
선형회귀(Linear Regression)란
가장 간단하며 딥러닝(Deep Learning)의 기초가 되는 머신러닝(Machine Learning)알고리즘으로, 데이터를 가장 잘 표현하는 일차함수식을 만드는 것 입니다.
일반적으로 우리가 알고있는 일차함수식은
일 것입니다.
이것을 머신러닝(Machine Learning)에서 사용하는 방식으로 바꾸면
{: 독립변수, : 목표값, : 가중치, : 편향}
라고 할수있습니다. (은 를 예측하기 위한값)
이는 곧, 선형회귀(Linear Regression)의 목표는
(예측값)이 에 가장 가까워 질수있는 가중치( : wight)와 편향( : bias)을 찾는것이라는 결론을 알 수 있고 "가장 훌륭한 예측선 긋기" 라고 요약할 수 있습니다.
아래 코드는 선형회귀의 식인 에서 가중치( : wight) 값과 편향( : bias)값을 python 환경의 Tensorflow에서 구현하여 찾아보고자 합니다.
tensorflow로 구현하기
import tensorflow as tf
import matplotlib.pyplot as plt
w = tf.Variable(tf.random.uniform([1])) # 가중치(weight) 변수 설정
b = tf.Variable(tf.random.uniform([1])) #편향(bias) 변수 설정
#input 데이터와 ouput 데이터 설정
label_x=[0,1,2,3,4,5,6,7] #input data
label_y=[20,23,25,30,33,34,35,43] #output data먼저 사용할 모듈인 tensorflow를 import 해줍니다.
시각화를 위해 matplotlib도 import 하겠습니다.
그다음 가중치와 편향의 변수를 설정해주고,
모델설계를 위한 간단한 데이터를 입력해줍니다.
def loss_function():
pred_y = w*label_x + b # y=wx+b 식 수립
#평균 제곱근 오차(Mean squared error)를 손실함수(loss function)으로 활용
cost = tf.reduce_mean(tf.square(pred_y - label_y))
return cost
#보편적으로 가장 많이 사용하는 adam optimizer 활용
optimizer = tf.optimizers.Adam(learning_rate=0.01)
#훈련시키기
for step in range(10000):
cost_val=optimizer.minimize(loss_function, var_list=[w,b])
#훈련값 출력
if step % 100 == 0:
print(step,"loss_value:", loss_function().numpy(), 'weight:', w.numpy()[0], 'bias:', b.numpy()[0])
그후에, 위의 코드처럼 손실함수(Loss Function)를 정의합니다.
"loss_function()"는 가중치와 편향의 근사값(aprroximation)을 계산하여
pred_y()값을 도출 한 후,
평균제곱근오차(Mean squared error)를 손실함수(loss function)로 사용하여 손실(loss)값을 도출합니다.
위의 코드실행시,
0 loss_value: 850.86615 weight: 0.2876293 bias: 0.899512
100 loss_value: 599.4607 weight: 1.2538527 bias: 1.8709149
200 loss_value: 413.39368 weight: 2.1229367 bias: 2.7616732
300 loss_value: 281.12723 weight: 2.8869884 bias: 3.5682974
400 loss_value: 191.02238 weight: 3.5422664 bias: 4.291256
500 loss_value: 132.44878 weight: 4.087555 bias: 4.9333043
.
.
.
와 같은 결과를 확인 할수있으며, 각각 손실값(loss value), 가중치(weight),편향(bias)의 값들을 확인할 수 있습니다.
# 위에서 구한 가중치(weight)와 편향(bias)값을 이용해 y값 예측
pred_y_list=w*label_x+b
# 기존 데이터의 값 시각화
plt.title("Orginal data vs Predicted value")
plt.xlabel("X value")
plt.ylabel("Y value")
plt.plot(label_x, label_y, 'ro', label='Original data')
# 예측된 데이터의값 시각화
plt.plot(label_x, pred_y_list,'b', label='Fitted line')
plt.legend()
plt.show()
시각화 해보면 아래와 같은 회귀선을 볼 수 있습니다.
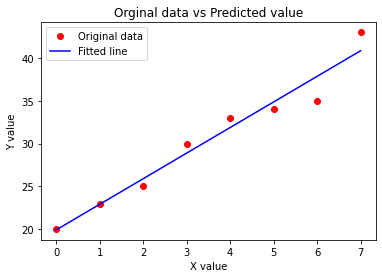
다음은 선형회귀(linear regression)에서의 손실값(Loss Value)을 시각화 해보겠습니다.
plt.title("Loss Graph") #그래프 이름
plt.xlabel("Step") #x값
plt.ylabel("Loss value") #y값은 손실값
plt.plot(loss_arr,step_arr)
plt.show()다음과 같은 코드작성시 위 모델의 손실값을 그래프로 시각화하여 확인 할 수 있으며,
학습이 거듭될수록 손실값은 낮아지는것을 확인할수있습니다.

마무리
오늘 간단히 선형회귀(linear regression)가 어떤 의미인지,
또 그 의미를 간략하게 시각화 하는 법에 대하여 알아보았습니다.
다시 한번 정리하자면 선형회귀는(예측값)이 에 가장 가까워 질수있는 가중치( : wight)와 편향( : bias)을 찾는것 이며, 요약하면 "가장 훌륭한 예측선 긋기" 라고 정리할 수 있다는 것을 코드로써, 시각화하여 알아보았습니다. 다음은 다중 선형 회귀(multivariable linear regression)에 대하여 알고 있는 것들을 정리 해보겠습니다.
감사 합니다.
