[Capstone #7] Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Capstone
Paper : https://arxiv.org/abs/2106.06103
Github : https://github.com/jaywalnut310/vits
Abstract
최근 single-stage training과 parallel sampling이 가능한 end-to-end TTS 모델들이 제안되었지만, two-stage TTS 시스템보다 샘플 품질이 뛰어나지 않다. 본 논문에서는 현재의 two-stage 모델보다 더 자연스러운 소리를 생성하는 병렬 end-to-end TTS 방법을 제안한다.
Normalizing flows로 확장된 variational inference와 adversarial training process를 도입하여 generative modeling의 표현력을 향상시킨다.
또한 입력 텍스트에서 다양한 리듬으로 음성을 합성하기 위해 stochastic duration predictor를 제안한다. Latent variables에 대한 불확실성 모델링과 stochastic duration predictor를 통해 텍스트 입력이 다양한 pitch와 rhythm으로 여러 가지 방법으로 발음될 수 있는 자연스러운 1:N 관계를 표현한다.
Single speaker dataset LJ Speech에 대한 MOS는 본 논문의 방법이 가장 좋은 공개적으로 사용 가능한 TTS 시스템보다 더 뛰어나며, 실제와 비교 가능한 MOS를 달성한다는 것을 보여준다.
1. Introduction
TTS 시스템은 주어진 텍스트로부터 raw speech waveform을 합성한다. Deep neural network의 빠른 발전으로 인해, TTS 시스템 파이프라인은 normalization과 phonemization과 같은 텍스트 전처리를 제외하고 two-stage generative modeling으로 단순화되었다.
-
전처리된 텍스트로부터 melspectrogram이나 linguistic features과 같은 중간 음성 표현을 생성
-
중간 표현에 대한 condition으로 raw waveforms을 생성
two-stage pipeline의 각 단계 모델은 독립적으로 개발되었다.
Neural network-based autoregressive TTS system은 실제같은 음성을 합성하는 능력을 보였지만, sequential한 generative process 때문에 현대 병렬 프로세서를 완전히 활용하기 어렵다. 이러한 제한을 극복하고 합성 속도를 향상시키기 위해 여러 non-autoregressive 방법이 제안되었다.
-
Text-to-spectrogram generation step : pre-trained autoregressive teacher network에서 attention map을 추출하여 텍스트와 spectrogram 간의 정렬 학습 난이도를 줄이려 시도
-
Likelihood-based method : 목표 mel-spectrogram의 likelihood를 최대화하는 alignment를 추정하거나 학습함으로써 외부 정렬기에 대한 의존성을 제거
-
Generative adversarial network : second stage model에서 다양한 판별자를 가진 GAN-based feed-forward network는 각각 다른 scales나 periods에서 샘플을 구별하여 고품질의 raw waveform 합성
병렬 TTS 시스템의 발전에도 불구하고, two-stage pipeline은 여전히 문제가 남아 있다.
-
높은 품질의 생성을 위해 후반 단계 모델이 초기 단계 모델의 생성 샘플로 훈련 또는 미세 조정을 요구
-
사전에 정의된 mediate features에 대한 의존성으로 인해 learned hidden representation을 적용하여 성능을 더 개선하는 것이 불가능
최근에는 FastSpeech 2s와 EATS와 같은 여러 연구에서 효율적인 end-to-end 훈련 방법을 제안했다.
-
전체 파형이 아닌 짧은 오디오 클립을 기반으로 훈련
-
mel-spectrogram decoder를 활용하여 text representation learning을 지원
-
target과 생성된 음성 간의 길이 불일치를 완화하기 위해 전용 spectrogram loss를 설계
그러나 학습된 표현을 활용하여 성능을 향상시킬 수 있음에도 불구하고, 합성 품질은 two-stage 시스템에 비해 뒤떨어진다.
본 논문에서는 현재의 two-stage 모델보다 더 자연스러운 음성을 생성하는 parallel end-to-end TTS 방법을 제안한다. VAE를 사용하여 TTS 시스템의 두 모듈을 잠재 변수를 통해 연결하여 효율적인 end-to-end 학습을 가능하게 한다.
고품질의 음성 파형이 합성될 수 있도록 모델의 표현력을 향상시키기 위해 다음 방법을 수행한다.
-
conditional prior distribution에 normalizing flow 적용
-
waveform 도메인에서 adversarial training을 시행
고해상도 오디오를 생성하는 것 외에도, TTS 시스템이 텍스트 입력이 pitch, duration 등이 여러 가지 방식으로 발음될 수 있는 1:N 관계를 표현하는 것이 중요하다. 1:N 문제에 대처하기 위해 본 논문에서는 입력 텍스트로부터 다양한 리듬으로 음성을 합성하기 위한 stochastic duration predictor를 제안한다. Latent variable에 대한 불확실성 모델링과 stochastic duration predictor를 통해 텍스트로 표현할 수 없는 speech variations를 포착한다.
2. Method
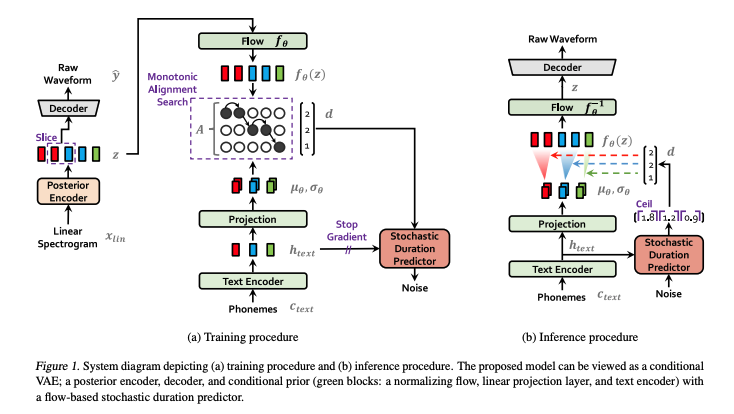
- Conditional VAE 공식
- Variational inference에서 유도된 alignment estimation
- 합성 품질 향상을 위한 adversarial training
2.1. Variational Inference
Overview
VITS는 variational lower bound, 즉 Evidence Lower Bound (ELBO)를 최대화하는 conditional VAE로 표현될 수 있다. 이는 intractable marginal log-likelihood인 log pθ(x|c)의 variational lower bound이다.
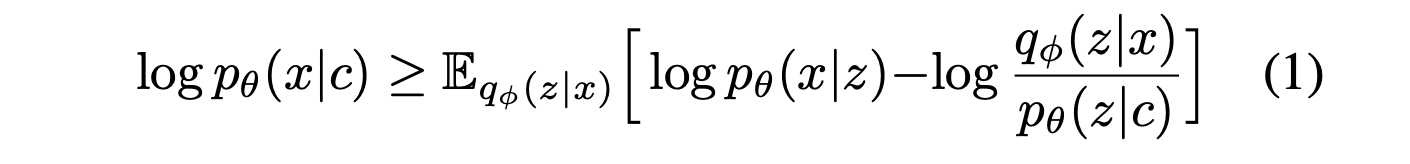
pθ(z|c) : condition c가 주어졌을 때 latent variable z의 prior distribution
pθ(x|z) : 데이터 점 x의 likelihood function
qφ(z|x) : approximate posterior distribution
training loss는 음의 ELBO로, reconstruction loss -log pθ(x|z)와 KL divergence log qφ(z|x) - log pθ(z|c)의 합으로 볼 수 있다. 여기서 z ∼ qφ(z|x)다.
Reconstruction loss
-
Reconstruction loss에서 target data point로 raw waveform이 아닌 mel-spectrogram을 사용하며, 이를 x_mel로 표시한다.
-
latent variable z를 waveform 도메인 y hat으로 업샘플링하여 디코더를 통해 mel-spectrogram 도메인 x hat_mel로 변환한다.
-
예측된 mel-spectrogram과 대상 mel-spectrogram 간의 L1 loss를 reconstruction loss로 사용한다.
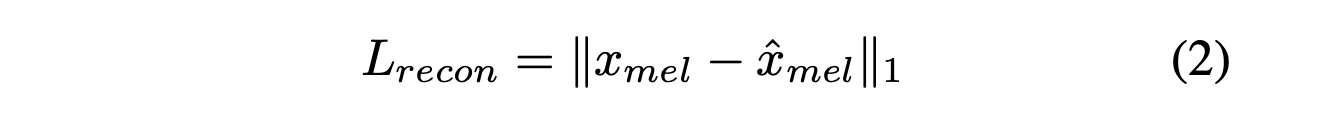
이는 데이터 분포에 대해 Laplace distribution을 가정하고 상수항을 무시하여 maximum likelihood estimation으로 볼 수 있다. Mel-scale을 사용하여 인간의 청각 시스템의 응답을 근사화하는 mel-spectrogram 도메인에서 reconstruction loss를 정의한다.
Raw waveform에서 mel-spectrogram 추정은 STFT 및 mel-scale로의 linear projection만 사용하므로 학습 가능한 매개변수가 필요하지 않다. 또한, 추정은 훈련 중에만 사용되며 추론 중에는 사용되지 않는다.
실제로 전체 잠재 변수 z를 업샘플링하지 않고 디코더의 입력으로 부분 시퀀스를 사용한다. 이것은 효율적인 end-to-end 훈련에 사용되는 windowed generator training이다.
Laplace distribution
KL-Divergence
Prior Encoder의 입력 조건 c는 다음과 같이 구성된다.
- 텍스트에서 추출된 음소 c_text
- 음소와 잠재 변수 간의 alignment A
Alignment은 |c_text| × |z| 크기의 hard monotonic attention matrix로, 각 입력 음소가 목표 음성에 시간 정렬될 때 얼마나 확장되는지를 나타낸다. Alignment에 대한 정답 레이블이 없기 때문에, 각 학습 반복마다 정렬을 추정해야 한다.
본 논문의 문제 설정에서는 Posterior Encoder에 더 높은 해상도의 정보를 제공하는 것이 목표다. 따라서 mel-스펙트로그램 대신 타겟 음성의 선형 스케일 스펙트로그램 x_lin을 입력으로 사용한다.
수정된 입력은 variational inference의 특성을 위반하지 않는다. KL Divergence는 다음과 같다:
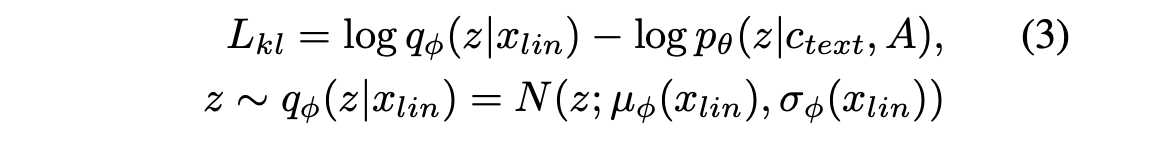
Prior와 Posterior 인코더를 매개변수화하기 위해 인수분해된 정규 분포를 사용한다. Prior 분포의 표현력을 증가시키는 것이 현실적인 샘플을 생성하는 데 중요하다는 것을 발견했다. 따라서 간단한 분포의 가역 변환을 통해 더 복잡한 분포로 변환할 수 있게 해주는 Normalizing flow fθ를 인수분해된 정규 prior 분포 위에 적용한다:
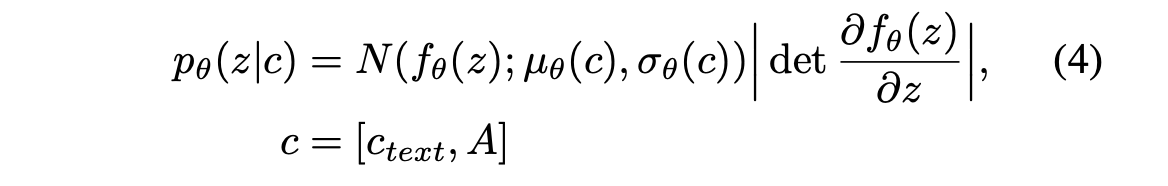
2.2. Alignment Estimation
Monotonic Alignment Search
입력 텍스트와 목표 음성 간의 Alignment A를 추정하기 위해 Monotonic Alignment Search (MAS)를 채택한다. 이는 Normalizing flow f에 의해 매개변수화된 데이터의 가능도를 최대화하는 정렬을 찾는 방법이다:
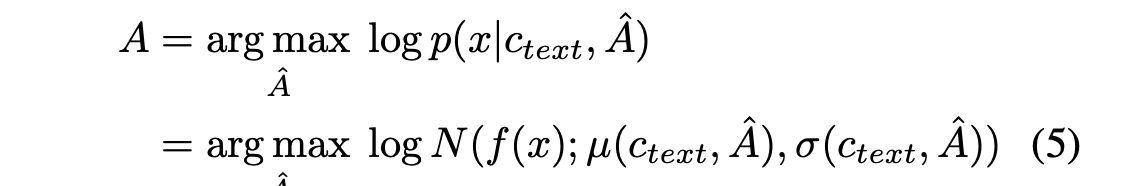
여기서 후보 alignments는 사람이 텍스트를 순서대로 읽으며 단어를 건너뛰지 않는다는 사실에 따라 단조롭고 건너뛰지 않는 것으로 제한된다. 최적 정렬을 찾기 위해 Kim et al. (2020)은 동적 프로그래밍을 사용한다.
본 논문의 목표는 정확한 log likelihood가 아니라 ELBO이기 때문에 MAS를 직접 적용하기 어렵다. 따라서 ELBO를 최대화하는 정렬을 찾기 위해 MAS를 재정의하여 잠재 변수 z의 likelihood를 최대화하는 정렬을 찾는다:
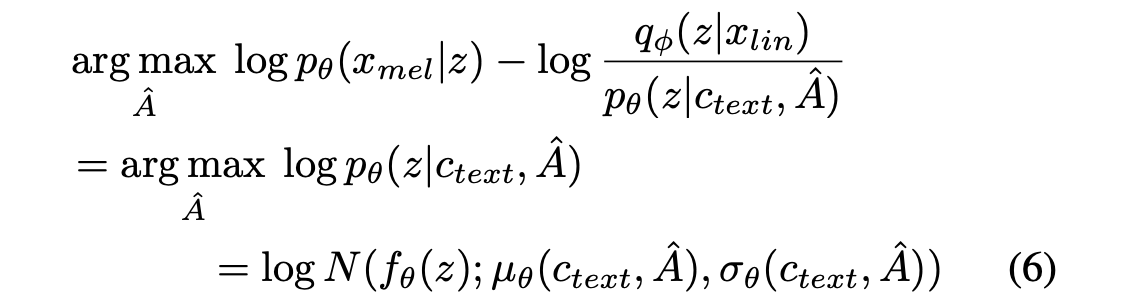
식 5와 식 6의 유사성 덕분에, 원래 MAS 구현을 수정 없이 사용할 수 있다. 부록 A에는 MAS의 의사 코드가 포함되어 있다.
Duration Prediction From Text
추정된 정렬의 각 행의 모든 열을 합산하여 각 입력 토큰의 지속 시간 d_i를 계산할 수 있다 : ∑j A{i,j}
Duration은 이전 연구 (Kim et al., 2020)에서 제안한 것처럼 결정론적 Duration Predictior를 훈련하는 데 사용할 수 있지만, 이는 사람이 매번 다른 말하기 속도로 발음하는 방식을 표현할 수 없다.
인간과 같은 말하기 리듬을 생성하기 위해 주어진 음소의 지속 시간 분포를 따르는 샘플을 생성하는 Stochastic Duration Predictior를 설계한다.
Stochastic Duration Predictior는 보통 maximum likelihood estimation을 통해 훈련되는 flow-based generative model이다.
그러나 각 입력 음소의 지속 시간이
- 이산 정수이므로 연속적인 정규화 흐름을 사용하기 위해 dequantizing이 필요하고,
- 스칼라이므로 가역성으로 인해 고차원 변환을 방해한다.
이러한 문제를 해결하기 위해 Variational Dequantization과 Variational Data Augmentation을 적용한다. 구체적으로, Variational Dequantization과 Variational Data Augmentation을 위해 지속 시간 시퀀스 d와 같은 시간 해상도 및 차원을 가진 두 개의 랜덤 변수 u와 ν를 도입한다.
- u의 지원을 [0, 1)로 제한하여 d−u가 양의 실수 시퀀스가 되도록 하고,
- ν와 d를 채널 방식으로 연결하여 고차원 잠재 표현을 만든다.
- 두 변수는 qϕ(u,ν_∣d,c_text)의 근사 후방 분포를 통해 샘플링된다.
결과 objective는 Phoneme Duration의 log-likelihood의 variational lower bound다:
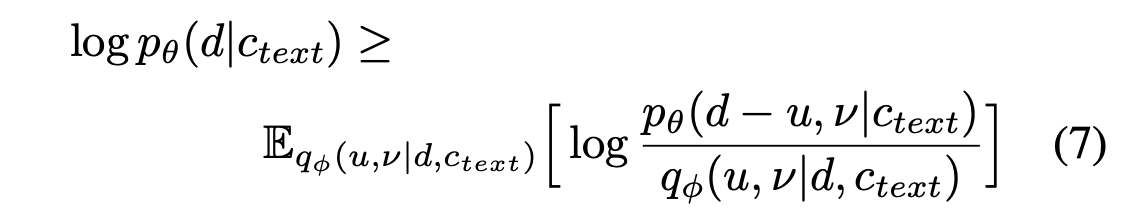
훈련 손실 L_dur는 variational lower bound의 음수이다. Duration Predictior의 훈련이 다른 모듈에 영향을 미치지 않도록 입력 조건에 대해 그라디언트 역전파를 방지하는 정지 그라디언트 연산자를 적용한다.
샘플링 절차는 비교적 간단하다. Phoneme Duration은 Stochastic Duration Predictior의 역변환을 통해 랜덤 노이즈에서 샘플링되고, 그런 다음 정수로 변환된다.
2.3. Adversarial Training
학습 시스템에 Adversarial Training을 도입하기 위해, 디코더 G가 생성한 출력과 실제 파형 y를 구별하는 Discriminator D를 추가한다. 이 작업에서는 음성 합성에 성공적으로 적용된 두 가지 손실 유형을 사용한다.
- 적대적 학습을 위한 least-squares loss
- 생성기 훈련을 위한 additional feature matching loss
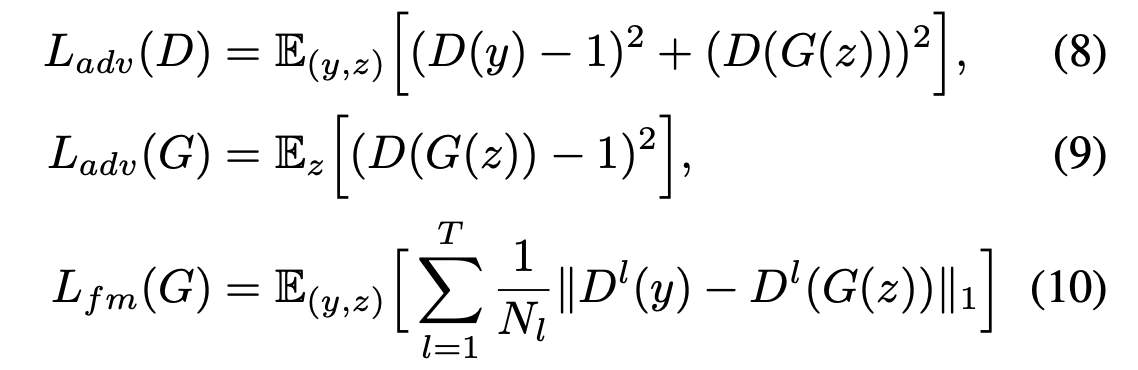
T : 판별자의 전체 레이어 수
D^l : 판별자의 l번째 레이어의 특징 맵을 출력
N_l : 특징의 수
특히, feature matching loss는 VAE의 요소별 재구성 손실의 대안으로 제안된 판별자의 숨겨진 레이어에서 측정되는 reconstruction loss로 볼 수 있다.
2.4. Final Loss
VAE와 GAN 훈련을 결합하여 조건부 VAE를 훈련하기 위한 총 손실은 다음과 같이 표현된다:
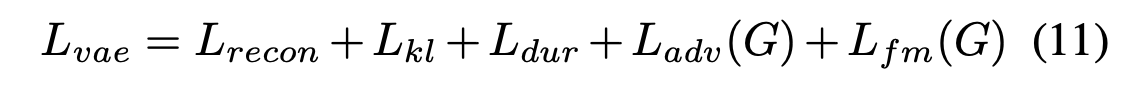
2.5. Model Architecture
제안된 모델의 전체 아키텍처는 Posterior Encoder, Prior Encoder, Decoder, Discriminator, Stochastic Duration Predictor로 구성된다. Posterior Encoder와 Discriminator는 추론에 사용되지 않고 학습에만 사용된다.
Posterior Encoder
Posterior Encoder는 WaveGlow와 Glow-TTS에서 사용된 비인과적 WaveNet residual block을 사용한다. WaveNet residual block은 gated activation unit과 skip connection이 있는 확장된 합성곱 레이어들로 구성된다.
Residual block 위의 linear projection layer는 normal posterior distribution의 평균과 분산을 생성한다. 다중 화자 설정에서는 residual block에 글로벌 컨디셔닝을 사용하여 화자 임베딩을 추가한다.
Prior Encoder
Prior Encoder는 다음과 같이 구성된다:
- 입력 음소 c_text를 처리하는 텍스트 인코더
- 사전 분포의 유연성을 향상시키는 Normalizing flow f_θ
텍스트 인코더는 절대 위치 인코딩 대신 상대 위치 표현을 사용하는 트랜스포머 인코더이다. 텍스트 인코더와 그 위의 linear projection layer를 통해 c_text로부터 숨겨진 표현 h_text를 얻을 수 있으며, 이는 사전 분포를 구성하는 데 사용되는 평균과 분산을 생성한다.
Normalizing flow는 WaveNet residual block으로 구성된 affine coupling layers 스택이다. 단순성을 위해 normalizing flow은 Jacobian 행렬식이 1인 부피 보존 변환으로 설계되었다.
다중 화자 설정에서는 전역 조건화를 통해 화자 임베딩을 normalizing flow의 residual block에 추가한다.
Decoder
Decoder는 본질적으로 HiFi-GAN V1 generator다. 이는 각 레이어마다 multireceptive field fusion module (MRF)이 뒤따르는 transposed convolution 스택으로 구성된다.
MRF의 출력은 서로 다른 수용 영역 크기를 가진 residual block의 출력을 합한 것이다. 다중 화자 설정에서는 linear layer를 추가하여 화자 임베딩을 변환하고 이를 입력 잠재 변수 z에 추가한다.
Discriminator
Discriminator는 HiFi-GAN에서 제안된 multi-period discriminator 의 아키텍처를 따른다. Multi-period discriminator는 입력 파형의 다양한 주기 패턴에서 작동하는 Markovian 윈도우 기반 sub-discriminators의 혼합물이다.
Stochastic Duration Predictor
Stochastic Duration Predictor는 조건부 입력 h_text에서 음소 지속 시간의 분포를 추정한다. Stochastic Duration Predictor의 효율적인 매개변수화를 위해 확장 및 깊이 분리 합성곱 레이어가 있는 residual block을 스택한다.
또한 coupling layers에 monotonic rational-quadratic splines를 사용하여 가역적 비선형 변환을 수행하는 neural spline flows을 적용한다. Neural spline flows은 일반적으로 사용되는 affine coupling layers와 비교하여 유사한 수의 매개변수로 변환 표현력을 향상시킨다.
다중 화자 설정에서는 선형 레이어를 추가하여 화자 임베딩을 변환하고 이를 입력 h_text에 추가한다.
