(작성자는 비전공자이며, 알고 싶은대로 공부하는 경향이 있어서 고치려고 노력중이고,
틀린게 있으면 시원하게 지적해주세요)
자 이걸 쓰는 이유!
로컬에서만 작업하면 본인 편한대로 파일 구조(Directory)를 짜도 되지만, 서버에서 학습을 시킬 생각이라면 그 구조에 맞게 구조를 짤 수 있으니까!
귀찮으면 Cursor한테
ssh 접속해서 클러스터 구조 파악하고 디렉토리 짜줘.
하면 되긴하지만 구조를 이해해봅시다.
HPC(고성능 클러스터) 기본 구조와 Aurora(Ariel) 서버 디렉토리 안내
https://www.hpc.iastate.edu/guides/introduction-to-hpc-clusters/what-is-an-hpc-cluster
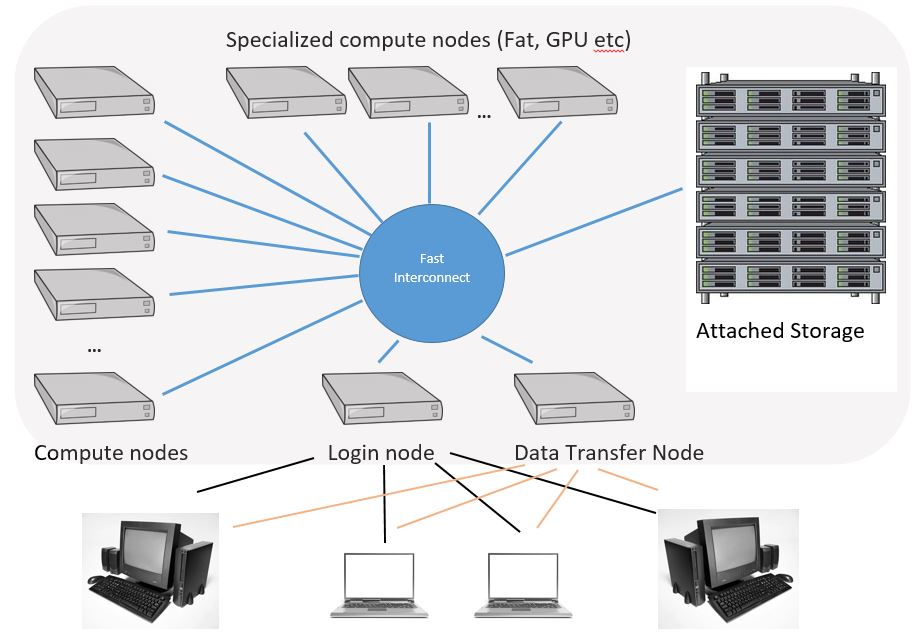
고성능 연산 클러스터(HPC, High Performance Computing)는 여러 대의 독립된 컴퓨팅 노드(node)를 하나의 시스템처럼 묶어 대규모 연산을 수행하도록 설계된 구조입니다. 일반적으로 로그인 노드(Login Node), 계산 노드(Compute Node, GPU/CPU), 관리 노드(Management Node), 그리고 공유 스토리지(Storage Node) 등으로 구성되며, 사용자는 로그인 노드에 SSH로 접속하여 코드를 업로드하고, Slurm과 같은 스케줄러를 통해 계산 노드에 작업(Job)을 제출합니다. 모든 노드는 고속 인터커넥트(InfiniBand 등)로 연결되어 있어 분산 학습, 병렬 연산, 대규모 데이터 입출력 작업을 효율적으로 처리할 수 있습니다. 이러한 구조를 통해 HPC는 단일 컴퓨터로는 수행하기 어려운 대규모 AI 학습, 시뮬레이션, 과학 계산을 안정적으로 실행할 수 있는 환경을 제공합니다.
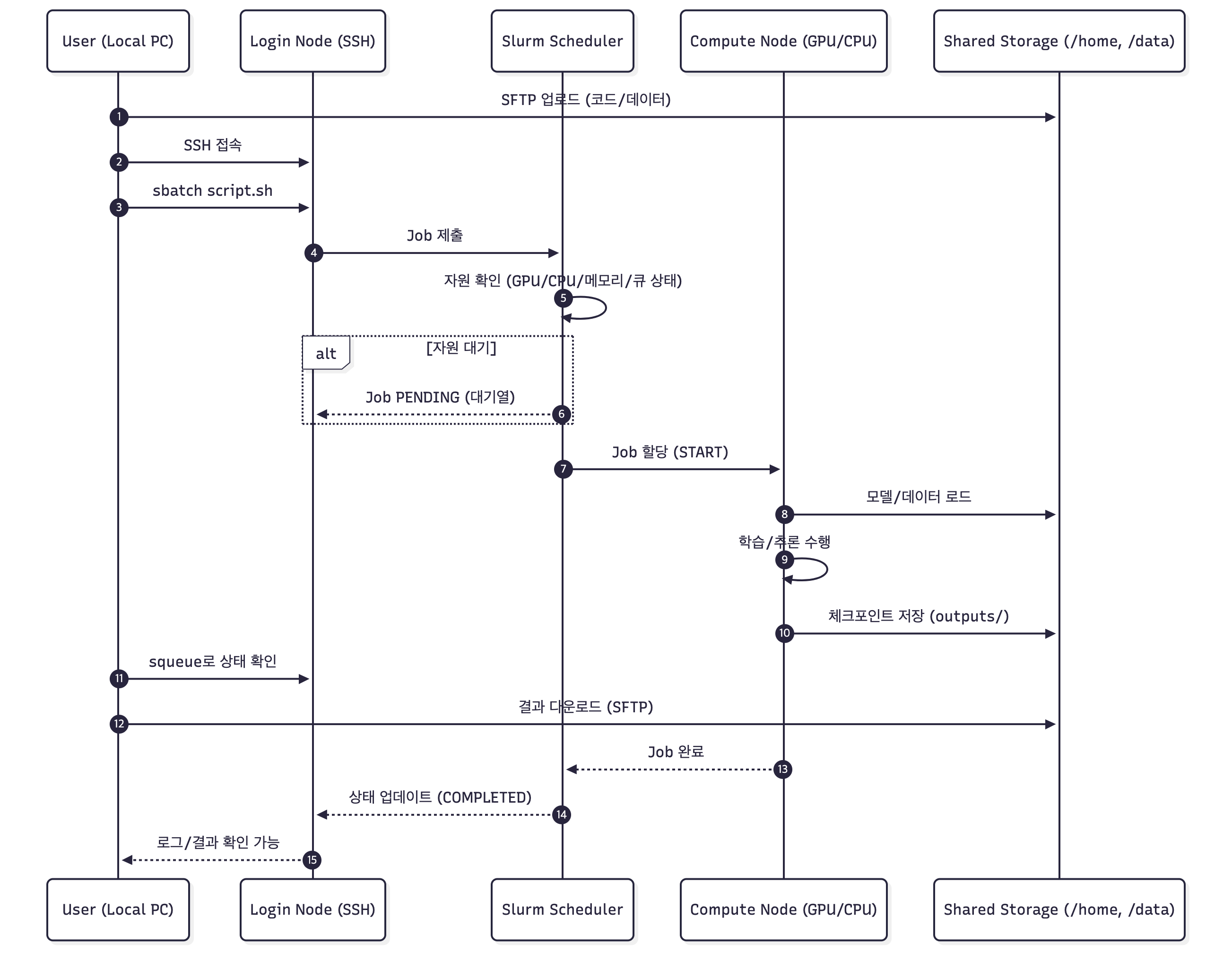
고성능 연산을 위해 제공되는 HPC 클러스터는 로그인 노드, 계산 노드(GPU·CPU), 공유 스토리지 등으로 구성된 분산 컴퓨팅 환경입니다. 사용자는 SSH로 로그인 노드에 접속한 뒤, Slurm을 이용하여 작업을 제출하거나 SFTP로 데이터를 전송하며 대규모 연산을 수행합니다. 이러한 클러스터는 일반적으로 홈 디렉토리(/home/{your_id}) 와 작업 디렉토리(/data/{your_id}) 를 분리해 관리하며, 홈은 용량이 작고 백업이 지원되는 반면, /data 영역은 연구 프로젝트·데이터셋·모델을 저장하는 실질적 작업 공간으로 활용됩니다. (정확히 말하자면, ※ /home은 Slurm 작업 실행 시 I/O 속도가 느릴 수 있으므로, 실제 학습 데이터나 체크포인트 저장은 /data 영역을 사용해야 합니다.
)
대부분의 HPC가 /home, /data, /scratch 계층을 갖추지만, 우리 학교의 Aurora/Ariel 계열 서버는 /home과 /data를 중심으로 구성되어 있으며 /scratch 또는 /local_datasets는 GPU 노드 내부에서만 제공될 가능성이 있습니다(불확실). 따라서 SSH 접속 후 다음 명령어를 실행하여 실제 영역을 확인하는 것이 중요합니다.
# 홈 디렉토리 확인
echo $HOME
pwd
# 마운트된 디스크 확인
df -h
# 대표 디렉토리 존재 여부 검사
ls -la /home 2>/dev/null || echo "/home 없음"
ls -la /data 2>/dev/null || echo "/data 없음"
ls -la /scratch 2>/dev/null || echo "/scratch 없음"
ls -la /local_datasets 2>/dev/null || echo "/local_datasets 없음"
# 환경 변수에서 경로 힌트 찾기
env | grep -i home
env | grep -i data
env | grep -i scratch이 명령어들을 실행하면 Ariel 서버의 스토리지 구조가 /home/{your_id}와 /data/{your_id} 중심인지, 혹은 노드별 임시 스토리지(/scratch, /local_datasets)가 존재하는지를 정확히 확인할 수 있습니다.
자자,,, 위는 그냥 디렉토리 잘 나눠라! 하는 잡도리였고요.
HPC가 뭐냐? 뭔...뭔...뭐냐!! 할겁니다... 저도 몰랐음
이제 HPC 자세히 알려줄건데 이해 안되면 넘겨도 됨.
클러스터 구조를 이해하기 위한 기본 프레임
아래는 “클러스터가 무엇인가?”를 처음 보는 사람도 이해할 수 있게,
몇 개 문단으로 간단하지만 정확하게 정리한 설명이다.
🔵 클러스터(Cluster)란 무엇인가?
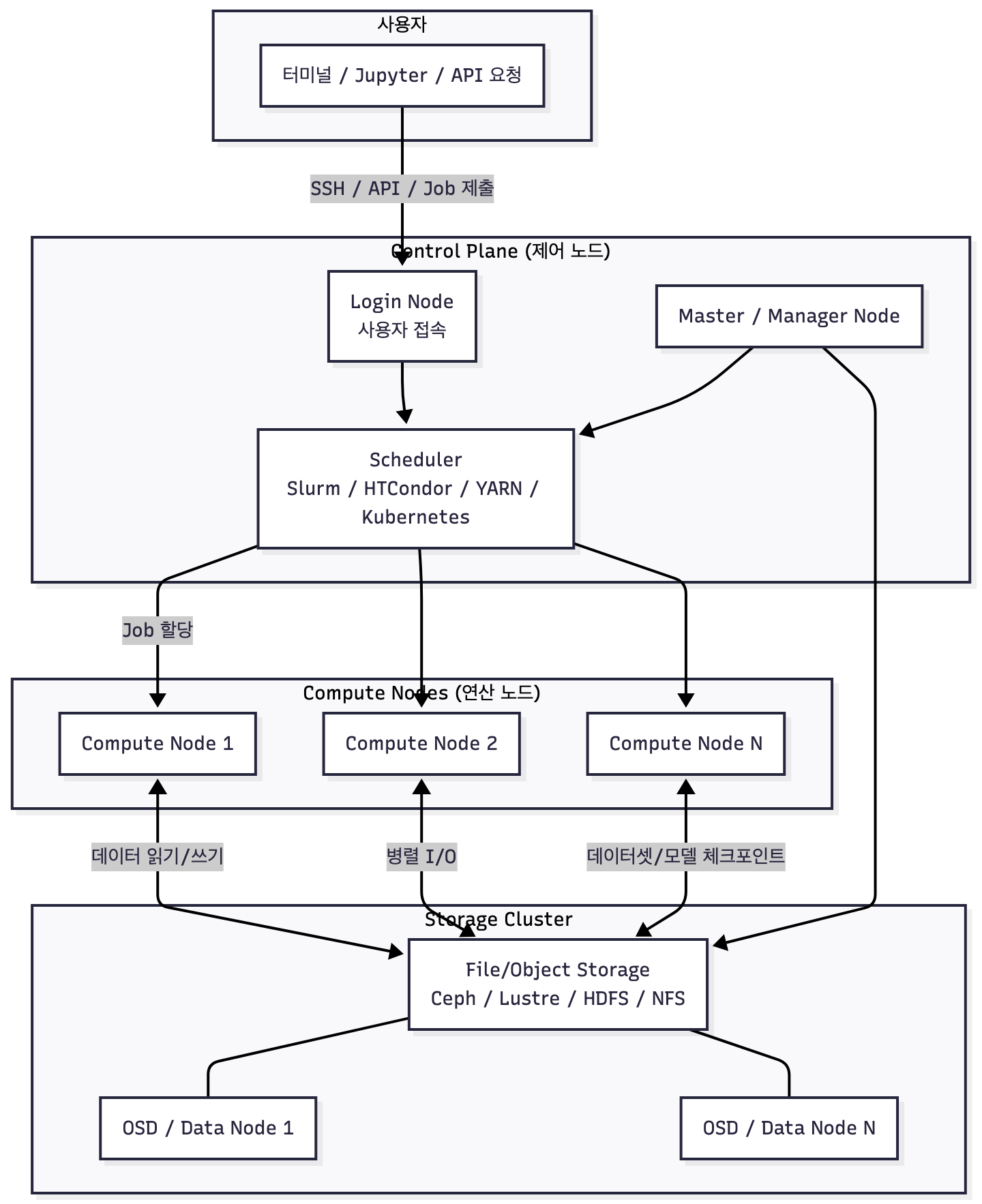
- User → Login Node → Scheduler → Compute Nodes
사용자는 로그인 노드를 통해 접속하고, 모든 작업은 스케줄러가 적절한 노드에 배치한다.- Compute Nodes는 스토리지와 분산 I/O를 수행 (Compute Node는 연산을 수행하고, 데이터는 공유 스토리지(/data 등)에서 읽고 쓴다.)
데이터셋, 중간 산출물, 체크포인트는 모두 Storage Cluster에 저장된다.- Control Plane(Master/Manager)
전체 클러스터의 상태, 스케줄링, 스토리지 메타데이터, 노드 헬스 체크를 담당한다.- Storage Cluster는 Ceph/Lustre/HDFS 등으로 구성
HPC/빅데이터/K8s 모두 Storage Layer만 바뀌고 구조는 동일하다. (~사실 큰 틀에서 “여러 노드를 묶어서 스케줄링한다”는 공통점은 있지만,~)
HPC/빅데이터/K8s는 목적과 실행 방식이 달라 구조가 완전히 같진 않다.
※ 로그인 노드(Login Node)는 계산용이 아니라 명령 제출·환경 설정만 하는 곳입니다.
여기서 직접 학습을 돌리면 다른 사용자의 자원을 침해하게 되므로 반드시 Slurm으로 Job을 제출해야 합니다.
쿠버네티스 클러스터 생각하면 어렵지 않아요! 근데 굳이 또... 서버를 써보기 위해 꼭 당장 알아야한다!의 개념은 아니라고 생각해서 간단히 보고 넘기셔도 될 것 같습니다.
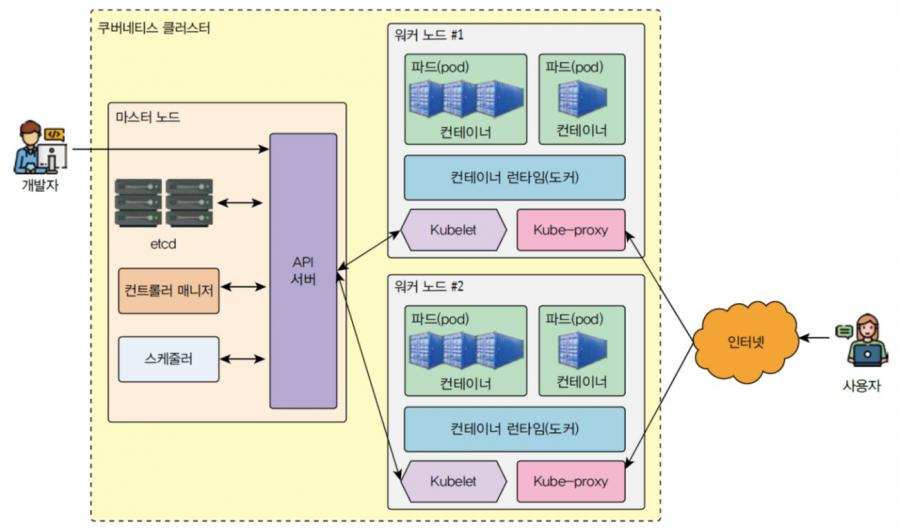
클러스터(Cluster)는 여러 대의 컴퓨터(노드, node)를 하나의 큰 컴퓨터처럼 묶어 사용하는 시스템 구조입니다. 단일 서버로는 처리하기 어려운 큰 연산·데이터·서비스를 분산해서 처리하기 위해 만들어졌으며, 사용자는 마치 하나의 거대한 컴퓨터처럼 접근하지만 실제 내부에서는 수십~수백 대의 노드가 협력해 일하는 거죠!
클러스터의 핵심은 분산(Distributed) 입니다. 하나의 서버가 고장나거나 과부하 걸려도 전체가 중단되지 않도록 여러 노드가 역할을 나눠 수행합니다. 예를 들어 어떤 노드는 계산만 담당하고(Compute Node), 다른 노드는 데이터 저장을 담당(NFS, Ceph, Lustre), 또 다른 노드는 사용자의 명령이나 작업 배치를 관리(Login Node, Scheduler Node)합니다. 이렇게 역할을 분리해 운영하면 성능·확장성·안정성 모두 크게 향상되겠죠?
또한 대부분의 클러스터는 스케줄러(Scheduler) 라는 시스템을 통해 운영됩니다. 스케줄러는 사용자가 제출한 연산 작업(job)을 어떤 노드에 배치할지 자동으로 결정하고, 동시에 여러 사용자가 자원을 공유하도록 관리한다. HPC에서는 Slurm, 데이터 처리에서는 YARN, 서비스 운영에서는 Kubernetes 등이 대표적입니다. 이 스케줄링 시스템 덕분에 수십 명의 사용자가 하나의 클러스터를 공유해도 충돌이나 과부하 없이 효율적으로 사용이 가능합니다.
마지막으로, 클러스터는 목적에 따라 다양한 형태(HPC, HTC, Big Data, Storage, Kubernetes 등)로 나뉜다. 어떤 것은 대규모 연산이 목적이고(HPC), 어떤 것은 수백만 개의 작은 작업 처리가 목표이며(HTC), 어떤 것은 대규모 데이터 저장·가공이 중심이거나(Big Data, Storage), 어떤 것은 웹 서비스나 모델 서빙 운영에 최적화돼 있다(K8s). 목적에 따라 구조·네트워크·스토리지·스케줄링 방식이 달라지기 때문에, 클러스터는 “큰 컴퓨터”인 동시에 “특정 목적을 위해 조직된 분산 시스템”이라고 이해하면 된답니다.
다시 다시 말하지만
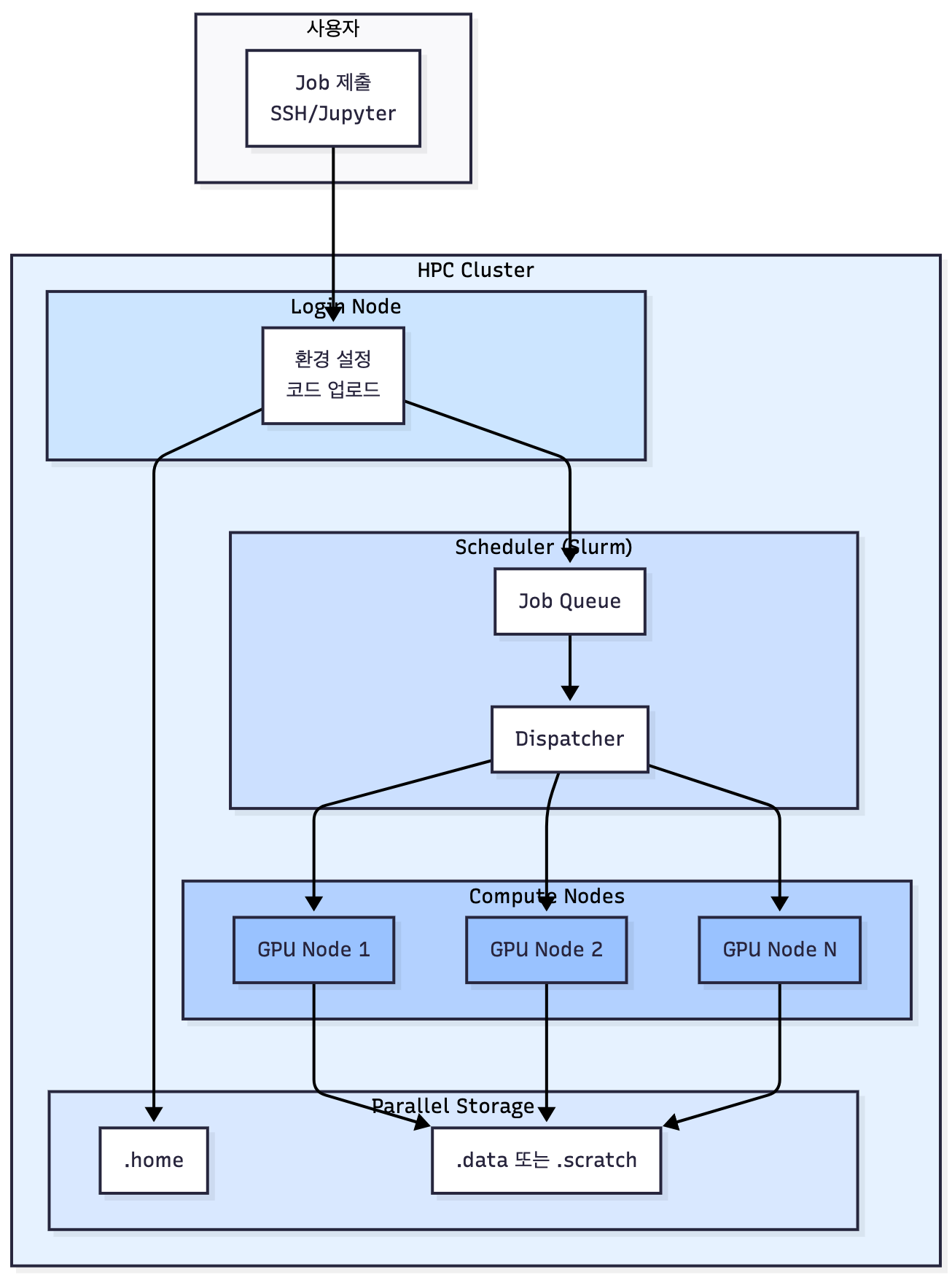
Aurora나 Ariel은 대강 이런 구조인 것!
그리고 MLOps에서 자주 쓰는 구조 중에 하나인데 이것도 알아두면 좋지 않을까?요~
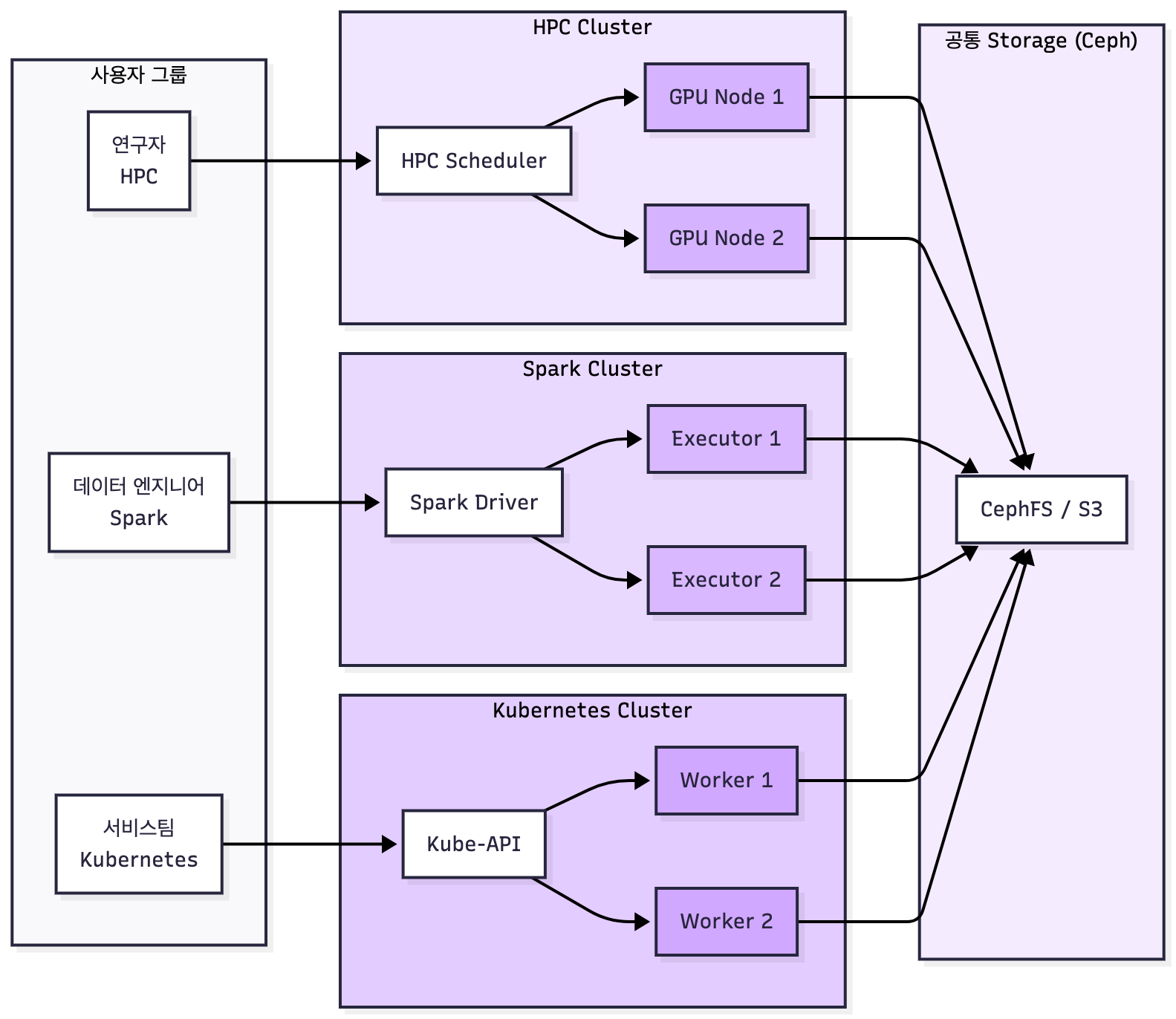
Ceph 더 말하고 싶은데 지겨워할 것 같아서....
Ceph
잘 정리된 티스토리 공유합니다.
여기는 뛰어넘으셔도 됩니다
일단 클러스터는 항상 “유형(Type)”—“구현체(Instance)”—“스케줄링”—“스토리지” 네 가지 관점으로 나누어 이해해야 한다는 것입니다.
| 항목 | 분류기준 | Aurora/Ariel |
|---|---|---|
| 유형(Type) | 아키텍처적 목적 | HPC Cluster |
| 구현체(Instance) | 특정 설치 구성 | aurora-g1/g2/g3, ariel-g1… |
| 자원 스펙 | GPU/CPU/RAM/스토리지 | 서버마다 상이 |
| 스케줄링 | Job Scheduler 기반 | Slurm 기반, 동일 |
| 스토리지 | 분산 파일 시스템 구조 | Ceph/Lustre/NFS 중 구현에 따라 상이 |
우리의 Auroa/Ariel기준으로 오른쪽에 설명했구요.
유형 TYPE
1) HPC Cluster (High Performance Computing)
대규모 병렬 연산·MPI·대규모 분산 학습
2) HTC Cluster (High Throughput Computing)
수백만 개의 작은 job 처리, Condor/Ray 기반 워크로드
3) Big Data Cluster (Data-Parallel Cluster)
Hadoop/Spark 기반 파일 병렬 처리
4) Storage Cluster (Distributed Storage Cluster)
Ceph, Lustre, HDFS 같은 스토리지 전용 분산 시스템
5) Kubernetes Cluster (Cloud Native Cluster)
컨테이너 기반 MLOps·DevOps·Inference/Service 운영
6) Hybrid / Multi-Cluster Architecture
HPC + Spark + K8s + Storage 조합(현대 AI 엔지니어링 표준)
실제 운영 환경에서는 아래와 같은 다양한 유형의 클러스터가 존재합니다.
각각이 좀 궁금하다면
HPC Cluster (High Performance Computing)
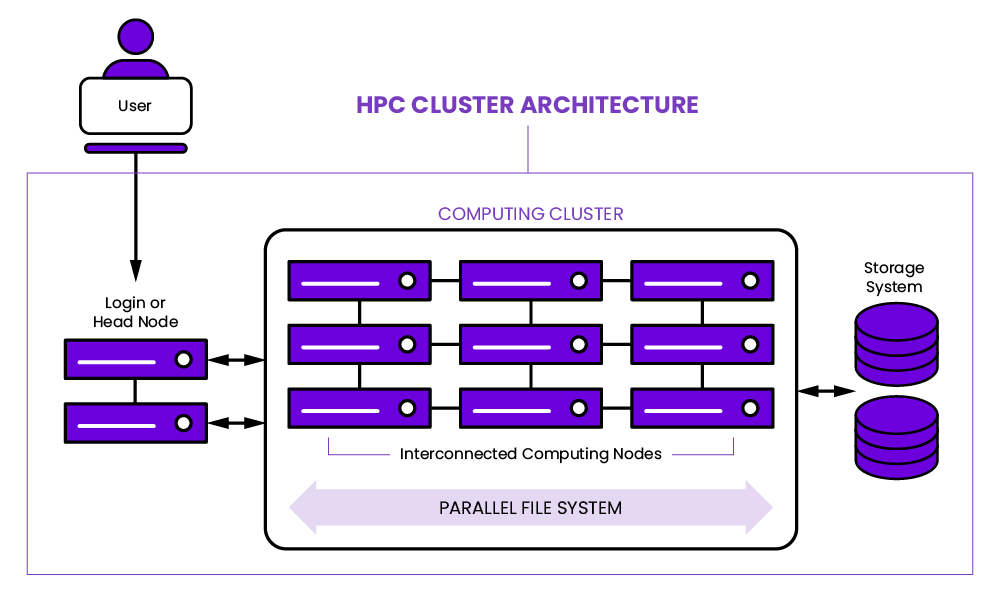
대규모 수치해석, 과학 계산, 딥러닝 학습을 위한 전통적 형태의 배치 기반 클러스터입니다.
- 예: Slurm 기반 GPU 노드, 슈퍼컴퓨터 센터
HPC 클러스터는 대규모 연산을 빠르게 처리하기 위해 설계된 배치 기반 환경이다. 슬럼(Slurm)·PBS 같은 스케줄러가 작업을 통제하며, 하나의 job이 수시간~수일 동안 GPU/CPU 수십~수백 개를 독점하는 구조를 전제로 한다. 노드 간 네트워크는 InfiniBand 등 고대역폭·저지연 인터커넥트를 사용해 MPI 기반 수치해석, 대규모 딥러닝과 같은 노드 간 파라미터 통신량이 많은 작업을 최적화한다. HPC의 강점은 계산 성능과 안정성이다. 반면, 서비스 운영에는 맞지 않으며 컨테이너 생태계와의 통합이 부족한 경우가 많다. 연구실·국가 슈퍼컴퓨터에서 주로 사용하는 이유도 “인터랙티브성”이 아니라 “정해진 시간 동안 최대 성능을 뽑아내는 구조”이기 때문이다.
HTC Cluster (High Throughput Computing)
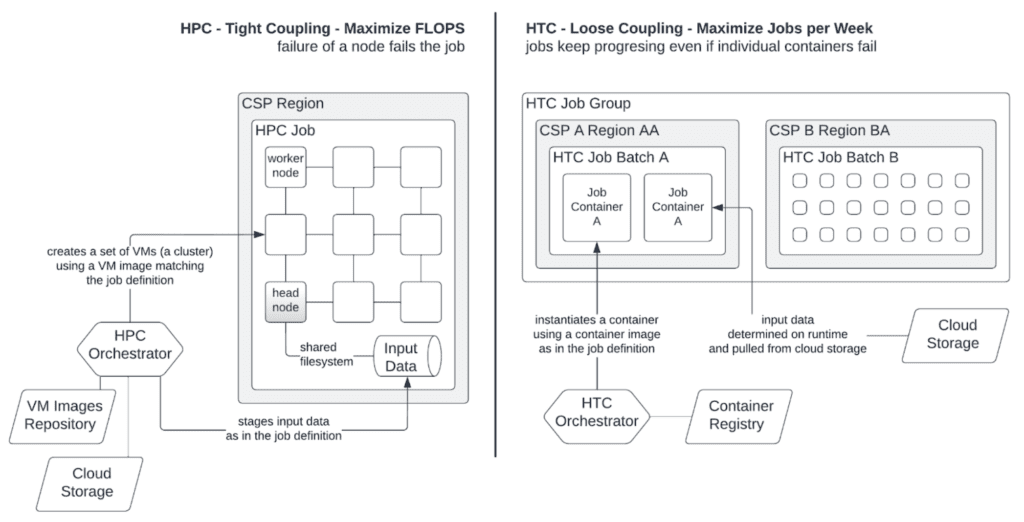
작업 하나가 크지 않지만 수천~수만 개의 작은 작업을 처리해야 할 때 사용합니다.
- 예: 단백질 스크리닝, 로그 분석, 수백만 건의 짧은 inference job
HTC 클러스터는 한 번의 연산은 작지만, 수만~수백만 개의 job을 순차·병렬로 계속 처리해야 하는 워크로드에 최적화되어 있다. 대표적으로 단백질 스크리닝, 로그 이벤트 분석, 대량 웹스케일 inference처럼 “작은 작업을 끊임없이 흘려보내는 구조”이다. 이 때문에 스케줄러는 throughput 기반으로 설계되며, 작업 하나가 길게 리소스를 독점하는 것을 막고 큐 대기 시간을 최소화하는 전략을 쓴다. HPC와 달리 고성능 네트워크가 필수는 아니지만, 잡 디스패치 속도(Job dispatch rate) 와 컨테이너 경량 실행이 중요하다. 많은 기관이 HTCondor, Ray, Airflow+K8s 조합을 HTC 용도로 사용하며, 대규모 MLOps 파이프라인의 “일괄 inference farm”으로도 쓰인다.
Big Data Cluster
Hadoop/Spark 기반의 데이터 병렬처리 클러스터입니다.
- 초대용량 데이터 파이프라인, ETL, 대규모 통계 처리
빅데이터 클러스터는 Hadoop·Spark 같은 데이터 병렬 처리 프레임워크를 안정적으로 실행하기 위한 전용 구조이다. 계산보다는 저장된 파일을 노드 전체로 확산시키고, 이를 병렬 map/reduce 형태로 처리하는 것이 중심이므로 HDFS·S3와의 데이터 지역성(Locality)이 성능을 좌우한다. Spark는 메모리 기반 분산 계산을 지원하지만, GPU를 사용하는 HPC나 딥러닝 환경과는 목적이 전혀 다르다. 빅데이터 클러스터의 강점은 수백 TB~수 PB 단위 데이터를 “실시간은 아니지만 빠르게” 분석하는 능력이며, ETL·로그 분석·Feature Store 구축 등 AI 파이프라인의 전처리/후처리 영역을 담당한다. 최근 기업들은 Spark + Kubernetes 구조로 이동하며 관리 비용을 낮추는 추세다.
Storage Cluster
스토리지 클러스터
종류디지게많음
파일 및 객체 스토리지를 분산 형태로 제공하는 전용 클러스터입니다.
- Ceph, Lustre, GlusterFS 등이 대표적
- HPC의
/data영역이 이런 스토리지 클러스터 위에서 동작하는 경우가 많습니다.
※ Ceph는 확장성과 범용성이 좋지만, Lustre는 HPC용으로 더 빠릅니다.
- Aurora/Ariel 같은 환경은 Lustre 또는 NFS 계열 스토리지를 사용하는 경우가 많습니다.
스토리지 클러스터는 계산이 아니라 데이터 저장과 I/O 처리에 최적화된 독립적인 분산 파일 시스템이다. HPC에서 사용하는 /data, /scratch가 대부분 이러한 시스템 위에서 돌아간다. Lustre는 초고성능 POSIX 파일시스템을 제공해 HPC에 적합하고, Ceph는 객체·블록·파일을 모두 제공해 범용성과 확장성이 뛰어나다. 스토리지 클러스터를 따로 두는 이유는 단순 저장 때문이 아니라, 노드가 수십~수백 대 이상인 클러스터에서 파일 일관성, 확장성, 결함 허용성(fault tolerance)을 확보하기 위함이다. 또한 GPU 학습에서도 대규모 이미지/비디오 셔플 시 I/O 병목이 전체 학습 속도를 결정하므로 스토리지 클러스터 설계가 AI 학습 성능과 직결된다.
Kubernetes Cluster (Cloud Native Cluster)
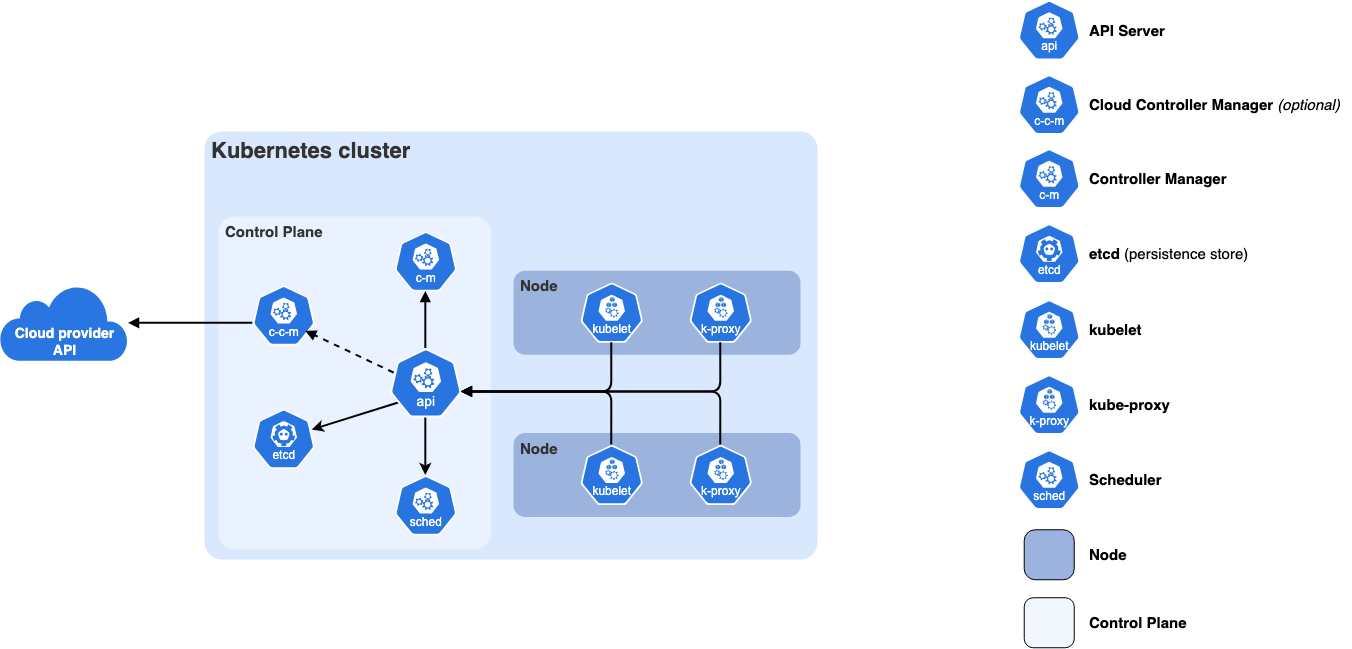
컨테이너 기반 AI·웹서비스·배포 자동화를 위한 클러스터입니다.
- GPU Operator를 설치하면 딥러닝 학습에도 활용 가능
- 최근 많은 AI팀이 HPC 대신 K8s 기반으로 전환 중
Kubernetes 클러스터는 전통적 HPC와 달리 컨테이너 기반의 유연성과 자동화를 중심으로 한다. GPU Operator·NVIDIA Device Plugin 등을 설치하면 딥러닝 학습 노드로도 활용할 수 있고, Inference 서비스·웹서비스·데이터 파이프라인 등 개발부터 운영까지 하나의 플랫폼에서 통합 관리할 수 있다. 또한 Auto-scaling, Canary rollout, 서비스 메쉬, 모니터링 등 배포 자동화 기능이 강력해 “AI 연구 + AI 운영(Serving)”을 같이 하는 팀이 빠르게 도입하고 있다. 다만 노드 간 HPC 수준의 통신 최적화를 보장하지 않기 때문에 대규모 분산 학습에는 한계가 있으며, 대신 MLOps/DevOps 환경에 매우 적합하다.
Hybrid Cluster
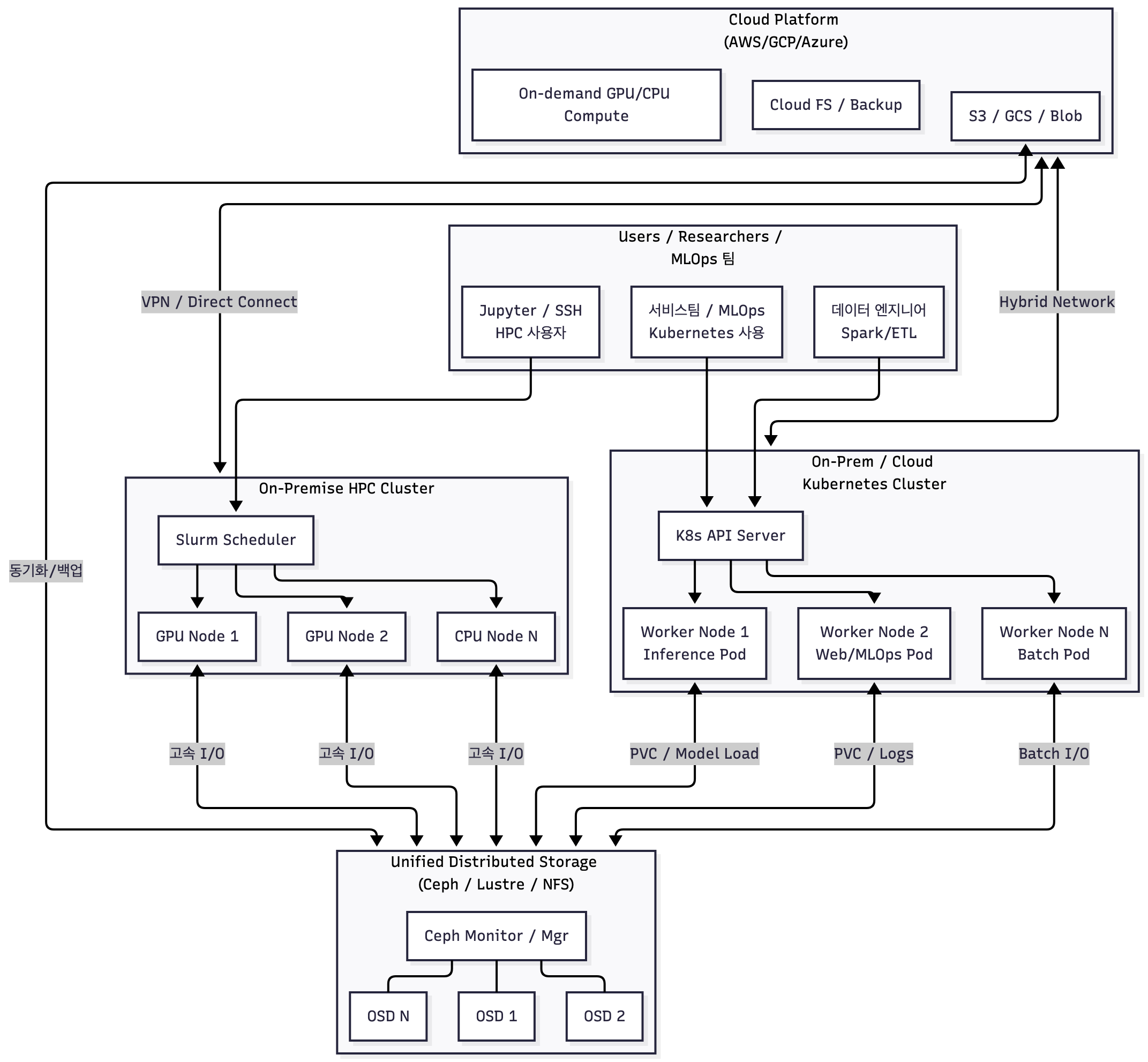
핏한 이미지가 없어서 GPT로 만들었어용
HPC + Cloud + K8s + Storage를 결합한 복합 구조입니다.
- 연구 기관에서 GPU 자원을 내부 HPC로 관리하고
- 생산 서비스는 Kubernetes에서 운영하는 형태가 대표적
Running Cloud-native Workloads on HPC with High-Performance Kubernetes
하이브리드 클러스터는 HPC·Kubernetes·Cloud·Storage를 결합한 형태로, 많은 연구기관·기업들이 실제로 운영하는 구조다. 예를 들어 GPU 연구는 온프레미스 HPC에서 진행하되, 프로토타입 웹서비스는 K8s에서 운영하고, 대규모 데이터는 클라우드 스토리지와 연결하는 방식이다. 이렇게 하면 연구 단계–개발 단계–운영 단계 간 리소스를 단일화할 수 있어 파이프라인 전환 비용이 크게 줄어든다. 또한 클라우드의 탄력성과 내부 HPC의 비용효율을 동시에 얻을 수 있다. 단점은 네트워크·보안·IAM 구조 설계가 복잡해지고, 팀 간 운영 책임 분리가 필요한 점이다. 성숙한 조직일수록 하이브리드 구조로 진화하는 경향이 있다.
Aurora와 Ariel
Aurora와 Ariel은 모두 학교에서 제공하는 고성능 연산(HPC) 서버이지만, 용도와 구성 측면에서 차이가 있습니다. Aurora는 주로 교육·연구 실습을 위한 학부 중심의 HPC 환경으로, 로그인 노드에서 SSH 접속 후 Slurm을 통해 GPU 노드(aurora-g1, g2, g3 등)를 예약해 사용하는 구조입니다. 사용자가 직접 /data/{your_id} 경로에 코드를 올리고, GPU 노드에 접속하여 가상환경을 구성한 뒤 배치 작업을 수행하는 방식이 대표적입니다. Ariel은 Aurora와 별도로 운영되는 연구 중심 HPC 환경으로, GPU 세대나 큐 정책, 스토리지 구성 등이 Aurora와 다를 수 있습니다. 각 시스템의 실제 구성은 df -h, sinfo, nvidia-smi 명령으로 확인하는 것이 가장 정확합니다.
보통 계산 성능·저장구조·큐 정책 등이 Aurora와 다를 수 있습니다. 예를 들어 Ariel은 다른 GPU 세대(예: A100, L40S 등)를 포함하거나, /scratch·/local_datasets 같은 고속 임시 스토리지가 제공될 가능성이 있습니다. 또한 사용자 그룹, 사용 정책, 실험 목적(수업·프로젝트·연구)에 따라 큐 설정과 접근 권한이 Aurora와 다르게 관리될 수 있습니다. 요약하면 Aurora는 교육·실습 중심의 표준 HPC 환경, Ariel은 보다 고성능 또는 연구 운영 중심의 확장 HPC 환경으로 이해할 수 있으며, 실제 스펙과 경로 구조는 SSH 접속 후 df -h, sinfo, nvidia-smi 등을 통해 확인하는 것이 가장 정확합니다.
여기서부터 다시 보세요
아 이제 진짜 딴소리 안하고 돌아와서...
Aurora와 Ariel은 모두 학교에서 제공하는 고성능 연산 서버(HPC 클러스터)지만, 제공 대상 학과와 운영 목적이 구분되어 있습니다. Aurora는 컴퓨터공학과·소프트웨어융합학과 등 공학 계열 학생들에게 주로 제공되는 범용 GPU 연산 클러스터로, 다양한 분야의 실습·과제·연구를 위한 공용 서버 역할을 합니다. 반면 Ariel은 인공지능학과를 중심으로 제공되는 전용 클러스터로, 딥러닝·머신러닝 실험에 최적화된 GPU 자원이 집중된 환경이라는 점이 가장 큰 차이입니다. 실제로 공학 계열은 Aurora 접근 권한을 배정받는 경우가 많고, 인공지능학과는 Ariel 계정을 별도로 지급받는 것으로 알려져 있습니다. 두 시스템 모두 SSH·SFTP를 기반으로 사용 방식은 유사하지만, Aurora는 다양한 과목과 연구 주제를 수용하는 범용 교육용 클러스터, Ariel은 AI 실험·모델 학습을 위한 전용 연산 서버라는 차이가 있으며, 노드 구성·GPU 종류·사용 정책 역시 학과별 요구에 맞추어 다르게 운영되는 편입니다.
결론
깃허브 디렉토리 짤 때는 /data, /code, /logs 등 역할별 폴더를 명확히 구분해야 합니다.
이 구조를 그대로 HPC의 /data/{your_id} 하위에 반영하면, 학습 코드·데이터 관리가 깔끔해지고 Slurm job 실행 시 경로 충돌을 방지할 수 있습니다.
