Introduction to Deep Learning
What is a neural networks?
- Deep learning
신경망 학습을 일컫는 말이다. 집값을 예측하는 예제로 설명한다.
만약, 가격 price를 예측하는 데 4가지 x인 size, bedroom, address, school quality가 있다고 가정한다.
이 x값들을 신경망의 input으로 지정하고, y값인 가격을 예측하는 것이다. 아래 그림을 보면 unit이라는 동그라미가 있는데, 이건 unit이라고 부른다. unit은 4가지의 특성을 담고 있으며 자유롭게 선택 가능하다. (아마 어떤 기준으로 선택되는지는 알기 힘들 것이다. 복잡한 데이터에서도 좋은 결과를 보여주지만, inference를 제공하기 힘든 것이 딥러닝의 단점이기 때문이다.)
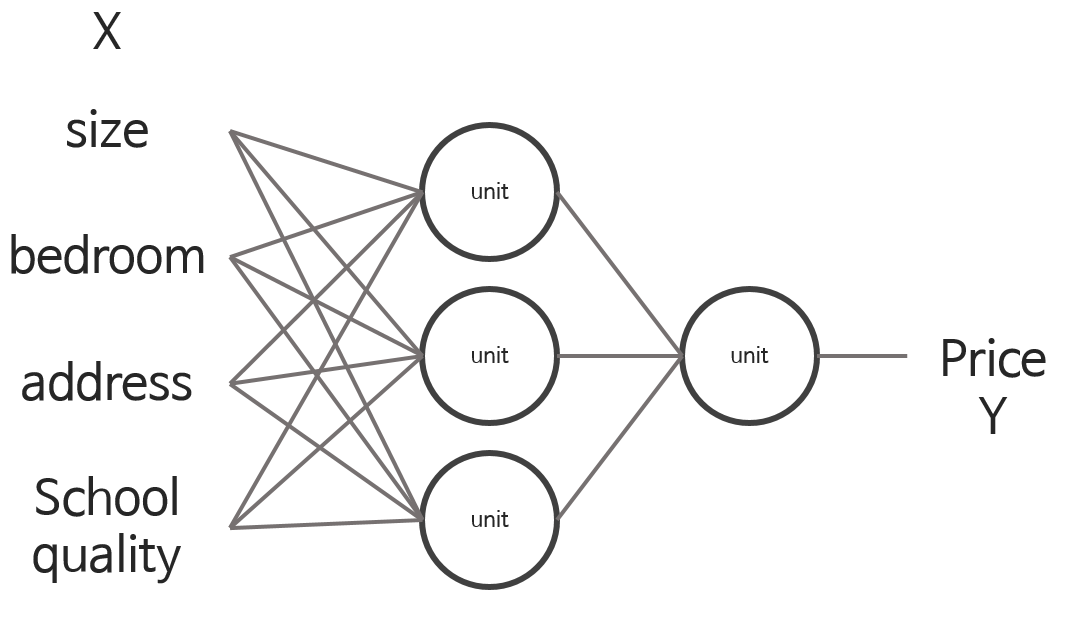
Supervised Learning with Neural Networks
-
예시
1) Online Advertising
고객 정보(input)를 바탕으로 광고 클릭 여부(output)
2) Photo tagging
이미지(input)를 바탕으로 약 1000가지의 라벨링 가능(output)
3) Machine translation
영어(input)를 중국어(output)로 번역 -
sequence data
시퀀스 데이터는 시간적인 요소가 있음. 일차원적인 time series 또는 시간적인 sequence에 의해 자연스럽게 표현된다.
언어 또한 sequence 데이터를 통해 자연스럽게 표현된다. 영어, 중국어와 같은 경우 단어들은 하나씩 나열되는 특성이 있기 때문이다.
시퀀스 데이터는 RNN(Recurrent Neural Network)을 가장 많이 사용한다. RNN은 시간적인 요소를 담고 있는 일차원적인 데이터를 다루는 데에 좋다.
Why is Deep Learning taking off?
-
딥러닝이 뜨는 이유는?
딥러닝 네트워크 개념 자체는 수십년동안 존재해왔다고 한다.
데이터의 양이 방대해짐에 따라서 딥러닝의 performance가 향상되고 있다. 데이터가 적을 때는 SVM, Logistic Regression의 performance는 딥러닝의 performance와 차이가 없다. 하지만 데이터의 양이 점점 커질수록 그 차이는 매우 크다. 이러한 이유로 딥러닝이 뜨는 것이다.
하지만 데이터의 수가 그렇게 크지 않다면, 기존 머신러닝 방법이 더욱 효과적일 것임. -
large-sized Deep learning의 조건
1) 큰 신경망을 학습할 환경 구축
2) 데이터가 아주 많아야함
신경망의 발전이 빠르게 이루어질 수 있었던 것은 네트워크의 변화가 빠르게 이루어졌기 때문이다. sigmoid함수가 ReLu함수로 대체되었기 때문에 빠르게 발전할 수 있었다.
-
Sigmoid 함수
시그모이드 함수의 문제점은 머신러닝에 적용시키는 경우, 함수의 기울기가 거의 0에 가까운 값이 되므로 학습 속도가 매우 느려진다.
gradient descent(기울기 강하)를 도입하는 경우 기울기가 0이면 개체가 매우 느린 속도로 변하기 때문이다.
또, 함수의 기울기가 0이 되면 gradient vanising문제가 발생한다. 0을 곱하면 0이 되기 때문에 다음 layer로 전파되지 않아 학습이 되지 않는 큰 문제가 발생한다.
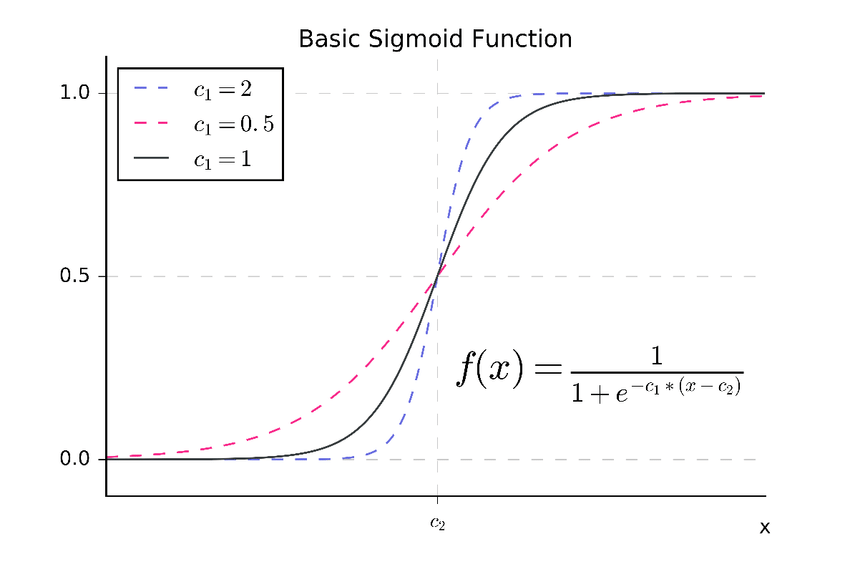
-
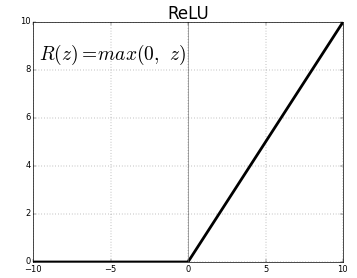
ReLu 함수
기울기는 모든 양수에 대해서 1이기 때문에 기울기가 0으로 줄어드는 확률이 감소된다.
1주차 마무리
총 5개의 짧은 동영상이었다. 7분, 8분, 10분, 2분, 1분으로 구성되었다. 1주차라서 가볍게 딥러닝이 왜 핫한지, 신경망이 어떤 것인지 설명을 한 것 같다. 영어라서 쉽게 알아들을 수 없어서 중간중간 많이 멈춰야했다. 그래도 한글 대본이 있어서 많은 도움을 받을 수 있었다.
마지막으로 연습문제 10문제를 풀고 1주차를 마무리하겠다.
