[Capstone #6] VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
Capstone
Paper : https://arxiv.org/abs/2307.16430
Youtube : https://www.youtube.com/watch?v=Abov0q9T4jU
SK TECH SUMMIT 2023에서 언급된 내용은 [Capstone #8] SK TECH SUMMIT 2023: VITS2 에서 확인하실 수 있습니다.
Abstract
VITS2는 Single-stage TTS 모델의 품질과 효율성을 향상시켰다. 이 모델은 이전의 작업에 비해 개선된 구조와 훈련 메커니즘을 제안하고, 제안된 방법이 자연스러움, 다중 화자 모델에서 음성 특성의 유사성, 훈련 및 추론의 효율성을 향상시키는 데 효과적임을 보인다. 또한, 이전 작업에서의 음운 변환에 대한 강한 의존성을 본 논문의 방법으로 크게 줄일 수 있음을 보인다. 이는 end-to-end single-stage 접근을 가능하게 한다.
1. Introduction
최근 딥러닝 기반의 텍스트 음성 변환 기술은 상당한 발전을 이루었다. 딥러닝 기반의 텍스트 음성 변환은 입력 텍스트로부터 해당하는 원시 파형을 생성하는 방법으로, 텍스트 음성 변환 작업을 어렵게 만드는 몇 가지 특징을 가지고 있다.
-
텍스트 음성 변환 작업은 불연속적인 특징인 텍스트를 연속적인 파형으로 변환하는 작업이다. 고품질 음성 오디오를 합성하기 위해서는 입력과 출력의 time step 차이가 수백 배에 달하며, 이들 간의 정렬이 매우 정확해야 한다.
-
입력된 텍스트에 존재하지 않는 운율적 특성과 화자적 특성이 자연스럽게 표현되어야 하며, 텍스트 입력이 다양하게 발화될 수 있는 일대다 문제다.
-
사람들이 오디오를 들을 때 개별 구성 요소에 주의를 기울인다. 따라서 수십만 개의 신호로 구성된 전체 오디오 중 일부라도 부자연스러울 경우, 사람들은 쉽게 감지할 수 있다.
-
합성된 오디오는 일반적으로 초당 20,000개 이상의 데이터로 구성된 상당한 시간 해상도를 가지고 있으며, 이는 매우 효율적인 샘플링 방법을 요구한다.
따라서 이전의 연구들은 입력 텍스트로부터 파형을 생성하는 과정을 두 단계로 나누어 해결했다.
- 첫 번째 단계에서 입력 텍스트로부터 mel-spectrogram 또는 언어적 특성과 같은 중간 음성 표현을 생성하고,
- 두 번째 단계에서는 이러한 중간 표현을 조건으로 하는 원시 파형을 생성하는 것이다.
두 단계 파이프라인 시스템은 각 모델을 단순화하고 훈련을 용이하게 하는 장점이 있지만, 다음과 같은 제한 사항도 있다.
-
첫 번째 단계에서 두 번째 단계로의 오류 전파
-
모델 내부에서 학습된 표현을 활용하는 대신, mel-spectrogram이나 언어적 특성과 같이 인간이 정의한 특성을 통해 전달
-
중간 특성을 생성하는 데 필요한 계산
최근에는 이러한 제한 사항을 해결하기 위해 입력 텍스트로부터 직접 파형을 생성하는 single-stage 모델이 활발히 연구되고 있다. Single-stage 모델은 두 단계 파이프라인 시스템보다 우수한 성능을 보여주었을 뿐만 아니라, 거의 인간과 구별할 수 없는 고품질의 음성을 생성할 수 있는 능력을 보여주었다.
이전 single-stage 접근법을 사용한 작업은 다음과 같은 문제점을 가지고 있다:
-
간헐적인 부자연스러움
-
duration predictor의 효율성 저하
-
alignment 및 duration 모델링의 한계를 완화하기 위한 복잡한 입력 형식 (공백 토큰 사용)
-
다중 화자 모델에서 충분한 화자 유사성 부족
-
훈련 속도 저하
-
음소 변환에 대한 강한 의존성
본 연구에서는 이러한 문제를 해결하기 위한 방법을 제공한다.
여러 화자의 특성을 더 잘 모델링하기 위해 트랜스포머 블록과 화자 조건 텍스트 인코더를 활용하여 개선된 normalizing flows와 adversarial learning을 통해 훈련된 stochastic duration predictor를 제안한다.
2. Method
이 섹션에서는 네 가지 하위 섹션에서의 개선 사항에 대해 설명한다:
-
Duration predictor : adversarial learning을 통해 duration predictor를 훈련시켜 훈련 및 합성 모두에서 높은 효율성으로 자연스러운 음성을 합성하는 방법을 제안한다.
-
Normalizing flow : 트랜스포머 블록을 normalizing flow에 도입하여 자연스러움을 향상시키는 방법을 제안한다. 이는 분포를 변환할 때 long-term dependencies를 캡처할 수 있게 한다.
-
Alignment Search : 이전 작업에서 제안된 Monotonic Alignment Search (MAS)를 사용하여 정렬을 학습하며, 품질을 향상시키기 위한 수정을 제안한다.
-
Speaker Conditioning : 다중 화자 모델에서 화자 유사성을 개선하기 위해 speaker conditioning을 수정한다.
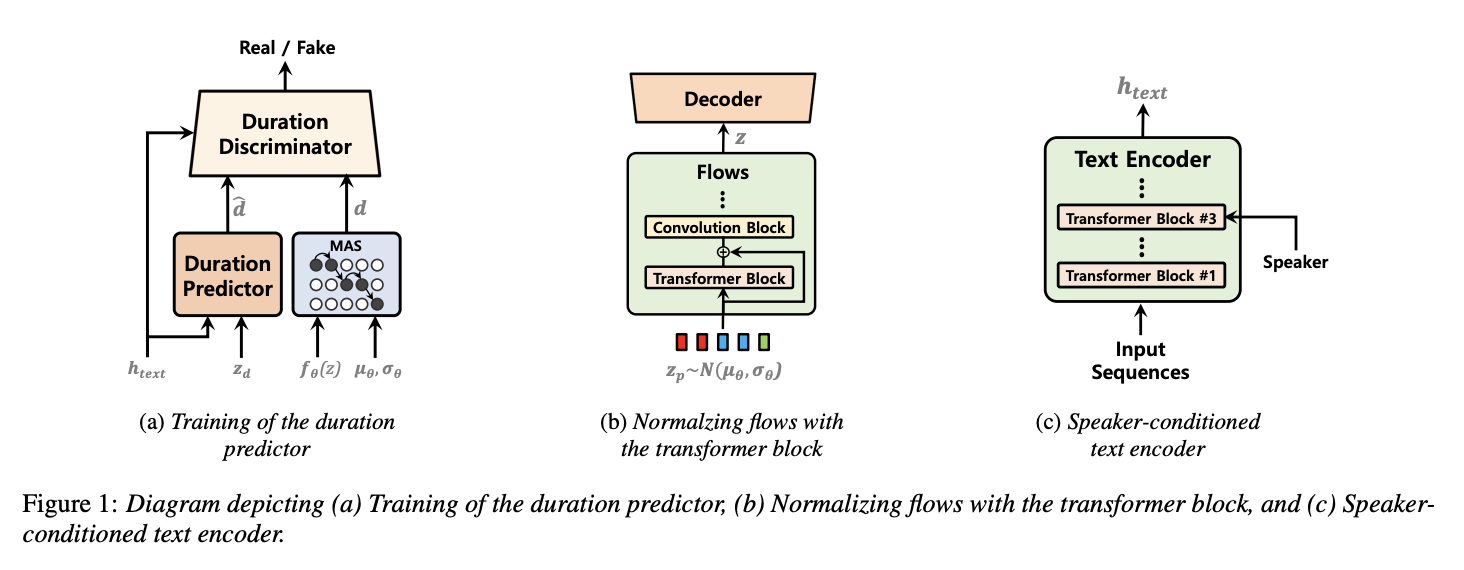
2.1. Stochastic Duration Predictor with Time Step-wise Conditional Discriminator
이전 작업에서는 flow-based stochastic duration predictor가 결정론적 접근 방식보다 합성 음성의 자연스러움을 향상시키는 데 더 효과적임을 보였다. 이 방법은 훌륭한 결과를 보여 주었지만, flow-based 방법은 비교적 더 많은 계산과 일부 정교한 테크닉이 필요하다. 본 논문에서는 이전 작업보다 훈련 및 합성 모두에서 더 자연스러운 음성을 더 높은 효율성으로 합성하기 위해 adversarial learning을 통한 stochastic duration predictor를 제안한다.
Adversarial learning을 적용하여 generator와 동일한 입력을 제공하는 conditional discriminator로 지속 예측기를 훈련한다.
- Generator와 G의 입력
- h_text : 텍스트의 숨겨진 표현
- z_d : 가우시안 노이즈
- Discriminator D의 입력
- h_text : 텍스트의 숨겨진 표현
- d : MAS로부터 얻은 로그 스케일의 duration
- dˆ : Duration predictor의 예측
일반적인 generative adversarial network의 discriminator는 패딩된 고정된 길이의 입력을 사용하지만, 각 입력 토큰의 예측된 지속 시간과 입력 시퀀스의 길이는 각 훈련 인스턴스마다 다르다. 가변 길이의 입력을 적절하게 판별하기 위해 모든 토큰의 예측된 지속 시간 각각을 개별적으로 판별하는 time step-wise discriminator를 제안한다.
손실 함수는 adversarial learning을 위한 최소 제곱 손실 함수 및 평균 제곱 오차 손실 함수를 사용한다 :
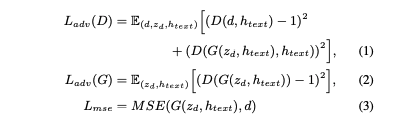
본 논문에서 제안하는 duration predictor와 훈련 메커니즘은 짧은 단계로 지속 시간을 학습할 수 있게 하며, duration predictor는 마지막 훈련 단계로 별도로 훈련되어 학습에 사용되는 전반적인 computation time을 줄인다.
2.2. Monotonic Alignment Search with Gaussian Noise
이전 작업을 따라, 모델에 MAS를 도입하여 정렬을 학습한다. 이 알고리즘은 가능한 모든 단조 정렬 중에서 가장 높은 확률을 갖는 텍스트와 오디오 간의 정렬을 산출하고, 모델은 그 확률을 최대화하도록 훈련된다. 이 방법은 효율적이지만, 특정 정렬을 검색하고 최적화한 후, 더 적절한 다른 정렬을 찾기 위한 탐색에 제한이 있다.
이를 완화하기 위해 계산된 확률에 작은 가우시안 노이즈를 추가했다. 이렇게 하면 모델이 다른 정렬을 찾을 수 있는 추가 기회를 제공한다. MAS를 통해 모델이 빠르게 정렬을 학습할 수 있기 때문에 훈련의 초기에만 이 노이즈를 추가한다.
Glow-TTS를 참조하면, Q 값은 순방향 연산에서 가능한 모든 위치에 대해 계산된 최대 로그 우도를 갖는다. 본 논문에서는 이 연산에서 계산된 Q 값에 작은 가우시안 노이즈 ϵ를 추가한다.
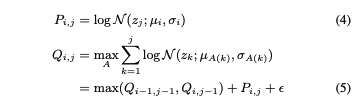
i, j : 입력 시퀀스와 사후의 특정 위치
z : 정규화 플로우에서 변환된 잠재 변수
ϵ : 표준 정규 분포에서 샘플링된 노이즈
- P의 표준 편차 및 0.01에서 시작하여 단계별로 2 × 10^-6씩 감소하는 노이즈 스케일의 곱으로 얻어진다.
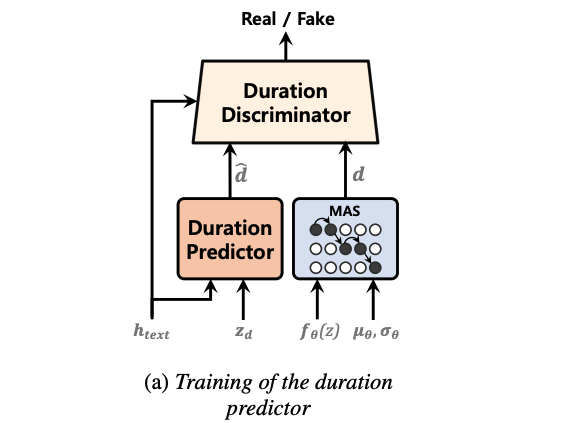
2.3. Normalizing Flows using Transformer Block
VITS는 normalizing flow를 이용한 variational autoencoder의 능력을 보여주어 고품질의 음성 오디오를 합성할 수 있음을 입증했다. Normalizing Flow는 인접 데이터의 패턴을 캡처하는 데 효과적인 Convolution Block으로 구성되어 있다. 이는 모델이 고품질 음성을 합성할 수 있도록 돕는다.
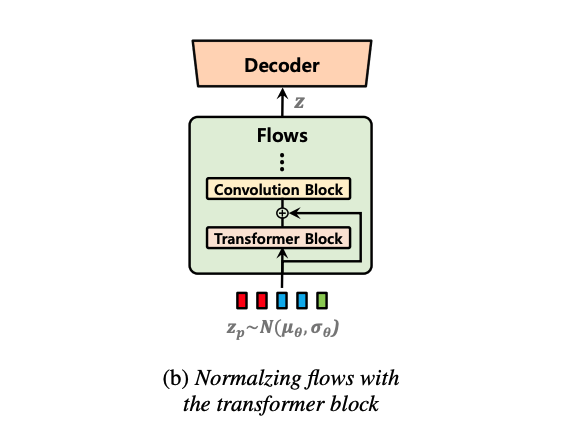
스피치의 각 부분이 인접하지 않은 다른 부분과 관련이 있기 때문에 분포를 변환할 때 장기 의존성을 포착하는 능력이 중요할 수 있다. 그러나 Convolution Block은 인접 패턴을 효과적으로 캡처하지만 receptive field의 제한으로 인해 장기 종속성을 캡처하는 데 단점이 있다. 따라서 장기 종속성을 캡처할 수 있도록 소규모의 트랜스포머 블록을 잔차 연결과 함께 normalizing flow에 추가한다.
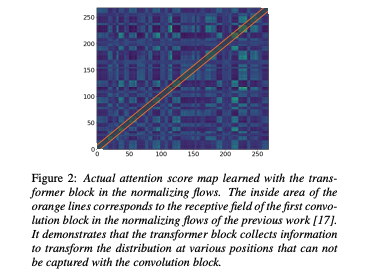
실제 어텐션 점수 맵과 컨볼루션 블록의 수용 영역을 보여준다. 트랜스포머 블록이 분포를 변환할 때 여러 위치에서 정보 수집을 가능하게 하는 것을 확인할 수 있는데, 이는 CNN의 receptive field로는 불가능했다.
2.4. Speaker-Conditioned Text Encoder
Multi-speaker 모델은 하나의 단일 모델로 speaker condition에 따른 음성을 다중 특성으로 합성하는 것이기 때문에 자연스러움뿐만 아니라 각 화자의 개별 음성 특성을 표현하는 것이 중요한 품질 요소다. 이전 연구에서는 단일 단계 모델이 고품질로 다중 화자를 모델링할 수 있음을 보여줬다.
화자의 특수한 발음과 억양과 같은 일부 특징을 고려하는 것이 각 화자의 음성 특성을 표현하는 것에 중요한 영향을 미치지만, 이는 입력 텍스트에 포함되어 있지 않다.
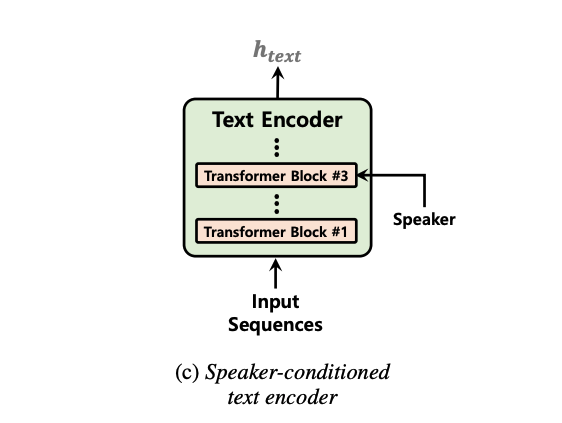
따라서 speaker information에 condition을 걸은 텍스트 인코더를 통해 입력 텍스트를 인코딩하면서 feature를 학습하여 각 화자의 다양한 음성 특성을 더 잘 모방하도록 했다.
본 연구에서는 텍스트 인코더의 세 번째 트랜스포머 블록에서 화자 벡터에 조건을 걸었다.
소감
TTS 모델에 화자의 특성을 추가해주기 위해 Multi modal, Diffusion 모델들을 찾아봤었다. 어떤 방식으로 encoder-decoder 모델의 condition으로 특성 정보를 주는 것이 효과적일지 고민하던 중에 해당 방법이 이미 구현되어 있는 Vits2 논문을 발견했다.
이러한 방법들을 생각해내고 구현했다는 사실이 대단하게 느껴진다. 나도 이렇게 전문적인 지식을 갖고, 문제점을 파악할 수 있도록, 더 나아가 그것을 해결할 방법들을 찾아낼 수 있도록 노력해야겠다.
