Paper : https://arxiv.org/abs/2307.16430
Youtube : https://www.youtube.com/watch?v=Abov0q9T4jU
VITS2 논문은 [Capstone #6] VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design에서 확인하실 수 있습니다.
[SK TECH SUMMIT 2023] 개인화 AI 보이스
Single-Speaker Model
Multi-Speaker Model
: 하나의 모델 안에 여러 화자를 모델링
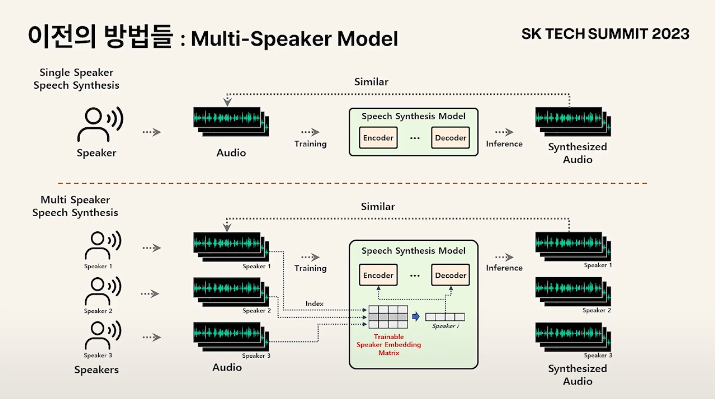
Speaker Embedding Matrix에 각 화자들의 벡터를 하나씩 지정해서 화자들의 발화 특성을 표현
화자 확장에 제한
: 새로운 화자를 추가할 경우 Embedding Matrix에 vector가 추가되어야하는데, 이 임베딩 벡터는 Encoder, Decoder와 함께 학습되는 파라미터이기 때문에 모델 구조의 변경이 됨을 의미
- Encoder, Decoder의 변경
- 다른 파라미터들도 업데이트되어야 함
- 결론적으로 모델 전체를 다시 학습되어야 함
Zero-Shot Approch
: 별도의 외부의 대량의 Speaker로 일반화 되어있는 Speaker Encoder를 사용하여 기존에 모델 안에서 학습되던 Speaker vector를 외부에서 받아온 뒤 이를 컨디셔닝 하여 합성 모델을 학습
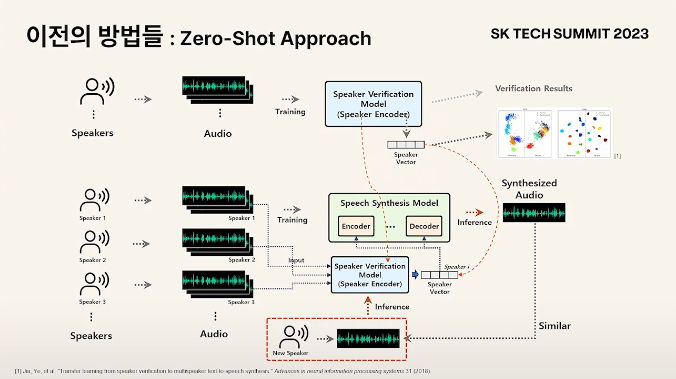
화자 확장에 제한이 생기는 문제를 해결하기 위해 비학습적인 방법을 고안
- inference 시 새로운 speaker가 들어오면 해당 음성을 encoder에 넣고, 벡터를 뽑은 뒤, 이를 컨디셔닝 하여 음성을 생성하면 화자와 유사한 음성이 나올것이라는 것을 전제로 두고 개발
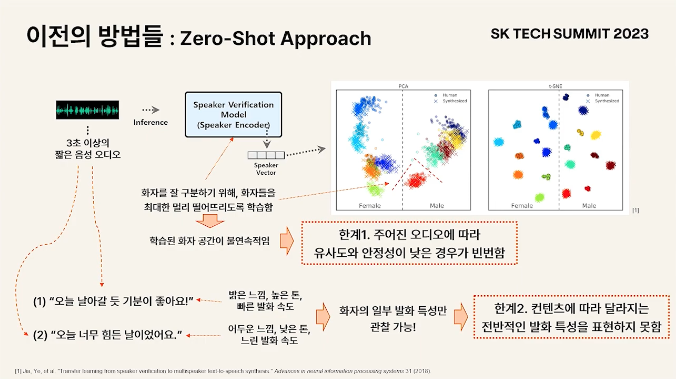
한계
-
Speaker Encoder가 speaker를 구분하기 위한 모델임. 따라서 decision boundary를 잘 긋기 위해서 모델은 speaker들을 다 떨어뜨려둠
- 학습된 화자 공간이 sparse 함
-
같은 사람이지만 의미가 다른 문장을 읽었을 경우 다른 발화 특성을 보임
- 짧은 오디오에서 관찰할 수 있는 발화 특성은 contents에 align되어있는데, contents를 여러가지를 보지 못한 상태에서 화자의 전반적인 발화 특성을 모델링하기 어려움
VITS2
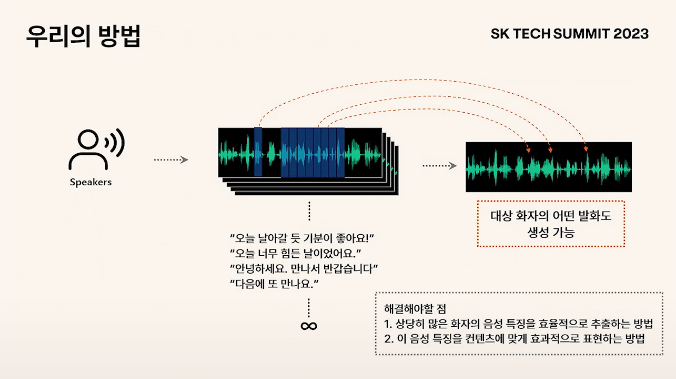
화자의 음성 오디오가 많을 경우 "음성 각 부분의 발화 특성을 모두 추출해서 보관 후 합성 시 각 부분에 맞도록 입혀주는 것이 가능하다면, 해당 인물의 모든 contents에서의 발화 특성을 모두 표현할 수 있는 것이 아닐까?"
해결해야 할 점
-
상당히 많은 화자의 음성 특징을 어떻게 추출하고 어떻게 효율적으로 보관할것인가
-
음성 특징을 어떻게 합성되는 오디오에 입혀줄것인가
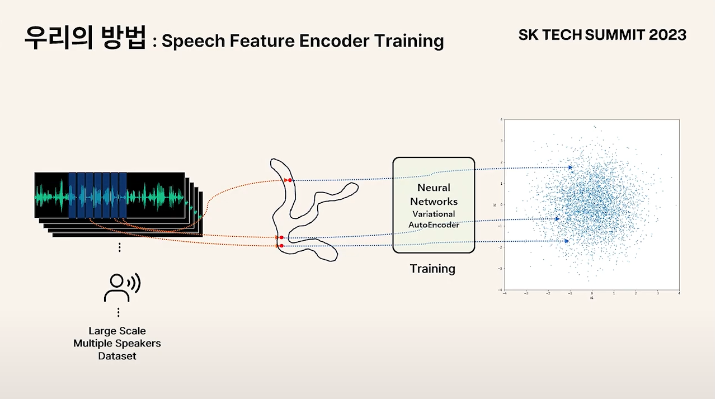
-
음성 오디오의 분포를 알 수 없기 때문에 예측하고 다룰 수 있는 분포로 Transform
- VAE를 사용하여 Gaussian 분포에 fit이 되도록 학습
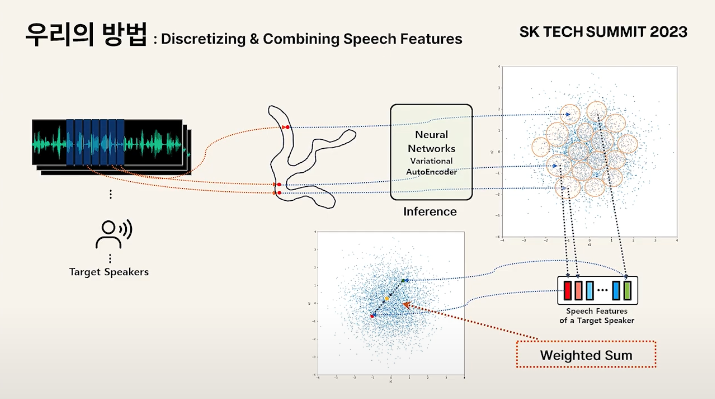
Target Speaker의 다양한 오디오로부터 분포에 매핑된 데이터 포인트를 찍는데, 클러스터링을 통해 여기서 대표되는 feature를 뽑음
-
클러스터링 한 센트로이드들을 모아서 화자의 음성 특징이라 정의
-
연속공간에서 데이터가 분포되어 있었을 것이기 때문에 중간점이 있어야 음성을 복원할 수 있음
중간점을 어떻게 뽑아올 것인가에 대한 솔루션
-
두 개의 벡터의 선형 결합을 하면 벡터 사이의 어떤 점이라도 연속적인 공간에서 샘플링하는 것이 가능
- Sum to one이 되는 weight를 사용하는 Weighted Sum을 사용함으로써 해결
- Attention이 softmax attention score를 사용하는 경우에 sum to one이 되는 weight로 weighted sum을 하게 됨
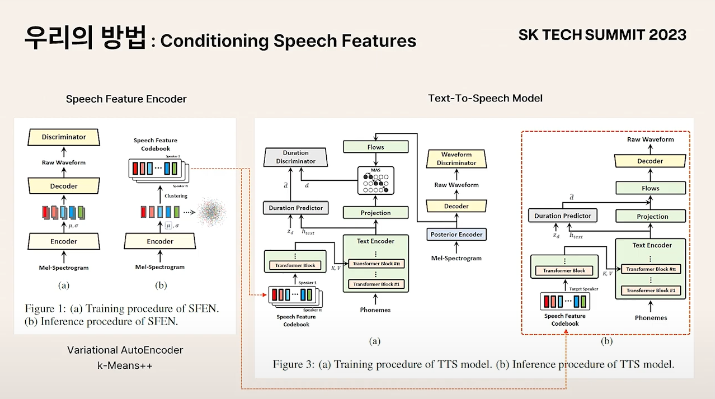
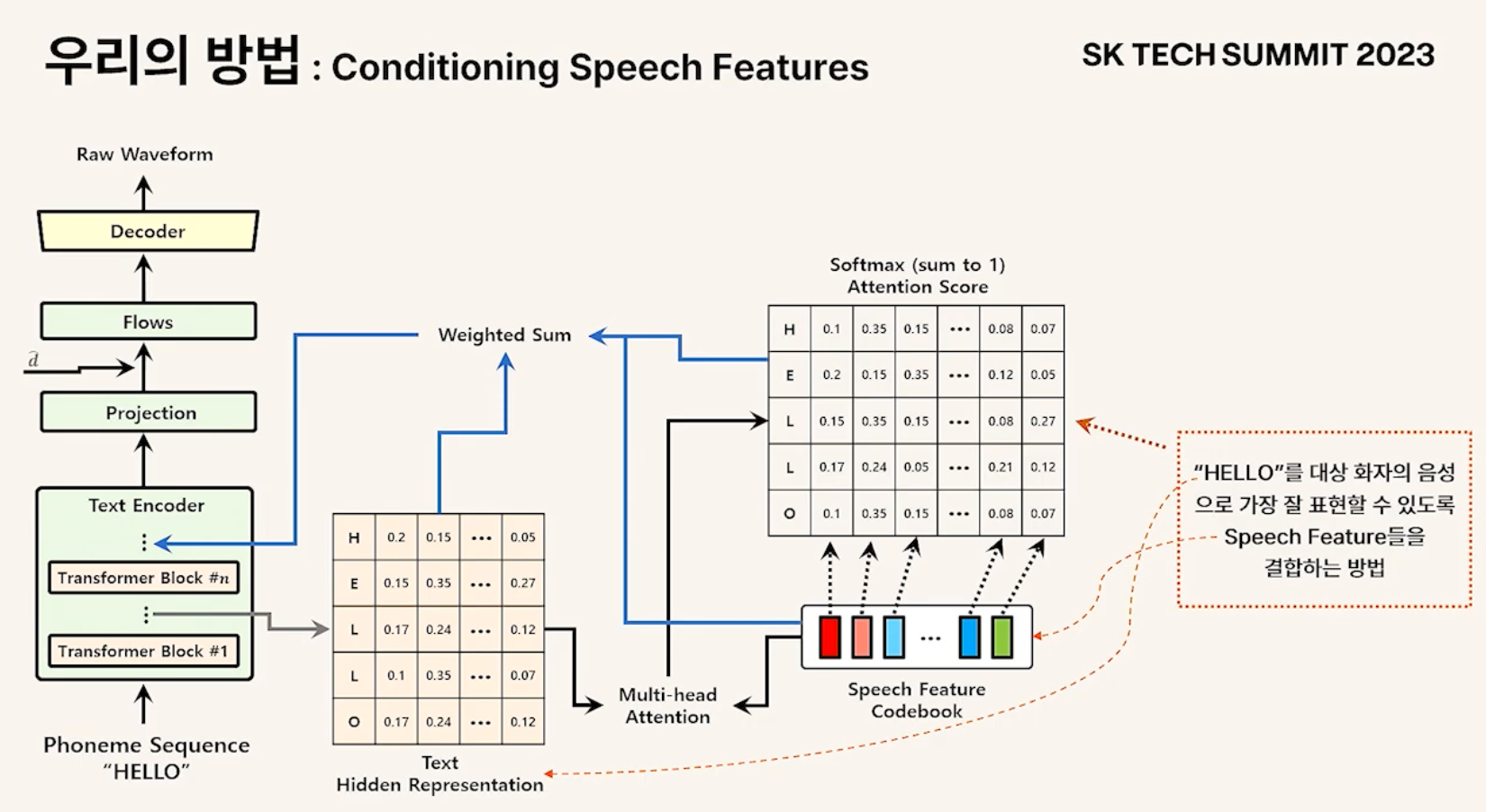
- SFEN : speaker를 인코딩, featre를 뽑아 학습/추론 시 텍스트 인코더에 컨디셔닝
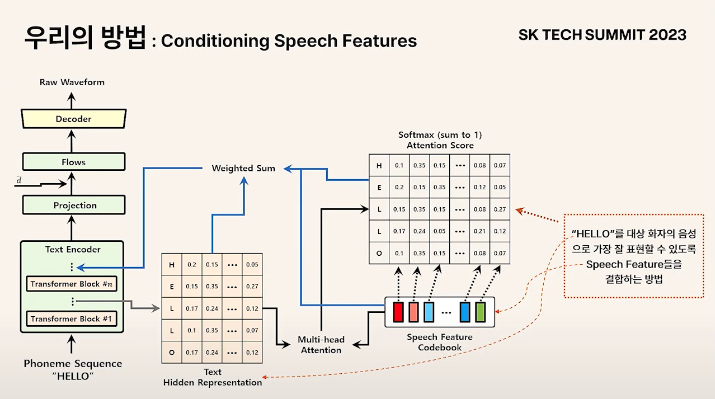
-
Phoneme Sequence가 Encoder에 들어갈 경우 각 time step에 대한 hidden representation이 만들어짐
-
Time step에 대한 hidden representation과 Speech feature matrix와 attention
-
구해진 attention score matrix는 해당 알파벳을 화자에 맞게 가장 잘 표현할 수 있도록 feature들을 조합하는 방법을 나타냄
-
Vector들을 attention score에 맞게 weighted sum 후 다시 넣어주면 continuous discretize된 데이터 포인트에서 continuous space에서 샘플링하는 효과를 얻을 수 있게 됨
-
Attention matrix는 표현하려고 하는 contents를 대상 화자로 가장 잘 표현할 수 있게 해주는 speech feature를 조합하는 방법을 나타냄
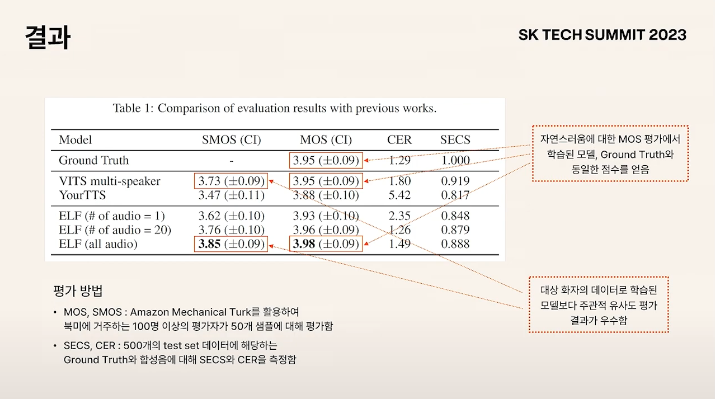
비학습적인 방법이 유사도가 높게 나옴을 확인
- VITS multi-speaker : 대상 화자 데이터셋으로 학습이 된 모델
- ELF : 비학습적인 본 논문의 방법
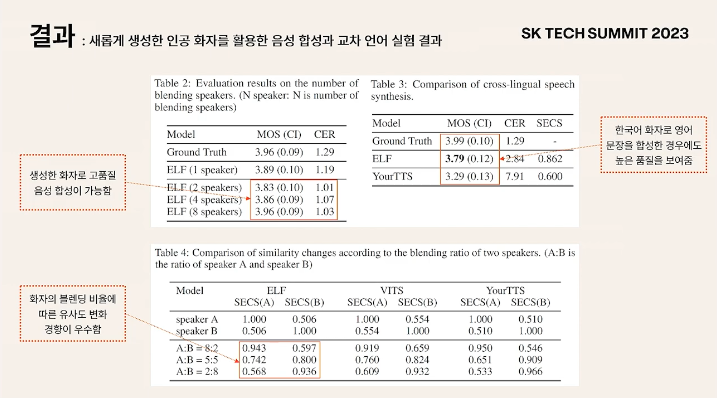
Speaker blending : speaker feature space에서 다른 speaker의 feature들을 잘 조합한다고 하면 또 다른 speaker를 만들어 낼 수 있음
- Speaker space가 sparse 하기 때문에 out of distribution data point가 뽑힐 수 있는 가능성이 높았는데, 본 논문에서 제시한 모델의 경우 Speaker blending에서도 좋은 성능을 보여줌
소감
Speaker encoder에서 추출된 hidden representation을 클러스터링 하는 방법을 적용하여 화자 확장의 제한을 극복했으며, 같은 인물이라도 contents 별로 음성의 특성이 달라 화자의 전반적인 발화 특성을 모델링하기 어렵다는 문제점을 해결했다.
학습된 화자 공간이 불연속적이기 때문에 OOD가 발생할 확률이 높다는 문제점도 있었는데, weighted sum을 사용하는 attention을 적용함으로써 continuous space로 복원이 가능하게 했다.
위 내용은 논문만 읽었을 때 알기 힘든 부분인데, TECH SUMMIT에서 설명해 주셔서 감사하다. VITS2를 구현해 둔 커뮤니티 코드 2개 버전이 있는데, 두 리포지토리 모두 음성을 클러스터링 하여 화자의 특성을 모델링 하는 부분은 구현되어 있지 않은 것으로 확인했다. 프로젝트 마감일이 얼마 남지 않았으니 빠르게 구현해 봐야겠다.
