먼저, 위 코드에서는 Vision Transformer 모델을 생성하기 위해 pytorch_lightning 라이브러리를 사용하고, 차원 조작을 위해 einops 라이브러리를 사용합니다.
그래서 먼저 라이브러리 설치를 해주고,
pip install pytorch_lightning einopsMNIST 데이터셋을 로드한 후 ViT 모델을 불러옵니다.
ViT를 구현하려면 아래와 같은 구조를 만들어야 하는데,
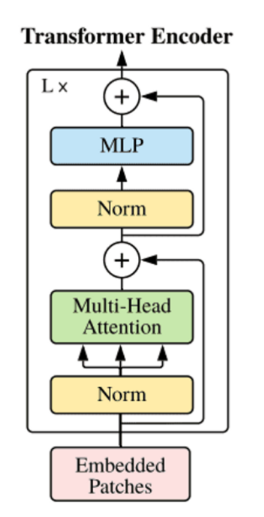
input인 Embedded Patches는 이미지를 패치 단위로 끊어 시퀀스 데이터로 만들어주는 것입니다.
input 이미지를 정해진 패치 사이즈로 쪼갠 후 CLS Token을 Concat하고, 각 패치에 Positional Embedding을 추가해 줍니다. Self-Attention 구현을 위해 이미지 Task를 1차원으로 Flatten합니다. Classification Token은 쪼갠 이미지 중 첫 번째에 삽입됩니다.
CLS Token과 Positional Embedding이 학습을 위한 파라미터이기 때문에 nn.Parameter를 사용합니다.
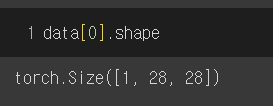
MNIST 데이터셋의 data shape를 [1, 28, 28]인데, 4*4 사이즈의 패치로 쪼개면 28*28/16 = 49이므로 [49, 16*1]개의 임베딩이 발생합니다.
그래서 임베딩 레이어를 만드는 클래스는 아래와 같이 작성할 수 있습니다.
class EmbeddingLayer(nn.Module):
def __init__(self,in_chan, img_size, patch_size,batch_size=128):
super().__init__()
self.num_patches = int(img_size / pow(patch_size, 2)) # 1*28*28 / 4^2 = 49
self.emb_size = in_chan * patch_size * patch_size # 1*4*4 = 16
self.project = nn.Conv2d(in_chan, self.emb_size, kernel_size= patch_size, stride=patch_size)
self.cls_token = nn.Parameter(torch.randn(1,1,self.emb_size))
self.positions = nn.Parameter(torch.randn(self.num_patches+ 1, self.emb_size)) # [50,16]
def forward(self, x):
x = self.project(x)
x = x.view(-1, 49, 16) # [batch_size, 49, 16]
repeat_cls = self.cls_token.repeat(x.size()[0],1,1) # [batch_size, 1 , 16]
x = torch.cat((repeat_cls, x), dim=1)
x += self.positions
return xMulti-head Attention은 파이토치 모듈을 사용해서 구현합니다.
class Multihead(nn.Module):
def __init__(self, emb_size, num_heads):
super().__init__()
self.multiheadattention = nn.MultiheadAttention(emb_size, num_heads, batch_first = True, dropout=0.2)
self.query = nn.Linear(emb_size, emb_size)
self.key = nn.Linear(emb_size, emb_size)
self.value = nn.Linear(emb_size, emb_size)
def forward(self, x):
query = self.query(x)
key = self.key(x)
value = self.value(x)
attn_output, attention = self.multiheadattention(query, key, value)
return attn_output, attentionNorm의 경우 Layer Normalization을 사용합니다. Batch Norm은 각 Feature를 Normalize한다면, Layer Norm은 배치마다 시행합니다.
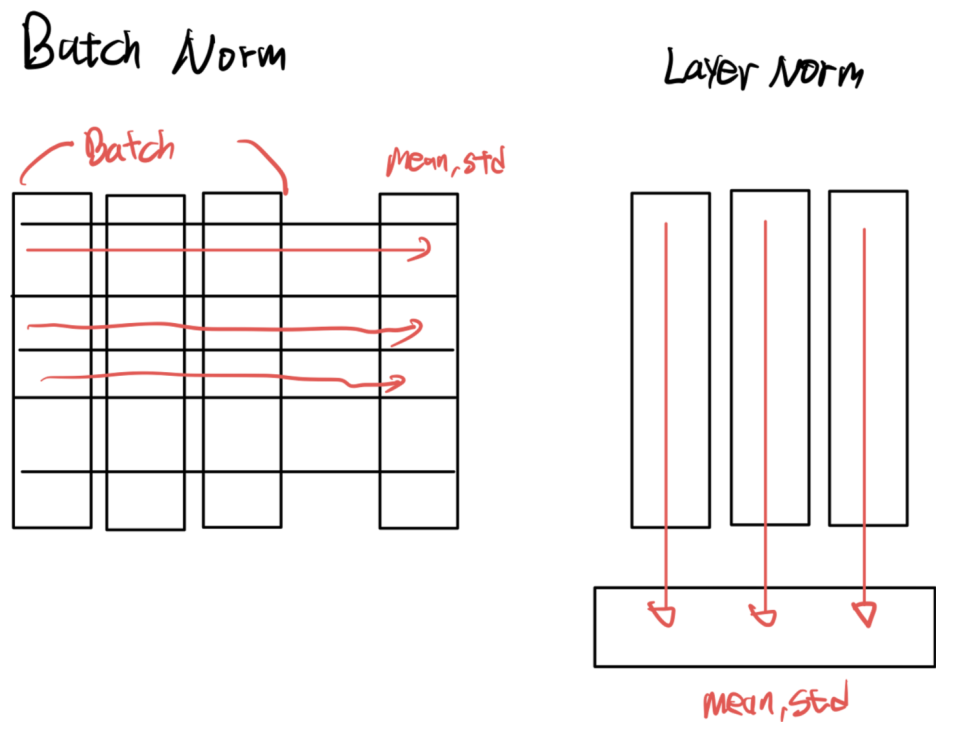
즉, 동일 배치 시점의 시퀀스를 정규화하는 것입니다. 시계열 데이터는 시점마다 다른 통계치가 존재하기 때문에 첫 번째 시퀀스들끼리, 두 번째 시퀀스들끼리 정규화하는 것이 효과적입니다.
class VIT(nn.Module):
def __init__(self,emb_size = 16):
super().__init__()
self.embedding_layer = EmbeddingLayer(1, 28*28, 4)
self.Multihead = Multihead(emb_size, 8)
self.FFB = FeedForwardBlock(emb_size)
self.norm = nn.LayerNorm(emb_size)
def forward(self, x):
x = self.embedding_layer(x)
norm_x = self.norm(x)
multihead_output, attention = self.Multihead(norm_x)
#residual Function
output = multihead_output + x
norm_output = self.norm(output)
FFB = self.FFB(norm_output)
final_out = FFB + output
return final_out, attention다음에는 MLP를 만들기 위한 FeedForwardBlock을 생성합니다.
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size, expansion = 4, drop_p = 0.2):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size)
)여기에서 사용된 활성화 함수는 GELU(Gaussian Error Linear Unit)인데, 최근 BERT, GPT 등 자연어 처리 모델에도 사용된 함수입니다. ReLU와 비슷하지만 ReLU가 음수를 모두 0으로 처리하는 것과 달리 음수를 작은 값으로 생성해서 ReLU보다 더 좋은 성능을 보이는 경우가 많습니다.
이후에는 nn.ModuleList를 활용하여 모델을 여러 번 쌓습니다.
class TransformerEncoder(nn.Module):
def __init__(self, n_layers: 5, ):
super().__init__()
self.layers = nn.ModuleList([VIT() for _ in range(n_layers)])
def forward(self, x):
for layer in self.layers:
final_out, attention = layer(x)
return final_out최종 MLP는 pytorch lightning에서 Lightning Module을 상속해서 생성합니다.
class VIT_Encoder(pl.LightningModule):
def __init__(self):
super().__init__()
self.loss = []
self.Encoder = nn.Sequential(
TransformerEncoder(n_layers = 5),
#Reduce('b n e -> b e', reduction='mean')
)
self.final_layer = nn.Linear(16, 10)
self.val_loss = []
self.acc = []
self.test_acc =[]
def forward(self, x):
x = self.Encoder(x)
cls_token_final = x[:,0]
#(cls_token_final.shape)
cls_token_final = self.final_layer(cls_token_final)
return cls_token_final
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = nn.CrossEntropyLoss()(logits,y)
self.loss.append(loss.item())
return loss
def on_train_epoch_end(self):
mean_loss = sum(self.loss) / 430
print(f'traing_loss :{mean_loss}')
self.loss = []
self.acc = []
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = nn.CrossEntropyLoss()(logits,y)
self.val_loss.append(loss.item())
acc = ac(logits, y)
self.acc.append(acc)
return loss
def on_validation_epoch_end(self):
mean_loss = sum(self.val_loss) / 40
mean_acc = sum(self.acc)/ 40
print(f'val loss :{mean_loss}, val_acc : {mean_acc}')
self.val_loss = []
self.acc = []
self.log("val_loss", mean_loss)
def test_dataloader(self):
return test_dataloader
def test_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
acc = ac(logits, y)
self.test_acc.append(acc)
def on_test_epoch_end(self):
mean_acc = sum(self.test_acc)/ 79
print(mean_acc)
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=1e-3) train 후 결과를 확인해 보면
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
early_stop_callback = EarlyStopping(monitor='val_loss', mode ='min', patience=5)
model = VIT_Encoder()
trainer = pl.Trainer(max_epochs=50, devices=1, accelerator="gpu", callbacks=[early_stop_callback])
trainer.fit(model, train_dataloaders = train_dataloader, val_dataloaders = val_dataloader)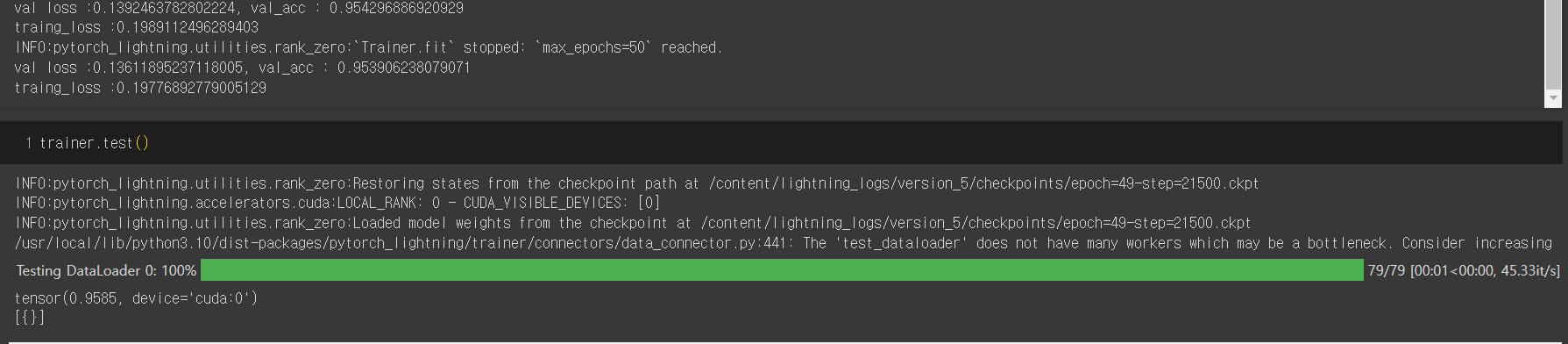
Vision Transformer는 데이터가 많이 있어야 학습 효과가 좋다고 하는데, MNIST 같은 간단한 데이터셋에서는 50회 학습으로 95%가 넘는 accuracy를 보입니다.
다음엔 직접 구축한 YOLO v5 학습용 데이터셋을 torch에서 가져와서 해볼 예정입니다!
