
다중 선형회귀란?
앞서 다룬 가 1개인 선형회귀를 단순 선형 회귀라고 합니다(Simple Linear Regression)이라고 합니다.
이번 게시글에서는 다수의 값으로부터 를 예측해 (의 예측값)을 구하는 다중 선형 회귀(Multivariable Linear regression)에 대해서 다뤄보려고 합니다.
기본적으로 다중선형회귀(Multivariable Linear regression)의 수식은 아래와 같이 표현합니다.
여기서 는 번째 관측치를 의미하고, 는 이때의 오차항을 나타낸다고 볼수있습니다.
더욱 쉽게 예를들어 수식을 보여 드리겠습니다.
독립변수()의 갯수가 3개인 데이터를 가정하고 이를 수식으로 표현한다면 아래와 같이 나타낼수있습니다.
다중 선형회귀는 여러개의 특성을 이용해 종속변수()를 예측하기때문에 단순 선형 회귀(Simple Linear Regression) 보다 더 좋은 성능을 기대할 수 있습니다.
tensorflow로 구현하기
import tensorflow as tf
import matplotlib.pyplot as plt
# 가중치(weight)와 편향(bias) 변수 설정
w1 = tf.Variable(tf.random.uniform([1]))
w2 = tf.Variable(tf.random.uniform([1]))
w3 = tf.Variable(tf.random.uniform([1]))
b = tf.Variable(tf.random.uniform([1]))
#input DATA
label_x1=[10,30,40,60,70]
label_x2=[34,12,44,22,50]
label_x3=[12,4,34,5,30] #input data [[x1],[x2],[x3]]
#output DATA
label_y=[61,54,140,91,165] , , 는 와 각각 일정한 관계를 형성하는데 의 1배, 는 1/2배, 는 2배를하여 합산한 후, 10을 더한 값이 값이고 이때, 가중치인 1, 1/2, 2와 편향(bias)값 10을 tensorflow로 구현 했습니다.
(시각화를 위해 matplotlib module 사용)
#loss function 정의
def loss_function():
# w*x는 행렬 곱셈 후, bias를 더하여 pred_y를 계산
pred_y = w1*label_x1+w2*label_x2+w3*label_x3+ b
#평균 제곱근 오차(Mean squared error)를 손실함수(loss function)으로 활용
cost = tf.reduce_mean(tf.square(pred_y - label_y))
return cost
#보편적으로 가장 많이 사용하는 adam optimizer 활용
optimizer = tf.optimizers.Adam(learning_rate=0.01)
#훈련시키기
for step in range(10000):
cost_val=optimizer.minimize(loss_function, var_list=[w1,w2,w3,b])
if step % 100 == 0:
#훈련값 출력
print(step,"loss_value:", loss_function().numpy(), 'weight:', w1.numpy(),w2.numpy(),w3.numpy(), 'bias:', b.numpy()[0])
그후에, 위의 코드처럼 손실함수(Loss Function)를 정의합니다.
"loss_function()" 는 가중치()와 편향()의 근사값(aprroximation)을 계산하여
pred_y () 값을 도출 한 후,
평균제곱근오차(Mean squared error)를 손실함수(loss function)로 사용하여 손실(loss)값을 도출합니다.
위의 코드실행시,
0 loss_value: 4113.4165 weight: [0.21614416][0.6817139] [0.68471926] bias: 0.4158159
100 loss_value: 31.997961 weight: [0.84116334][1.28458] [1.2926637] bias: 1.0301762
200 loss_value: 21.219238 weight: [0.89849293][1.2736114] [1.301684] bias: 1.0553204
300 loss_value: 17.472715 weight: [0.9310127][1.2351427] [1.2942951] bias: 1.0563219
400 loss_value: 15.034409 weight: [0.9574311][1.198134] [1.2985377] bias: 1.0580286
500 loss_value: 13.38927 weight: [0.9768822][1.1638432] [1.3138039] bias: 1.0617847
.
.
.
이와 같은 결과들을 확인 할수 있으며, 각각 손실값(loss_value), 가중치(weight),편향(bias)의 값들을 확인할 수 있습니다.
위에서 구한 가중치( : weight)와 편향( : bias)값을 이용해 값을 예측하여 실제 값과 비교하여 시각화를 해보았습니다.
pred_y_list= w1*label_x1+w2*label_x2+w3*label_x3+ b#
print(pred_y_list) #실제 y값과 비교
data_number=[1,2,3,4,5]
# 실제 데이터 시각화
plt.title("Orginal data")
plt.xlabel("data number")
plt.ylabel("Label Y value")
plt.plot(data_number, label_y, 'ro', label='Original data')
plt.show()
# 예측 데이터 시각화
plt.title("Predicted value")
plt.xlabel("data number")
plt.ylabel("Predicted Y value")
plt.plot(data_number, pred_y_list,'bo', label='Predicted data')
plt.legend()
plt.show()다음의 코드를 작성하고 시각화 된 결과를 확인해보면,
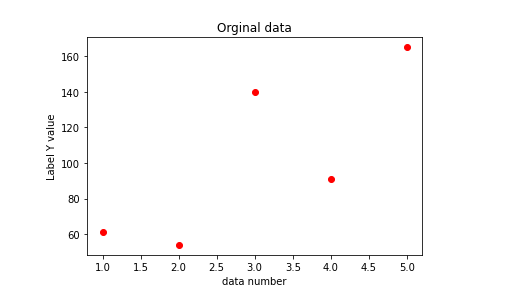
원래의 데이터는 이러한 결과를 확인할수있고,
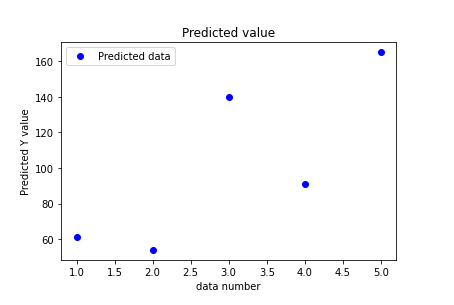
예측데이터의 경우 다음과 같은 결과를 확인 할 수 있습니다.
또, 다중 선형 회귀 모델은 행렬(matrix)계산을 통하여 구해볼 수 있는데, 이경우 위와 같은 방법처럼 가중치( : weight)와 편향( : bias)값을 여러개 설정하여 값을 구하지 않아도 됩니다.
위와 같은 방법도 코드로 설명 드리면서 다중선형회귀(Multivariable Linear regression)를 마치겠습니다.
import tensorflow as tf
import matplotlib.pyplot as plt
# 가중치(weigh)와 bias 변수 설정
#weight 1*3 행렬(matrix)을 변수로 설정
w = tf.Variable(tf.random.uniform([1,3]))
b = tf.Variable(tf.random.uniform([1]))
#input DATA
label_x=[[10,30,40,60,70], [34,12,44,22,50], [12,4,34,5,30]] #input data [[x1],[x2],[x3]]
#output DATA
label_y=[61,54,140,91,165] , , 는 와 각각 일정한 관계를 형성하는데 의 1배, 는 1/2배, 는 2배를하여 합산한 후, 10을 더한 값이 값이고 이때, 가중치( : weight)인 1, 1/2, 2와 편향( : bias) 10을 코드로 구현했습니다.
def loss_function():
# w*x는 행렬 곱셈 후, bias를 더하여 pred_y를 계산
pred_y = tf.matmul(w,label_x) + b
cost = tf.reduce_mean(tf.square(pred_y - label_y))
return cost
#보편적으로 가장 많이 사용하는 adam optimizer 활용
optimizer = tf.optimizers.Adam(learning_rate=0.01)
#훈련시키기
for step in range(10000): #train
cost_val=optimizer.minimize(loss_function, var_list=[w,b])
if step % 100 == 0:
#훈련값 출력
print(step,"loss_value:", loss_function().numpy(), 'weight:', w.numpy(), 'bias:', b.numpy()[0])
그후에, 아까의 코드처럼 손실함수(Loss Function)를 정의합니다.
loss_function() 는 는 행렬 곱셈 후, 편향( : bias)를 더하여 pred_y를 계산,
pred_y () 값을 도출 한 후,
평균제곱근오차(Mean squared error)를 손실함수(loss function)로 사용하여 손실(loss)값을 도출합니다.
위의 코드의 실행 결과로,
0 loss_value: 3369.308 weight: [[0.36058468 0.9976525 0.09665639]] bias: 0.97861356
100 loss_value: 47.571087 weight: [[0.9281533 1.5568345 0.6825515]] bias: 1.5304638
200 loss_value: 43.12451 weight: [[0.93470854 1.5347482 0.74352884]] bias: 1.4877094
300 loss_value: 38.57496 weight: [[0.9369372 1.4963375 0.80844057]] bias: 1.4284222
400 loss_value: 33.86727 weight: [[0.94202626 1.4509988 0.87875855]] bias: 1.366013
500 loss_value: 29.283932 weight: [[0.9494812 1.4010429 0.951631 ]] bias: 1.3053689
.
.
.
위와 같은 결과를 보실 수 있으며, 아래와 같은 코드로 이를 시각화 할 수 있습니다.
#위에서 구한 가중치(weight)와 편향(bias)값을 이용해 y값 예측하기
pred_y_list= tf.matmul(w,label_x)+b
print(pred_y_list) #실제 y값과 비교
data_number=[1,2,3,4,5]
# original data plot
plt.title("Orginal data")
plt.xlabel("data number")
plt.ylabel("Label Y value")
plt.plot(data_number, label_y, 'ro', label='Original data')
plt.show()
# predicted value plot
plt.title("Predicted value")
plt.xlabel("data number")
plt.ylabel("Predicted Y value")
plt.plot(data_number, pred_y_list[0],'bo', label='Predicted data')
plt.legend()
plt.show()
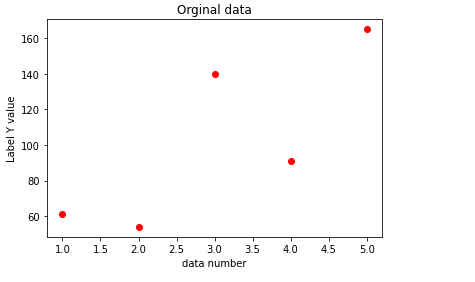
원래의 데이터는 위와같은 값을 확인 하실 수 있고,
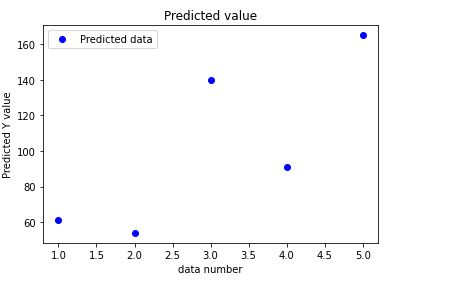
예측데이터는 이와같은 결과를 보실 수 있었습니다.
마무리
본 게시글에서는 다수의 값으로부터 를 예측해 (의 예측값)을 구하는 다중 선형 회귀(Multivariable Linear regression)모델에 대해서 알아 보았습니다.
다음 게시글에서는, 로지스틱 회귀 분석(Logistic Regression)에 대해 적어보도록 하겠습니다.
감사합니다.
