[UROP #1] Tailoring Instructions to Student’s Learning Levels Boosts Knowledge Distillation (1)
UROP
Github : https://github.com/twinkle0331/LGTM
Paper : https://arxiv.org/abs/2305.09651
💡 로 표시된 부분은 제가 이해한 내용을 적은 부분입니다. 오류가 있다면 댓글로 남겨주세요 🙏🏻
Introduction
자연어 처리(NLP)의 최근 성공은 대규모 사전 훈련된 언어 모델의 도입에 의해 주도되었다. 이러한 모델은 깊이와 너비가 계속 확장되면서 계산 및 저장 용량이 증가하며, 배포가 어려워지고 있다.
이 문제를 해결하기 위해 성능 손실을 최소화하면서 효율적인 모델을 개발하는 다양한 방법이 제안되었다.
- 가중치 가지치기(weight pruning)
- 네트워크 양자화(network quantization)
- 지식 증류(Knowledge Distillation, KD)
KD의 아이디어는 가벼운 학생 모델에게 큰 교사 모델의 출력을 모방하도록 요청하여 지식을 전달하는 것이다.
일반적으로 우수한 성능을 가진 교사 모델이 일반화 성능이 좋은 학생 모델을 만들 수 있을거라 생각하지만, 교사 모델의 높은 성능이 반드시 성능이 더 우수한 학생으로 이어지지 않을 수 있으며, 심지어 성능 저하를 일으킬 수도 있다고 관찰되었다.
- 학생과 교사 간의 모델 용량 차이가 커짐에 따라 최적화 과정이 지역 최적점에 갇힐 가능성이 더 높아진다는 것이다.
distillation influence
교사 모델의 학습 과정을 향상시키기 위해, 각 train 샘플이 학생 모델의 일반화 능력에 미치는 영향을 결정하기 위한 개념이다.
Learning Good Teacher Matters (LGTM)
distillation influence을 교사 모델의 학습 과정에 통합하는 효율적인 교육 기술이다.
학생의 일반화 능력을 향상시킬 가능성이 높은 샘플을 우선으로 하여, LGTM은 GLUE 벤치마크의 6개 텍스트 분류 작업에서 10가지 일반적인 지식 증류 기준을 능가한다고 한다.
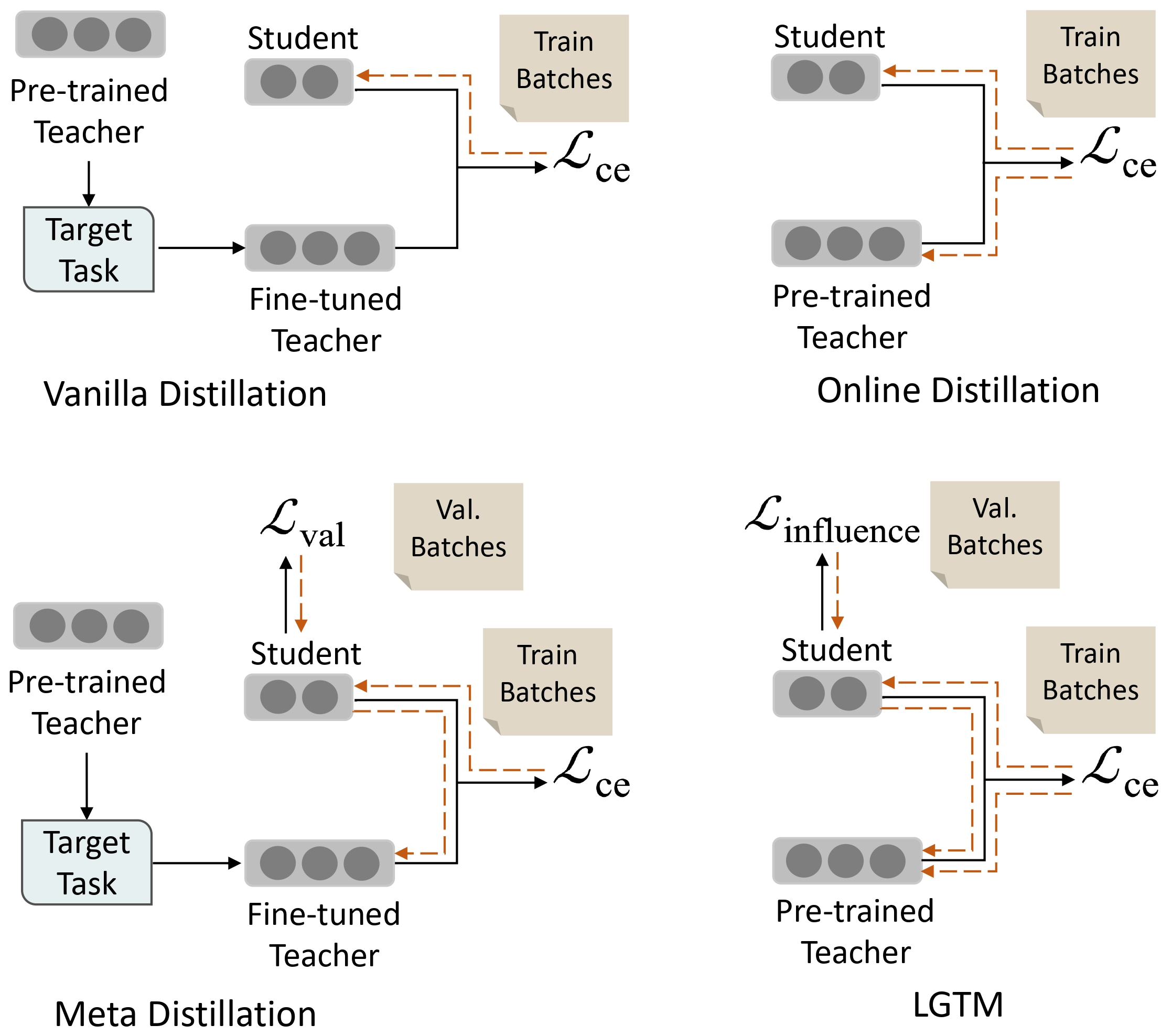
Learning to Teach Algorithm
지식 증류(KD)에서 성능 저하를 해결하는 한 가지 방법은 학생 모델의 성능 피드백을 통해 교사 모델을 업데이트하는 것이며, 이를 "가르치기를 배우는(L2T)"라고 한다.
온라인 증류(Online Distillation)
- 학생 모델과 교사 모델을 동시에 훈련하고, 훈련 세트에서 그들의 출력 간 유사성을 강제한다.
- 그러나 학생이 검증 세트에서 얼마나 잘 수행할지 명시적으로 고려하지 않고 교사의 지식을 훈련 세트에서 학생에게 전달하는 데 중점을 둔다.
메타 증류(Meta Distillation)
- 학생 모델의 일반화 능력을 보유된 검증 세트에서 고려하고, 교사의 학습 과정을 일반화 능력을 극대화하기 위해 가이드한다.
- 메타 증류의 최적화 목표는 학생 모델로부터 지도만 받기 때문에 교사 모델의 성능 저하를 초래할 수 있다.
현재 지식을 기반으로 특정 문제에 얼마나 많은 주의를 기울여야 하는지에 대한 지침을 제공하는 교사로부터 지도를 받을 때 더 효율적으로 학습한다.
교사는 훈련 중에 학생의 일반화 능력을 향상시킬 가능성이 높은 샘플을 우선시해야 하며, 이를 통해 학생이 보류 중인 검증 세트에서 더 나은 성능을 발휘할 수 있게 해야 한다.
증류 영향(distillation influence)
- 각 훈련 샘플에 대한 증류가 학생의 검증 세트에서의 성능에 어떤 영향을 미치는지 추정할 수 있다.
- L2T(가르치기를 배우는) 방법을 영향 함수의 관점에서 해석함으로써 그 제한 사항에 대한 깊은 이해를 얻을 수 있다.
기존의 L2T 방법의 최적화 과정은 종종 이상값(outliers)에 의해 영향을 받는데, 이는 미니배치 내의 모든 훈련 샘플에 동일한 가중치를 할당하기 때문이다.
따라서 Learning Good Teacher Matters (LGTM)라는 L2T 프레임워크를 제안했다. 이 프레임워크는 훈련 샘플의 손실 가중치를 그들의 증류 영향을 기반으로 할당한다.
-
증류 영향을 제안하여 각 훈련 샘플로부터 증류가 학생의 일반화 능력에 어떤 영향을 미치는지 양적으로 평가한다.
-
유한 차분 근사법을 도입하여 증류 영향을 교사의 학습 과정에 효율적으로 통합한다.
-
10가지 일반적인 지식 증류(KD) 기준과 비교하여, 제안된 LGTM은 GLUE 벤치마크의 6개 텍스트 분류 작업에서 일관되게 우수한 성능을 보인다.
Revisiting Learning to Teach
논문에서는 사전 훈련된 언어 모델을 기반으로 한 과제별 지식 증류에 초점을 맞추고 있다. 이 설정에서 교사 모델은 이미 비지도 방식으로 사전 훈련되어 있으며, 학생 모델은 교사 모델의 일부로부터 파생되거나 또는 비지도 방식으로 사전 훈련되기도 한다.
Vanilla distillation
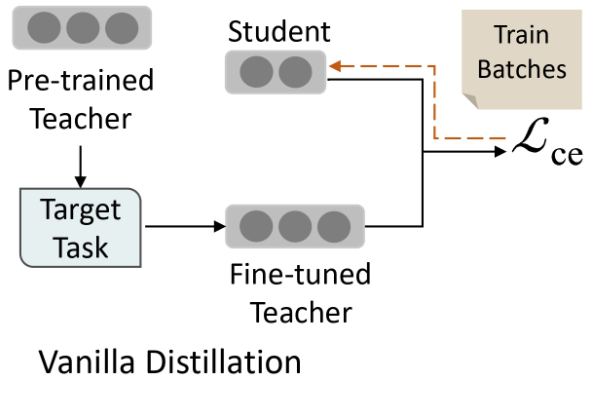
먼저 사전 훈련된 교사 모델을 특정 작업에서 성능을 극대화하도록 미세 조정한다. 교사 모델이 수렴하면 학습 데이터에서 교사 모델의 출력을 가깝게 모방하도록 학생 모델을 훈련한다.
각 미니배치에서 학생 모델의 최적화 목표:
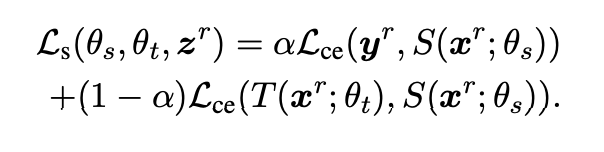
- Ls(θs, θt, z^r): 학생 모델의 손실 함수
- θs: 학생 모델의 가중치
- θt: 교사 모델의 가중치
- zr: 훈련 데이터 배치
- α: 하이퍼파라미터 (두 가지 다른 손실 사이의 가중치를 조절하는 역할)
- α가 0에 가까울수록 교사 모델의 출력을 학생 모델이 더 많이 모방하려고 노력하게 된다.
- Lce(y^r, S(x^r, θs)): 학생 모델의 훈련 데이터 zr에 대한 예측과 실제 레이블 yr 간의 차이를 측정
- 학생 모델이 훈련 데이터에서 정확한 예측을 하도록 노력하게 한다.
- Lce(T(x^r, θt), S(x^r, θs)): 교사 모델의 출력과 학생 모델의 출력 간의 교차 엔트로피 손실
- 학생 모델이 교사 모델의 출력을 모방하려고 노력하게 한다.
💡 따라서 전체 손실 함수 Ls는 학생 모델이 훈련 데이터에서 정확한 예측을 하도록 돕고 동시에 교사 모델의 지식을 학생 모델로 전달하려는 목표를 달성하는 데 사용된다.
α는 이 두 가지 목표 간의 중요도를 조절하는 데 사용되는 매개변수다.
학생의 업데이트는 다음과 같이 이루어진다:
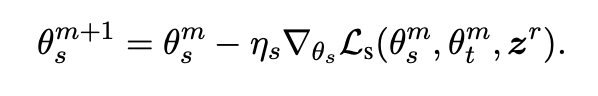
💡 경사 하강법으로 학생 모델의 가중치를 업데이트한다.
- ηs: 학생 모델의 learning rate
- ∇Ls(θs^m, θ^tm, z^r): 손실 함수 Ls에 대한 그래디언트 벡터
바닐라(distillation) 지식 증류의 한계는 교사의 매개변수가 지식 증류 과정 중에 고정되기 때문에 학생의 피드백에 따라 교사의 행동을 조정하는 것을 허용하지 않는다는 것이다.
Online distillation
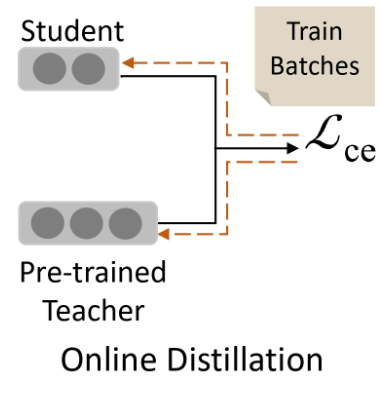
학생을 고려한 지식 증류를 달성하기 위해, 한 단계에서 학생 모델과 교사 모델을 동시에 미세 조정하는 것을 포함한다.
목적 함수 :
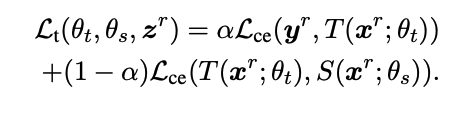
💡 목적 함수는 교사 모델과 학생 모델 간의 지식 전달을 위한 것으로, 아래 두가지를 조합하여 정의된다.
- Lce(y^r, T(x^r;θt)): 교사 모델의 출력과 실제 레이블 간의 손실
- Lce(T(x^r;θt), S(x^r;θs)): 교사 모델과 학생 모델의 출력 간의 손실
- 교사 모델의 대상 분포가 학생 모델의 분포와 유사하게 유지되도록 제약을 둔다.
훈련 과정은 두 모델의 매개변수를 반복적으로 업데이트하는 것을 포함한다:
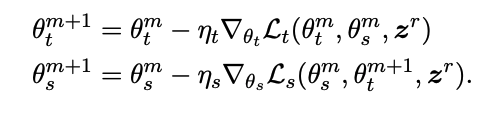
💡 교사 모델의 업데이트된 매개변수 θt^m+1을 곧바로 학생 모델의 업데이트에 사용함으로써, 학생 모델과 교사 모델의 매개변수가 서로에게 영향을 주면서 학습이 동시에 진행된다.
그러나 온라인 증류는 학생 모델이 훈련 데이터에서 교사의 지식을 전달하는 데 중점을 두며, 학생 모델이 보이지 않는 테스트 데이터에서 얼마나 잘 수행할지 명시적으로 고려하지 않는다. 이로 인해 학생 모델이 훈련 예제만 외우고 새로운 예제에 대해 잘 일반화하지 못할 수 있다.
Meta distillation
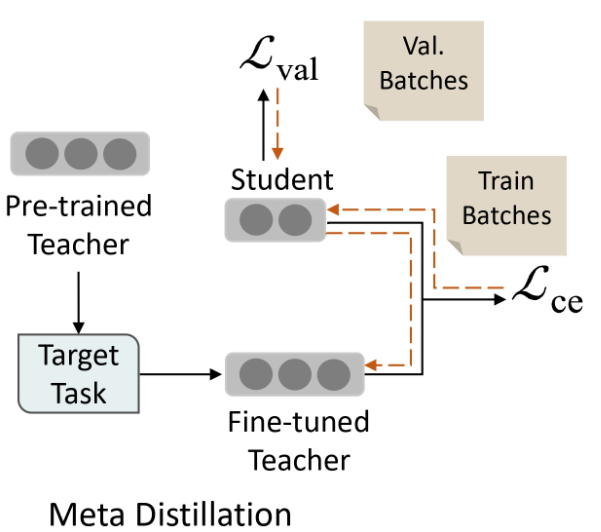
학생 모델의 피드백을 고려하고 교사 모델의 최적화를 이끌어 학생의 일반화 능력을 극대화하는 기술이다.
학생 모델의 목적 함수 :
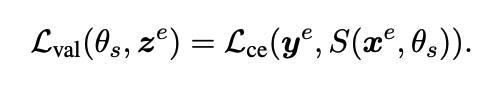
💡 학생 모델의 일반화 오차는 검증 세트에서 학생 모델의 예측과 실제 레이블 간의 교차 엔트로피 손실을 통해 측정된다.
- θs : 학생 모델의 매개변수
- e : 검증
- z^e = (x^e, y^e) : 검증 데이터 집합에 대한 샘플의 배치
- S(x^e, θs) : 학생 모델의 예측
메타 증류는 모델의 학습 과정을 두 단계로 분해한다.
- 바닐라 증류와 유사하게 작업별 데이터에서 좋은 교사 모델을 미세 조정한다.
- 교사 및 학생 모델의 반복적인 업데이트를 포함한다. 온라인 증류와 비교하면 메타 증류는 학생의 피드백을 훈련 데이터가 아닌 검증 데이터에서 얻는다.
학생 모델 업데이트 :
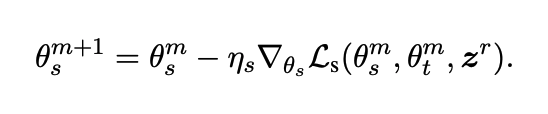
💡 학생 모델은 먼저 지식 증류 손실을 최소화함으로써 표준 증류 프로세스를 통해 업데이트된다.
교사 모델 업데이트 :
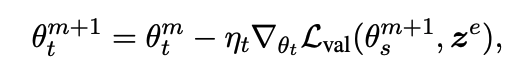
💡 교사 모델은 보류 중인 검증 세트에서 업데이트된 학생의 손실을 최소화하기 위해 최적화된다.
이로써 교사 모델이 학생을 더 나은 일반화로 이끌 수 있도록 보장된다. 이 프로세스 중에 교사는 지식 전달 목적으로만 훈련된다. (학생으로부터만 감독을 받음)
그러나 메타 증류의 최적화 목표는 교사 모델의 성능 저하로 이어질 수 있다. 이는 교사 모델이 학생으로부터만 감독을 받기 때문이다. 이로 인해 교사 모델은 두 번째 단계에서 계속해서 학습하고 개선되지 못하며, 새로운 데이터에 적응하는 능력이 저해될 수 있다.
Learning Good Teacher Matters (LGTM)
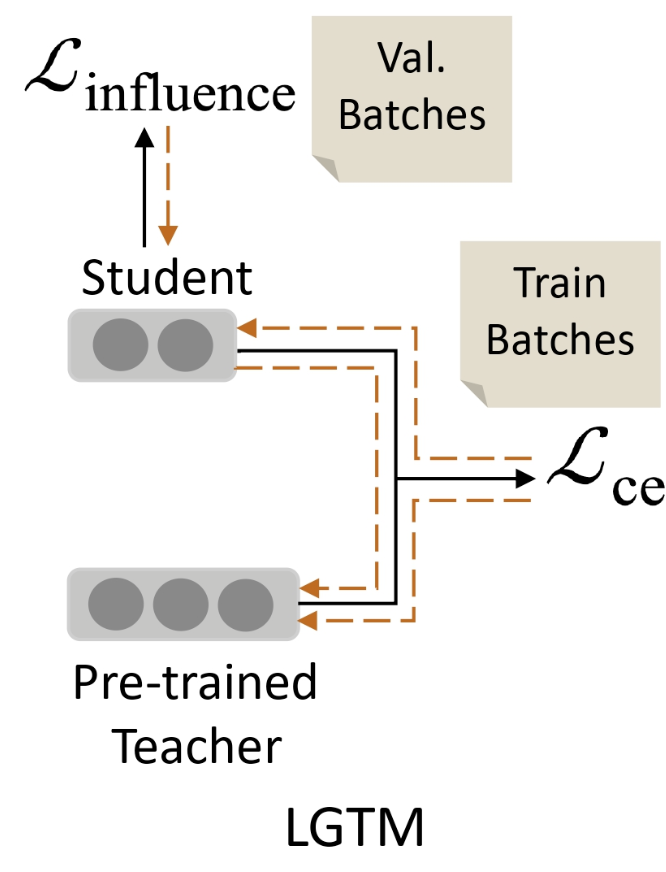
distillation influence
모델의 예측에 대한 훈련 샘플의 영향력을 측정하는 방법이다. 하나의 훈련 샘플을 지식 증류 프로세스에 넣었을 때 학생의 검증 데이터에서의 성능이 얼마나 변경될지를 추정하는 것이다. 모델의 행동에 지나치게 영향을 미치는 경우를 식별하고, 이것이 이상치로 인한 것인지 또는 잘못된 레이블로 인한 것인지 등을 판단하는 데 사용될 수 있다.
학생 모델의 목적 함수 :
Vanilla distillation에서 학생 모델의 경우, 훈련 샘플인 zi^r와 검증 배치인 z^e 사이의 증류 영향을 추출한다.
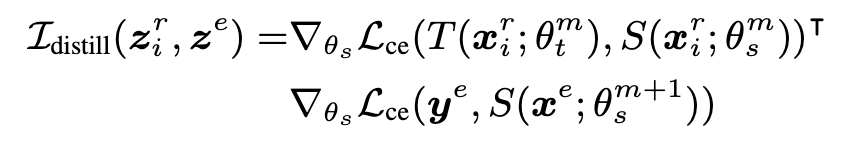
💡 학생 모델이 훈련 샘플과 검증 데이터 사이에서 얼마나 유사한 방식으로 작동하는지를 나타내며, 이는 특정 샘플에서 얻은 지식이 얼마나 일반화되는지를 나타낸다.
따라서, 교사 모델은 학생에게 가장 높은 증류 영향을 가진 훈련 샘플을 포착하도록 하는것에 중점을 둬야 한다.
교사 모델의 목적 함수 :
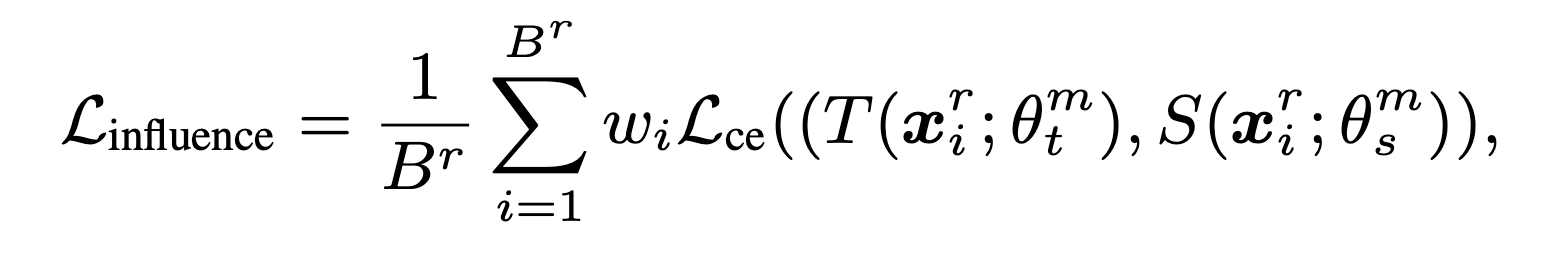
💡 모든 검증 배치에서 계산된 증류 영향과 학생 모델과 교사 모델의 손실의 평균을 의미한다.
앞서 계산한 증류 영향을 가중치 wi로써 사용함으로써 훈련 과정에서 샘플별 영향을 지식 증류에 통합할 수 있다.
- 각 샘플의 상대적 중요성을 결정하고, 각 샘플이 교사의 학습 과정에 얼마나 기여하는지를 제어하는 데 도움이 된다.
- 학생의 일반화에 더 유익한 것으로 판단되는 샘플은 더 높은 가중치가 할당된다.
B : 훈련 샘플의 총 개수
wi : 각 샘플의 증류 영향 = L_distill(zi^r, z^e)
θt^m, θs^m : 해당 시점에서의 교사와 학생 모델의 매개변수
Finite difference approximation
표준 신경망 훈련에서는 종종 Br 개의 훈련 샘플에 대한 미니 배치의 합쳐진 그래디언트를 계산하여 계산 효율성을 향상킨다. 그러나 각 샘플의 디스틸레이션 영향을 결정하는 맥락에서 각 샘플의 그래디언트 Lce(T(xi; θtm), S(xi; θsm)) 계산은 훈련 속도를 Br 배로 늦추게 된다. 또한, 단순한 구현은 메모리를 많이 사용하며 ∇ L (ye, S(xe; θm+1))의 복사본을 유지해야 한다.
이를 해결하기 위해 Finite Difference 를 활용하여 디스틸레이션 영향을 이용한 교사 업데이트의 효율적인 방법을 제안했다. 이는 주어진 지점에서 함수의 도함수를 근사하는 수치해석에서 일반적으로 사용되는 방법이다.
교사 모델의 목적 함수 :
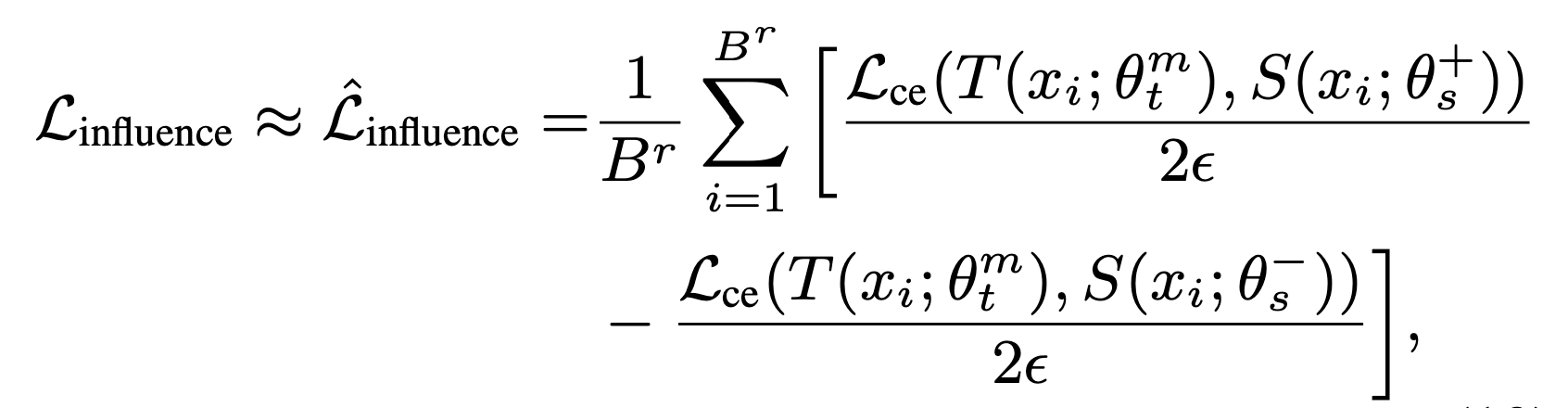
💡 모델의 특정 매개변수를 약간 변화시켰을 때 모델의 출력 손실이 어떻게 변하는지를 추정할 수 있다. 디스틸레이션 과정에서 특정 훈련 샘플이 학습에 어떻게 기여하는지를 이해하는 데 도움을 준다.
θ± : θs+ 또는 θs-로 조절하기 위해 사용
ε : 작은 스칼라 값 (값이 작을수록 매개변수를 미세하게 조정하므로 결과적으로 더 정확한 도함수 근사치를 얻을 수 있다.)
Finite Difference를 평가하는 방법은 계산 효율적이며, 하나의 배치에 대해 θs에 대한 두 번의 전방 패스와 θt에 대한 하나의 역방향 패스만 필요하므로 단순한 구현과 비교하여 효율적이다.
Teacher's auxiliary loss
교사 모델은 학생 모델로의 지식 전달 외에도 자체적으로 어떻게 발전하는지 고려하기 위한 손실을 포함한다. 이는 최종 목표에 대한 보조 손실인 Laux로 통합된다.
교사 모델의 보조 손실 :
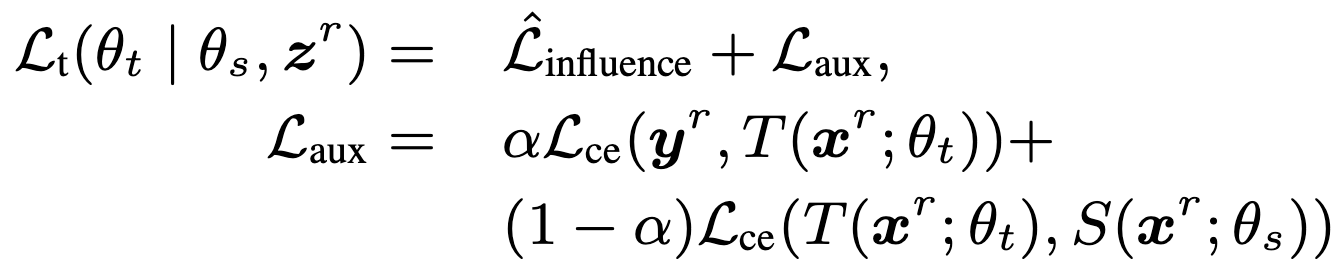
💡 교사 모델의 능력 향상과 학생 모델의 일반화 능력 향상 사이의 균형을 조절한다.
α : 두 손실 사이의 상대적인 가중치를 제어하는 하이퍼파라미터

Relationship with other L2T methods
LGTM의 주요 차이점은 동적 손실 가중치의 사용이다. 이 가중치를 현재 훈련 배치 z^r의 증류 영향을 학생 모델의 일반화 능력에 대한 측정값으로 해석한다. 구체적으로, 이 가중치는 훈련 및 검증 배치의 그래디언트 유사성을 반영하며, 현재 훈련 배치 z^r이 검증 배치 z^e에 미치는 영향을 나타낸다.
그러나 이 가중치는 주로 적응형 학습률로 작동하며, 그래디언트 유사성의 정도에 비례하여 그래디언트 단계를 조정한다.
뒷부분 👉🏻 [논문 읽기 #11] Tailoring Instructions to Student’s Learning Levels Boosts Knowledge Distillation (2)
