Shallow Neural Network
Neural Networks Overview
신경망은 sigmoid unit을 쌓아 합쳐서 구성할 수 있다.
Neural Networks Representation
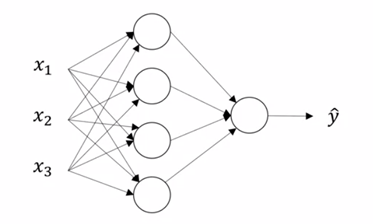
1) Input Layer
x1, x2, x3
2) Hidden Layer
동그라미 4개의 unit
3) Output Layer
동그라미 1개의 unit, y hat값을 생성하는 역할
4) Activation
입력층이 x값을 숨겨친 층으로 전달하고, 또다른 숨겨진 층으로 전달한다. 다음 층에서 숨겨진 층은 또다른 activation을 생성한다.
Computing a Neural Network's Output
Hidden Layer는 unit안에 2가지 절차로 이루어진다. 첫번째는 Z값을 구하고, 두번째는 Z의 시그모이드 함수로 activation을 산출한다. Hidden Layer를 각각 계산하는 것은 비효율적이니 벡터화해서 matrix로 계산을 할 수 있다.
Activation functions
- 활성함수 그래프
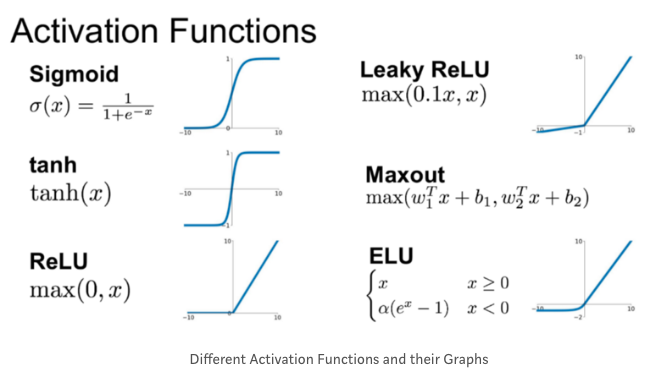
sigmoid와 tanh
신경망을 생성할 때, 1) 은닉층에서 어떤 활성함수를 사용할 것인가 2) 신경망의 출력 유닛들은 어떻게 할것인가 두 가지를 정할 수 있다.
tanh함수(hyperbolic tangent function)는 sigmoid함수보다 항상 더 좋은 성능을 발휘한다. 왜냐하면 값이 항상 +1에서 -1 사이에 위치하면서, 활성함수의 평균값이 hidden layer에서 계산되고, 이 값이 0에 가깝기 때문이다.
반면, 출력층일 때는 tanh함수가 성능이 떨어진다. y hat은 0과 1사이의 출력값을 가지기 때문이다.
이진분류인 경우 sigmoid 활성함수를 사용한다. 이런 경우에는 출력층에 sigmoid함수를 사용하게 된다.
sigmoid, tanh단점
Z가 매우 크거나 매우 작을 때, gradient의 값이 매우 작은 값이 된다는 단점이 있다. 이런 경우는 함수의 기울기가 거의 0이 된다. 그래서 gradient descent 알고리즘을 느리게 만든다.
ReLU 정리
공식은 a=max(0,z)이다. z가 양수이면 기울기는 1이고, 음수이면 기울기는 0이다. 따라서 z가 0일때, 기울기를 0 또는 1로 취급할 수 있다. 따라서 활성함수로 사용하기에 아주 적합하다. 어떤 것을 사용해야할지 잘 모른다면 ReLU를 추천한다. 학습 속도가 아주 빠를 것이다.
ReLU 단점
z가 음수일 때 미분값이 0이라는 것이다. 이를 보완하는 leaky ReLU가 있는데, 이것은 z가 음수일 때 약간의 기울기를 가져서 0의 값을 가지지 않는 함수이다.
Why do you need non-linear activation functions?
기존 선형 분류기라는 한계로 인해 XOR과 같은 non-linear한 문제를 해결할 수 없었다. 입력값에 대한 출력값이 linear하게 나오지 않았기 때문에 hidden layer에 activation function을 도입해서 선형분류기를 비선형 시스템으로 만들 수 있었다.
즉, Multiple Layer Perceptron은 활성 함수를 이용한 non-linear시스템을 여러개의 층으로 쌓는 개념이다.
Random Initialization
-
symmetry breaking 문제
신경망에서 weight를 임의로 초기화하는 것은 중요하다. 하지만 모든 weight를 0으로 변경하고 기울기 강하를 적용하면 작동하지 않는다. 모두 0으로 초기화를 한다면 hidden layer에 있는 모든 activation이 똑같은 함수를 산출하기 때문이다. -
symmetry breaking 문제 해결법
이에 대한 해결책은 parameter를 임의로 초기화하는 것이다. w1=np.random.randn으로 설정하면 gaussian random variable이 생성된다. 보통 weight를 초기화할 때 임의의 작은 값을 사용한다. 왜냐하면 tanh나 sigmoid 등 함수가 결과값 층에 있는 경우, weight가 너무 크면 z의 값이 매우 크거나 매우 작게 된다. 그러면 learning 속도를 늦추게 된다.
