
Paper : SCOTT: Self-Consistent Chain-of-Thought Distillation
💡 로 표시된 부분은 제가 이해한 내용을 적은 부분입니다. 오류가 있다면 댓글로 남겨주세요 🙏🏻
Chain-of-Thought
대규모 언어 모델(Large Language Models)은 일정 규모 이상으로 확장될 때, 프롬프트를 통해 예측에 대한 자유로운 텍스트 근거를 생성하는 능력을 나타낸다.
CoT는 뚜렷한 향상된 성능을 제공할 수 있지만, 이러한 이점은 충분히 큰 언어 모델에서만 관찰된다.
생성된 근거가 언어 모델의 예측과 일관성이 있는지 또는 결정을 충실하게 정당화하는지에 대한 보장이 거의 없다.
Self-Consistent Chain-Of-Thought DisTillation
몇 배나 큰 규모의 교사 모델로부터 작은, 자체 일관성을 가진 CoT 모델을 학습하기 위한 지식 증류 방법이다.
더 나은 감독을 형성하기 위해 큰 언어 모델(교사)에서 골드 답변을 지원하는 근거를 강조하기 위해 대조적 디코딩을 통해 근거를 추출한다.
- 답변이 고려될 때에만 더 논리적으로 그럴듯한 토큰을 생성하도록 교사 모델에게 유도
- 제대로 된 지식 증류를 보장하기 위해 교사 모델이 생성한 근거를 사용하여 대조적 추론 목표를 가진 학생 언어 모델을 학습
이렇게 하면 학생 모델이 근거를 무시하고 일관되지 않은 예측을 만드는 것을 방지할 수 있다.
실험 결과, 기존의 기준 모델들보다 더 충실한 CoT 근거를 생성할 수 있음을 보여준다. 더 나아가 이러한 모델은 결정을 내릴 때 근거를 더 존중하는 경향이 있으므로 근거를 개선함으로써 성능을 더 향상시킬 수 있다.
기존 연구
: 주로 컴퓨팅 효율성 또는 작업 성능을 위해 대규모 언어 모델(LMs)에서 추론 학습을 제안한다.
대규모 언어 모델(교사)에게 하류 데이터셋을 위한 근거를 생성하도록 유도하며, 이 근거를 사용하여 작은 언어 모델(학생)을 훈련시킨다.
문제점
- 언어 모델은 입력에 근거하지 않은 텍스트를 생성하는 경향이 있다. 따라서 교사 모델은 종종 주제와 관련 없는 근거를 생성할 수 있으며, 이 근거가 답변을 완전히 지원하지 못할 수 있다. 이 근거와 답변 사이의 이러한 일관성 부족은 학생 모델에게 상속될 것이다.
- 학생 모델은 근거 생성과 답변 예측을 두 개의 독립적인 프로세스로 취급할 수 있다. 이것은 질문과 답변 사이의 가짜 상관 관계로 인해 발생한다.
두 가지 문제가 함께 작용하면 학생이 허구의 근거를 생성하고 근거와 일치하지 않는 예측을 할 수 있게 된다.
해결방안
일반적인 지식 증류(Knowledge Distillation, KD) 과정을 강화한다.
- 대조적 디코딩
- 교사 모델로부터 주제와 관련된 일관된 근거를 더 유도하기 위함.
- 각 근거를 답변과 연결시키는 것을 목표로 하며, 답변이 고려될 때만 더 그럴듯한 토큰을 생성하도록 교사 모델을 유도한다.
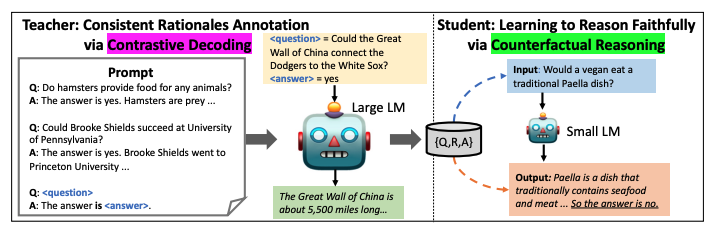
골드답변(정답에 가까운, 미리 준비된 답변)과 모델이 생성한 답변을 대조한다.
- 반대사실적 추론
-
충실한 학생을 훈련시키기 위해, 근거가 다른 답변으로 이끄는 경우에 따라 예측하도록 요청한다.
-
훈련 데이터는 교사 모델에게 잘못된 답변에 대한 근거를 생성하도록 요청하여 얻는다.
- 입력 : 채식주의자라면 전통적인 파에야 요리를 먹을까요?
- 산출물 :
- 근거 : 파에야는 전통적으로 해산물과 고기를 넣은 음식입니다...
- 예측 : 그래서 답은 아니오입니다.
-
실험 결과
대조적 디코딩
- 일관된 교사 모델
- 골드 답변을 더 지원하는 근거를 생성
일관된 근거-답변 쌍으로 훈련된 학생
- 답변 예측과 근거 생성을 더 잘 연관시킴
부가적인 훈련 목표로 반대사실적 추론 사용
- 학생 모델은 추론 단축키를 사용하지 않고 근거를 더 존중
충실성이 높아진 모델
- 기준 모델과 비교하여 유사한 성능을 발휘
- 학생 모델의 크기와 관계없이 불일치를 효과적으로 해결
Chain-of-Thought Distillation
-
큰 규모의 언어 모델로부터 골드 답변을 제대로 정당화하는 일관된 근거를 유도하는 것을 감독으로 삼고,
-
스스로 일관된 학생 모델을 훈련시켜 그 근거에 따라 충실하게 추론하게 한다.
작업 입력에 필요한 지식이 제공되지 않는 개방형 도메인에서 질문 응답(QA) 작업을 수행했다.
-
given a question : q
-
the gold answer (a QA system is asked to predict): a∗
-
free-text rationale (justifies its prediction) : r
💡 "작업 입력에 필요한 지식이 제공되지 않는"
: 교사 모델이 문제 해결 작업을 위해 필요한 정보나 지식이 질문(입력) 자체에 명시적으로 포함되어 있지 않다는 의미다.
작업 입력에 필요한 정보나 지식이 명시적으로 주어지지 않을 때, 교사 모델은 질문과 정답을 기반으로 근거를 생성하고, 이 근거를 사용하여 정답을 정당화하고 추론을 수행하는 방법을 학습할 수 있다.
💡 "개방형 도메인"
: 다양한 주제, 분야, 주제 영역을 다룰 수 있는 범용성을 의미한다. 이는 모델이나 시스템이 특정 분야나 작업에 제한되지 않고 다양한 작업을 수행할 수 있는 능력이다.
Generating Rationale Annotation
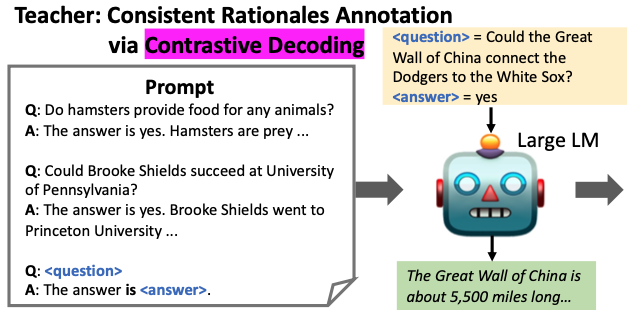
각 질문-답변 쌍 {q, a∗}에 대해 인간들에게 근거를 주석으로 달라고 요청하는 대신, 문맥 내 학습을 사용하여 교사 모델에서 근거를 자동으로 얻는다.
새로운 인스턴스가 제공되기 전에 몇 가지 주석 예제로 교사로 동결된 언어 모델에 프롬프트를 보내는 것이다.
Train dataset 예제
- prompt : p
- question (randomly sampled from the training set) : q
- gold answer : a∗
- human-annotated rationale (justifies why a∗ is correct) : r
새로운 질문 q에 대한 근거를 얻기 위한 하나의 기본 전략은 탐욕 디코딩(greedy decoding) 으로, 이는 각 단계에서 가장 그럴듯한 토큰을 선택한다:
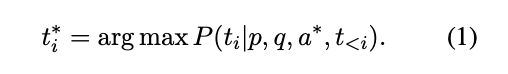
💡 현재 위치 i 이전의 모든 토큰(t<i)과 주어진 문맥(p, q, a∗)에 대해 가장 그럴듯한 근거 토큰 ti를 선택하는 것을 의미한다.
- 문맥 내 학습
- 탐욕 디코딩
Training a Student Model
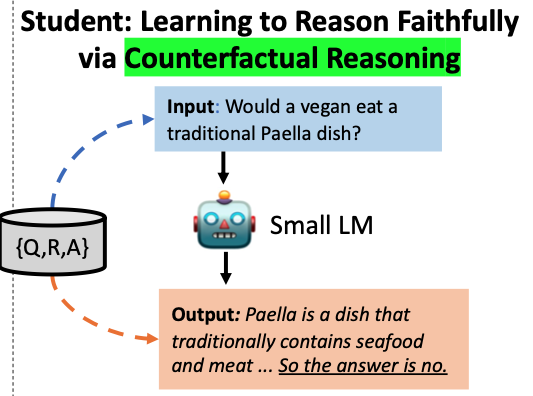
이제 주석이 달린 훈련 데이터 {q, r, a∗}로, 더 작은 모델을 훈련시킬 수 있다.
예측을 수행하고 근거를 생성할 수 있는 QA 모델을 구현하는 다양한 방법이 있다. 본 연구에서는 "self-rationalization" 패러다임에 중점을 둔다.
- self-rationalization : 학생이 먼저 근거를 생성한 다음 생성된 근거를 기반으로 답변을 예측
아래 두 패러다임에서 근거 생성은 처음부터 의사결정에 영향을 미치지 않으며, 따라서 근거의 충실성이 먼저 보장되지 않는다.
- post-rationalization : 답변 예측 후에 근거를 생성
- multi-task learning : 근거 생성을 답변 예측 외에 부수적인 작업으로 다룸
주어진 질문 q에 대해, 학생 모델은 근거 토큰의 시퀀스를 생성하도록 훈련되며, 이는 답변 토큰과 concatenated되어 위 그림에 나타난 대로 표시된다.
💡 직관적인 구현 방법은 교사 모델이 일반적인 언어 모델링 손실을 사용하여 생성한 실버 훈련 데이터를 활용하여 텍스트-텍스트 언어 모델을 미세 조정하는 것이다.
factual reasoning loss :
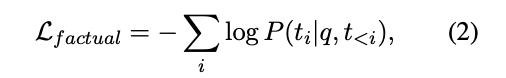
Distilling a Self-Consistent Student
Vanilla Knowledge Distilation 프로세스의 두 가지 문제
1. 환영증상(hallucination) 문제
신경망 언어 모델이 입력과 관련이 없는 텍스트를 생성한다는 것을 의미한다. 이로 인해 생성된 근거가 주어진 답변을 뒷받침하지 않게 된다. 근거와 답변 사이의 불일치는 학생 모델에게 전해질 것이며, 학생 모델은 답변 예측이 근거 생성과 독립적이라고 오해하게 된다.
2. Reasoning Shortcut
학생 모델은 근거 생성을 고려하지 않고 추론 단축키를 학습하게 된다. 이것은 질문과 답변 사이의 의도하지 않은 상관 관계로 인해 발생하며, 이러한 상관 관계는 다양한 내재 추론 작업 데이터셋에서 발견된다.
위 두 가지 문제는 생성된 근거가 답변을 일관되게 정당화하지 못하는 신뢰할 수 없는 학생 모델을 결과로 낼 수 있다. 이를 완화하기 위해 아래에서 두 가지 기술을 제안한다.
A Consistent Teacher: Contrastive Decoding
대조적 디코딩은 답변을 뒷받침하는 이론적 근거를 생성하도록 교사 모델을 격려하기 위해 제안된 방법이다. 핵심 아이디어는 디코딩 중에 답변이 고려될 때 더 타당한 근거 토큰을 찾는 것이다.
이 아이디어를 구현하기 위해, 먼저 답변 a'를 동일한 교사 모델에게 제공해 나타나는 hallucination을 모델링한다. 그런 다음 답 a∗가 주어지면 토큰 ti의 타당성 증가율 G를 다음과 같이 구할 수 있다.
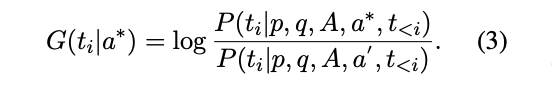
💡 골드 답변 a∗을 고려할 때와 hallucinated 답변을 고려할 때의 토큰 ti의 가능성 비율 측정을 통해 해당 토큰의 타당성 증가율을 구할 수 있다.
P(ti | p, q, A, a∗, t<i)
: 답변 a∗를 고려할 때 토큰 ti의 가능성
P(ti | p, q, A, a', t<i)
: hallucinated 답변 a'를 고려할 때 토큰 ti의 가능성
답변을 혼란스럽게 만드는 두 가지 방법:
-
a'를 빈 문자열로 설정하는 방법
- 골드 답변 a∗가 고려되지 않을 때 일반적으로 타당한 토큰을 혼란스러운 Language Model (LM)에 의해 생성하는 것을 처벌한다.
-
a∗ 이외의 잘못된 답변으로 설정하는 방법
- 잘못된 답변으로 설정하는 방법은 교사 모델이 골드 답변과 잘못된 답변 사이에서 더 명확하게 근거를 생성하도록 격려한다.
- 잘못된 답변으로 설정하는 방법은 교사 모델이 골드 답변과 잘못된 답변 사이에서 더 명확하게 근거를 생성하도록 격려한다.

위 그림은 탐욕 디코딩과 대조 디코딩을 사용하여 예제 질문에 대한 생성 결과를 보여준다.
Greedy Decoding :
- 등은 몸의 일부분이다.
- 등은 과일이 아니다.
- 따라서 허리가 아픈 사람은 딸기 따는 것을 좋아하지 않을 것이다.
Contrastive Decoding :
-
<perturved_answer> = 빈 문자열
- 육체노동은 요통을 유발할 수 있다.
- 따라서, 요통이 있는 사람은 딸기 따는 것을 좋아하지 않을 것이다.
-
<perturved_answer> = 그렇다
- 몸을 지탱하기 위해서는 척추가 필요하다.
- 허리가 아프면 딸기를 딸 수 없을 것이다.
언어 유창성과 근거의 타당성 간의 균형을 맞추기 위해 최종 대조 디코딩 전략에서 타당성 증가를 추가한다:
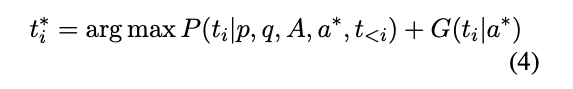
💡 ti∗는 주어진 문맥 (p, q, A, a∗) 및 현재 위치 이전의 토큰에서 가장 가능성이 높은 근거 토큰이다.
P(ti | p, q, A, a∗, t<i)
: 답변 a∗를 고려할 때 토큰 ti의 가능성
G(ti | a∗)
: 답 a∗가 주어졌을 때, 토큰 ti의 타당성 증가율
A Faithful Student: Counterfactual Reasoning
대조적 추론을 실시함으로써 학생 모델에게 동일한 질문에 대해 다르게 답하도록 요청하므로 논리적 단축키가 제거된다.
이 아이디어를 구현하기 위해 먼저 방정식 (4)에서 교사 모델에게 주어진 골드 답변을 잘못된 답변 a'로 대체한다. 따라서 오답 a'로 이어지는 반사실적 근거 r'을 얻게 된다.
그런 다음 반사실적 근거 r'가 입력일 때, a'를 생성하도록 하는 디코더 모델을 훈련한다. (언어 모델링 손실은 응답 토큰 ti ∈ a'에만 적용된다)
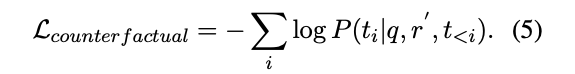
💡 반대 사실적 추론을 수행하는 학생 모델의 훈련하는 데 사용되는 손실함수다.
학생 모델이 근거에 따라 진술하는 것과 상반된 답을 생각하고 이에 대응하는 추론을 수행하도록 유도한다.
- 근거와 질문 사이의 추론 단축키를 제거
- 동일한 질문에 대해 다르게 답하도록 도움
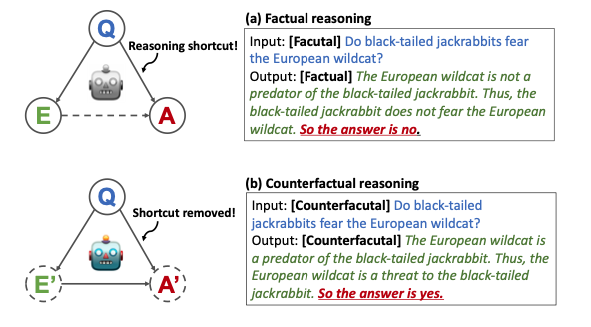
학생 모델이 과업에 대해 혼동하는 것을 방지하기 위해 학습 목표를 학생에게 알리기 위해 인코더에 입력 시퀀스와 디코더의 출력 시퀸스의 시작 부분에 [Factual] 또는 [Counterfactual]라는 키워드를 추가하여 학습 목표를 학생 모델에게 표시한다.
전체 학습 손실은 Eq.2 (factual loss)와 Eq.5 (counterfactual loss)의 합이다.
(a) 사실적 추론
-
입력 : 토끼는 삵을 무서워하는가?
-
출력 :
- 삵은 토끼의 포식자가 아니다.
- 따라서, 토끼는 삵을 두려워하지 않는다.
- 그래서 답은 '아니오'다.
이 경우 Q (입력) 과 A (아니오) 사이에 추론 단축키가 생성된다.
(b) 반사실적 추론
-
입력 : 토끼는 삵을 무서워하는가?
-
출력 :
- 삵은 토끼의 포식자다.
- 따라서, 삵은 토끼에게 위협적인 존재다.
- 그래서 답은 '그렇다'이다.
반대사실적 추론을 부가적인 훈련 목표로 사용하여 학생 모델이 추론 단축키를 사용하지 않고 근거를 더 존중할 수 있도록 한다.
Experiments
실험에서 다음과 같은 연구 질문에 대답하기를 목표로 한다 :
- 대조 디코딩 전략이 더 일관된 교사 모델을 얻게 할 수 있을까?
- 더 일관된 교사 모델과 반대사실적 추론 목표는 더 충실하게 추론하는 학생을 얻게 할 수 있을까?
- 자체 일관성 있는 학생 모델의 예측을 생성된 근거를 수정함으로써 더욱 효과적으로 조절할 수 있을까?
Conclusion
이 연구는 큰 교사 모델에서 작고, 스스로 일관된 CoT 모델을 학습하기 위한 지식 증류(KD) 프레임워크를 제시한다.
학생 모델이 충실하게 추론하도록 하기 위해 다음을 제안한다.
- 일관된 교사 모델을 얻기 위한 대조 디코딩
- 충실한 학생을 가르치기 위한 반대사실적 추론
실험 결과, 이 두 기술이 기준선에 비해 더 충실한 학생을 이끌어내는 것을 보여주며, 성능 정확도를 크게 유지한다.
추가적인 분석으로, 근거를 변경하면 학생 모델의 행동에 더 큰 영향을 미친다. 따라서 근거를 개선함으로써 모델을 디버깅하는 데 더 큰 성공을 거둘 수 있다는 것을 보여준다.
Limitations
일반적인 지식 증류 과정과 비교하여 학습 데이터를 준비하고 학생을 훈련하는 데 추가 계산이 필요하다.
-
대조적 디코딩은 각 생성된 토큰에 대한 변조된 타당성을 얻기 위해, 그리디 디코딩보다 교사 모델에서 한 번 더 전방 향 전파를 수행해야 한다. (Eq. 4)
-
지식 증류 과정은 반대사실적 추론 목표로 학생을 훈련하기 위한 추가적인 훈련 데이터를 도입한다. (Eq. 5)
계산 비용 이외에도 이 연구는 성능 향상이 아닌 근거의 충실성을 개선하는 데 중점을 두고 있으며, 이는 이전 연구와 보완적인 방법으로 근거를 사용하여 성능을 개선하는 것을 고려할 수 있다.
