



-
behavior policy
-
Big issue in reinforcement learning
- explore the state space effectively
- at the same time we want to learn about the optimal behavior which doesn't explore at all
-
내가 원하는 만큼 돌아다니는 explore policy를 가지면서 동시에 optimal policy도 learn하고싶어!
- off policy learning의 필요성

- first mechanism
- important sampling

- MC learning is useless in off policy
- extremely high variance
- in practice useless

- have to use TD learning becomes imperative to booptstap
- only need to important sample over one step
- after one step just bootstrap
- still could be high variance but better than MC

-
Q Learning
-
specific to sarsa0
-
we're going to make use of Q values, action values to help us do off policy learning in efficient way that doesn't require important sampling
-
sampling from behavior policy
-
sampling from tartget policy
-
consider the real behavior you actually took
- considering the trajectory you're actually following
- but every step you're also considering some alternate action -> bootstrap from Q value
-

- we tring to learn greedy behavior while following some exploratory behavior
- both policy can improve
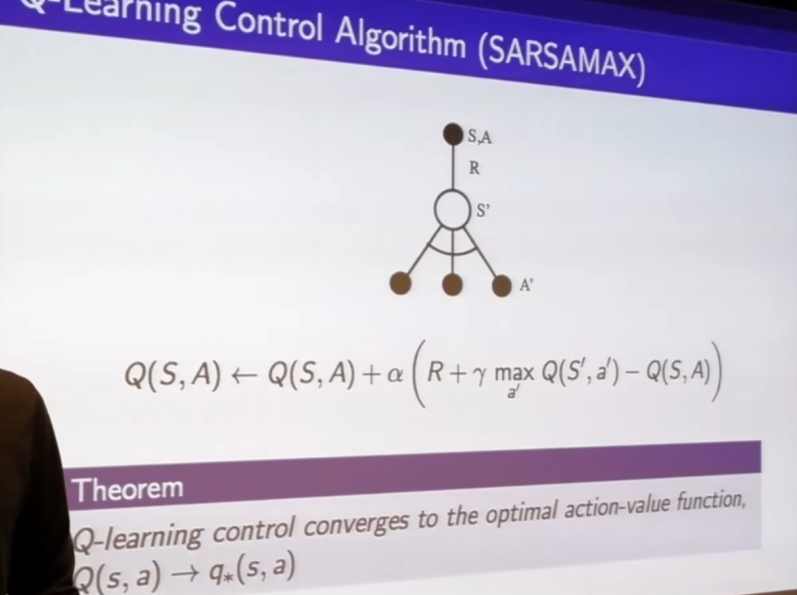
- just like bellman optimality equation
- this algorithm again converges to optimal action-value function

