
전에 시연 중인 로봇팔이 물건을 잘 못 집고 시늉만 하고 있어서, 카메라가 없나? 했는데, 실제로 해 보니 카메라로 객체는 잘 인식했더라도 좌표 계산을 잘못해서 집는 동작을 못하는 경우가 많았다.
이동할 좌표는 어떻게 구해오는가?
- Aruco Marker 위치에서 로봇의 물리 좌표 구하기
- Aruco Marker 위치에서 OpenCV의 픽셀 좌표 구하기
- Aruco Marker 위에 박스를 두고 YOLO에서 인식한 좌표 구하기
- YOLO 좌표로 물리 좌표 구하기
1. dobot api에서 GetPose 함수로 좌표 가져오기
로봇의 Pose는 x, y, z, yaw를 가지고 있다.
YOLO로 인식된 객체의 높이를 구할 수 없고, 어느 위치로 이동할 때 yaw가 중요하지는 않기 때문에 이 좌표에서는 x, y 값만 사용
2. Aruco Marker의 픽셀 좌표 구하기
pip install opencv-contrib-python==4.6.0.66 opencv-python==4.8.1.78Aruco Marker를 인식하려면 opencv 외에 opencv-contrib-python도 필요하다.
cv2.aruco.detectMarkers(gray, cv2.aruco_dict, parameters=parameters) 함수의 리턴값으로 corners, ids, rejected_img_points를 얻을 수 있다. (공식문서 참고)
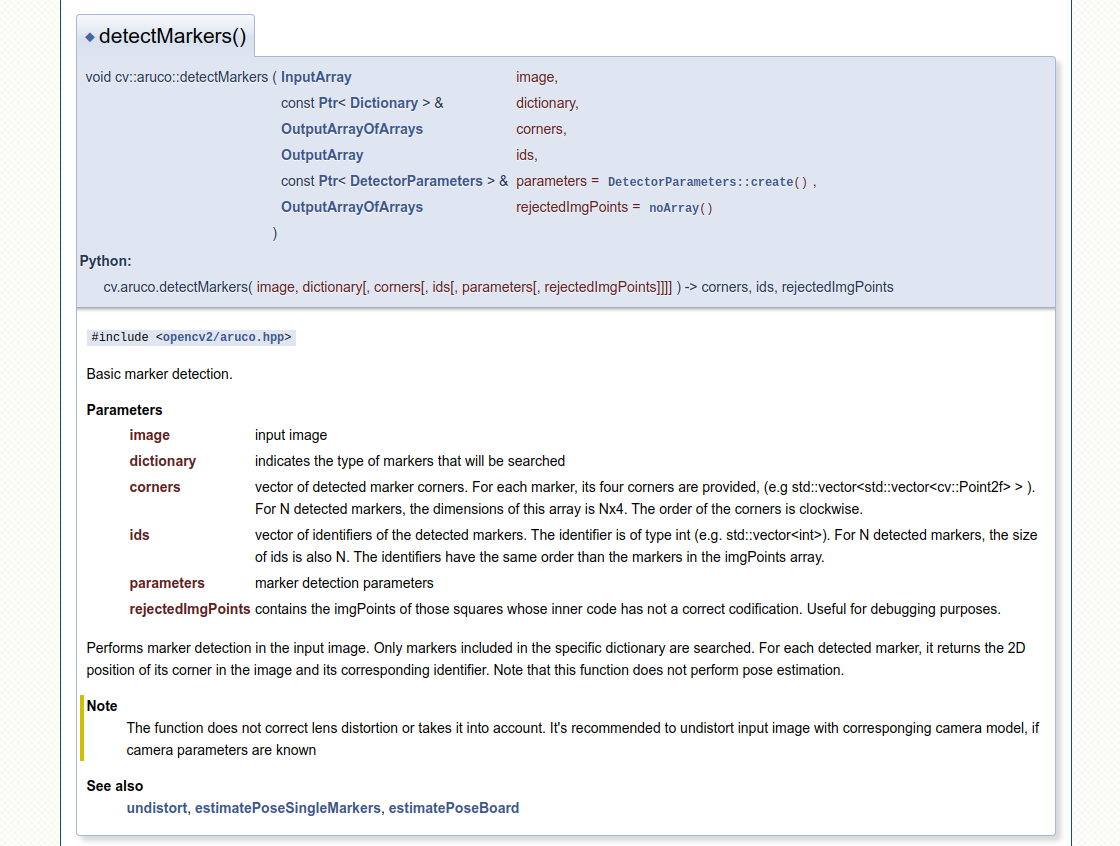
중심 좌표를 얻기 위해서는 corners를 활용한다.
vector of detected marker corners. For each marker, its four corners are provided, (e.g std::vector<std::vector<cv::Point2f> > ). For N detected markers, the dimensions of this array is Nx4. The order of the corners is clockwise.
마커의 4개 꼭짓점 좌표를 제공받았기 때문.
for문으로 모든 마커에서 아래와 같은 코드를 실행하면
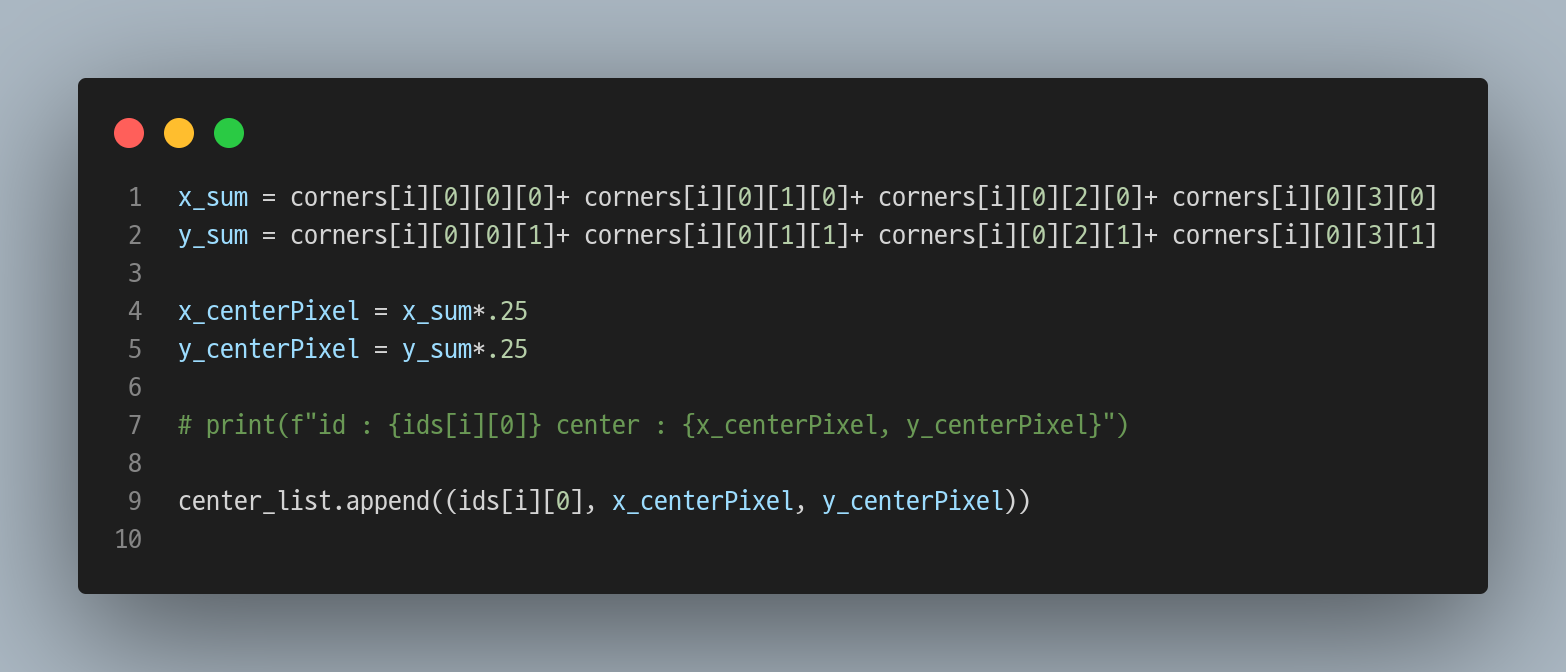
x좌표 4개를 더한 값을 1/4로 나눠서 중심 x 좌표를 구하고,
y좌표 4개를 더한 값을 1/4로 나눠서 중심 y 좌표를 구한다.
(참고: https://stackoverflow.com/questions/53460495/finding-the-center-of-an-aruco-marker)
3. YOLO에서 인식한 좌표 구하기
이 과제에서는 색상과 모양이 서로 다른 세 개의 블록을 인식하기로 했다. 색상이 같은 블록이 없으니 객체인식 난이도는 매우 낮고, YOLO v5의 n 모델을 사용해서 학습하기로 했다.
테스트를 하다 보니 중간중간 블록을 인식하지 못하거나 바닥을 블록으로 인식하는 경우가 있어 데이터 보정 후 재학습을 하긴 했지만, 학습에 사용한 이미지도 200개가 안 됐고 (augmentation 전 실제 촬영 이미지 82장) 소요된 시간이 총 1시간 미만이었다.
인식한 객체의 좌표는 어떻게 가져오냐면?
YOLO v5 라이브러리의 detect.py의 run 함수를 살짝만 수정해서 썼다.
- 수정 전
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
...
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = names[c] if hide_conf else f'{names[c]}'
confidence = float(conf)
confidence_str = f'{confidence:.2f}'
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()- 수정 후
# device = select_device(device)
model = DetectMultiBackend(weights, data=data)
.
.
.
xywh_list = []
label_list = []
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = names[c] if hide_conf else f'{names[c]}'
confidence = float(conf)
confidence_str = f'{confidence:.2f}'
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
xywh_list.append(xywh)
label_list.append(label)
.
.
.
return label_list, xywh_list1) select_device를 할 때 GPU를 찾고 세팅하는 데 시간이 많이 걸려서 사용하는 모델과 이미지만 주고 나머지는 기본값으로 사용한다.
학습할 때 말고는 GPU를 사용하지 않아도 되는데, DetectMultiBackend를 들어가 보면 기본값으로 device를 cpu로 세팅해 주고 있다.
2) label과 xywh 값을 가져온다.
xywh에서 x와 y값은 인식된 객체의 중심 좌표를 전체 이미지 내에서 상대좌표로 나타낸 값이다. (참고: You Only Look Once: Unified, Real-Time Object Detection)

OpenCV에서 카메라를 시작했을 때 설정했던 이미지 크기(width*height)에 맞춰서 곱해주면 Aruco Marker에서 구한 픽셀 좌표와 거의 일치할 것이다.
4. YOLO 좌표로 물리 좌표 구하기
세 개의 Aruco Marker의 위치는 다음과 같았다.
# 물리 좌표 - 픽셀 좌표 - YOLO 좌표
[248.375141, 108.137960] (562.5, 230.25) (0.89453125, 0.48229166865348)
[331.901894, 0.487331] (328.5, 409.75) (0.516406238079071, 0.8604166507720947)
[246.659730, -108.504260] (99.0, 215.5) (0.15234375, 0.4468750059604645)위 영상에서 카메라와 로봇팔의 위치가 서로 마주 보고 있기 때문에 카메라의 x축은 로봇의 y축, 카메라의 y축은 로봇의 x축 값과 상관관계를 가지게 되었다.
그런가 하면 픽셀 좌표는 항상 상수인데 로봇팔의 좌표는 로봇의 위치를 영점으로 보기 때문에 음수인 곳이 생기는데, 그래서 좌표를 변환할 때 각 위치의 수치로 바로 계산하지 않고 위치간의 거리를 계산해서 그 거리의 비율만큼을 곱해주면 물리 좌표를 구할 수 있다.
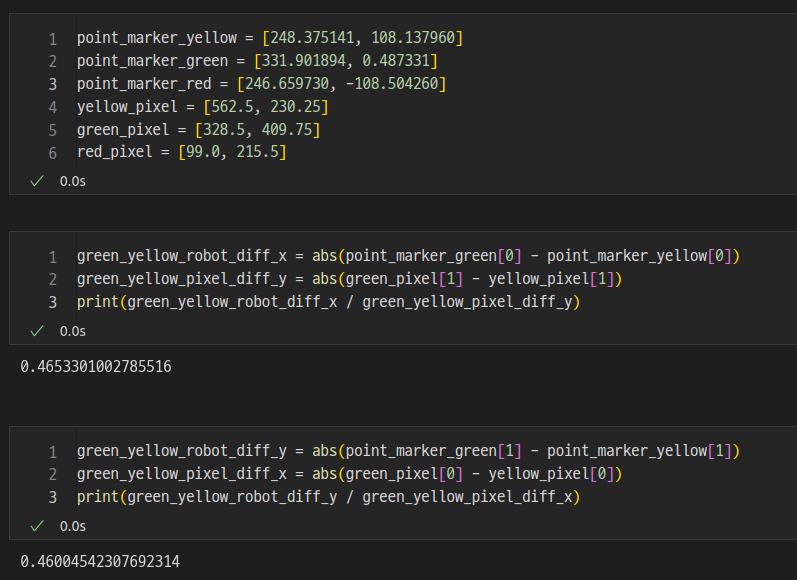
0.46 정도의 값을 곱하면 된다.
그리고 OpenCV에서 카메라의 왼쪽 위가 (0, 0) 픽셀인데, 이 위치의 로봇 물리 좌표는 당연히 (0, 0)이 아니다. 같은 위치의 로봇 물리 좌표를 구해서 더해주면 된다.
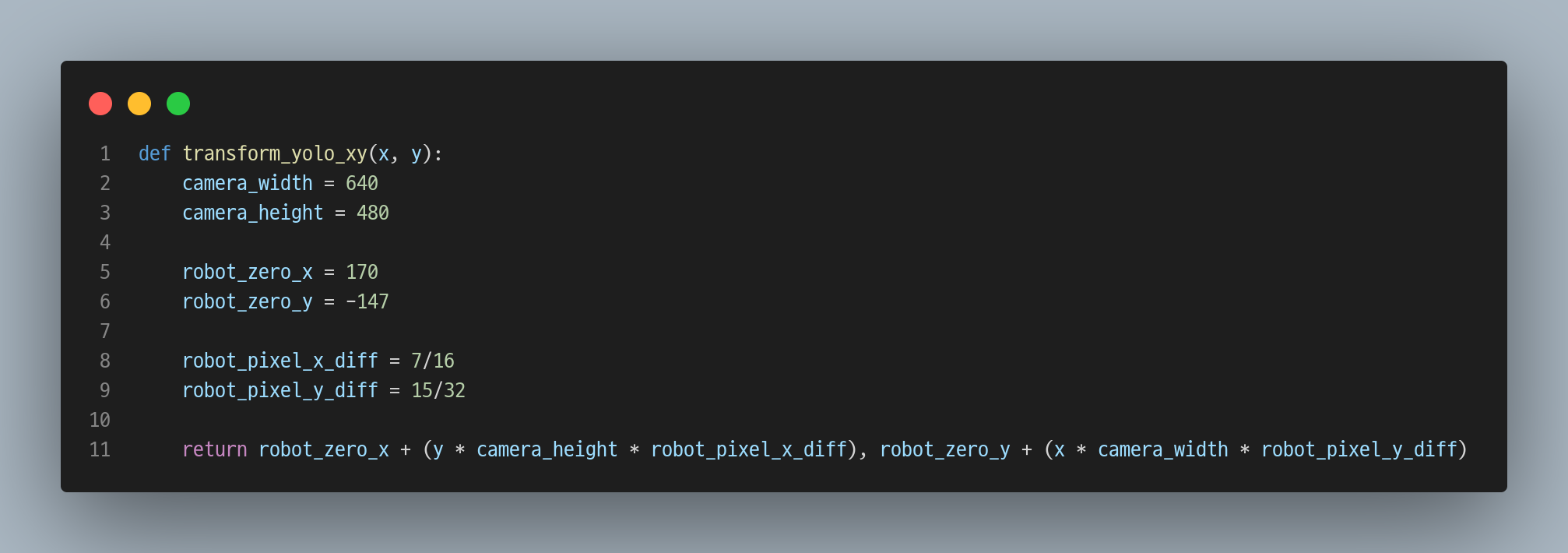
그래서 만들어진 함수는 위와 같다. (여러 명의 도움을 받아 작성된 코드🥹)
그런데 자꾸 빗나가서 확인해 보면
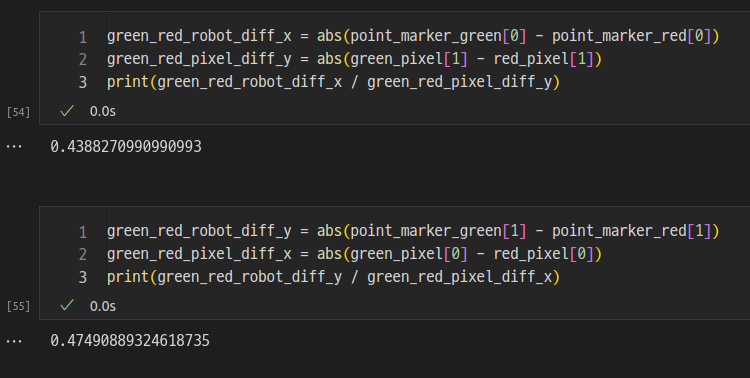
카메라 캘리브레이션이 되어 있지 않아서 카메라 중심에서 먼 곳은 왜곡되어 보이기 때문에 거리 비율이 제각각이 된다.
캘리브레이션까지 하면 어느 좌표에 있어도 이동에 무리가 없을 것이다.
그래서 캘리브레이션은 어떻게 하는가..?
https://docs.opencv.org/4.x/dc/dbb/tutorial_py_calibration.html 를 참고해서 해 보도록 하자.

가방이 참 귀엽네요~