Github : https://github.com/huggingface/transformers/tree/main/examples/research_projects/movement-pruning
Paper : https://arxiv.org/abs/2005.07683
💡 로 표시된 부분은 제가 이해한 내용을 적은 부분입니다. 오류가 있다면 댓글로 남겨주세요 🙏🏻
Abstract
Magnitude pruning은 순수 지도 학습에서 모델 크기를 줄이는 데에 널리 사용되는 전략이다. 그러나 이는 최첨단 자연어 처리 응용에서 표준이 된 전이 학습 환경에서는 효과가 덜한데, 이는 이후에 설명할 movement pruning에 비해 덜 적응적이다.
본 논문에서는 movement pruning을 사용하는 것을 제안한다. 이는 단순하면서도 결정론적인 1차 가중치 절단 방법으로, 미세 조정된 사전 훈련 모델에 더 적응적이다. 이 방법에 대한 수학적 기초를 제시하고, 기존의 0차 및 1차 가중치 절단 방법과 비교한다.
실험 결과는 큰 사전 훈련 언어 모델을 절단할 때, movement pruning이 높은 희소성 범위에서 상당한 향상을 보인다는 것을 보여준다. 이 방법을 증류와 결합할 경우, 이 접근 방식은 모델 파라미터의 단 3%까지만 사용하여 최소한의 정확도 손실을 달성한다.
1. Introduction
Large-scale transfer learning은 딥러닝에서 널리 사용되며, 자연어 처리 및 관련 분야의 응용에서 state-of-the-art 성능을 달성한다. 이 설정에서 대규모 모델은 거대한 일반 데이터셋에서 사전 훈련된 후 작은 주석이 달린 데이터셋에서 특정 end-task를 수행하기 위해 미세 조정된다.
모델 정확도는 사전 훈련된 모델 및 데이터셋 크기와 비례하여 증가한다는 것이 보여졌다. 그러나 이러한 대규모 모델을 출시하고 배포하려면 상당한 자원이 필요하며, 이러한 모델을 훈련하는 데는 높은 환경적인 비용이 발생한다.
Transfer Learning
: 관련된 작업에 대한 성능을 향상시키기 위해 작업으로부터 학습된 지식을 재사용하는 기술
출처 : https://en.wikipedia.org/wiki/Transfer_learning
희소성 도입은 신경망의 메모리를 효율적으로 사용하기 위해 널리 사용되는 방법 중 하나로, 정확도 손실이 거의 없는 상태에서 수행된다. 가중치의 중요도에 따라 가중치를 제거하는 가지 치기(pruning) 방법은 모델을 압축하는 특히 간단하고 효과적인 방법이다.
작은 모델은 모바일 폰과 같은 엣지 디바이스에 전송하기 쉽지만 에너지 소비가 훨씬 적다. 에너지 소비의 대다수는 모바일 디바이스의 장기 저장소에서 모델 파라미터를 해당 디바이스의 휘발성 메모리로 가져오는 과정에서 발생한다.
magnitude pruning은 높은 절대값을 가진 가중치를 보존하는 방법으로, 가중치 절단을 위해 가장 널리 사용되는 방법 중 하나다. 이는 컴퓨터 비전, 언어 처리 및 최근에는 복권 티켓 가설의 핵심 구성 요소로 활용되었다. 그러나 magnitude pruning은 표준 지도 학습에서는 매우 효과적이지만, 전이 학습 환경에서는 본질적으로 유용하지 않다.
-
지도 학습에서 가중치 값은 주로 최종 작업 훈련 데이터에 의해 결정된다.
-
전이 학습에서 가중치 값은 주로 원래 모델에 의해 미리 결정되며 최종 작업에서만 미세 조정된다.
이로 인해 이러한 방법이 미세 조정 단계 또는 fine-pruning에 기반한 가중치 절단을 학습하는 것이 방해된다.
💡 Magnitude pruning은 가중치의 절대값만을 고려하므로, 전이 학습에서는 모델이 특정 작업에 맞게 미세 조정되는 과정에서 적절한 가중치를 식별하는 데에 한계가 있다.
즉, 최종 작업에 특화된 정보를 제대로 활용하지 못하게 되어 성능 향상이 어렵다. 따라서 전이 학습에서는 "fine-pruning"이 어렵다고 설명되고 있다.
본 논문에서는 transfer learning을 위해 모델 크기를 효과적으로 줄이려면 대신 movement pruning을 사용해야 한다고 주장한다. 즉, 미세 조정 중에 가중치의 변화를 고려하는 절단 방법이다. movement pruning은 magnitude pruning과 달리 훈련 중에 크기가 작아지는 경우 낮은 값과 높은 값의 가중치를 모두 절단할 수 있다.
이 방법은 선택 기준을 0차에서 1차로 이동시켜 미세 조정 목표에 기반한 효과적인 pruning을 가능하게 한다. 이 접근 방식을 테스트하기 위해 movement pruning의 간단하면서도 결정론적인 버전인 straight-through estimator를 활용했다.
💡 "선택 기준을 0차에서 1차로 이동시킨다"
"차수"는 정보가 고려되는 정도를 나타낸다.
- 0차 : 일반적으로는 절댓값이나 크기와 같은 저차원 정보를 나타낸다. 이는 가중치의 크기 자체를 고려하는 것이다.
- 1차 : 이는 더 높은 차원의 정보, 즉 가중치의 변화나 움직임을 나타낸다. 더 높은 차원의 정보를 고려함으로써 가중치의 미세한 조정이나 변화를 둘러싼 상황을 고려할 수 있다.
따라서 가중치의 크기를 주로 고려했던 선택 기준을, 가중치의 움직임이나 변화에 좀 더 민감한 1차원 정보를 고려하는 방향으로 조정한다는 것을 의미한다. 이는 가중치의 미세한 조정에 민감하게 반응하면서도 효과적인 가중치 pruning을 가능하도록 한다.
straight-through estimator
: 마지막 레이어에서 구해진 그래디언트를 back propagation시에 그대로 전파해주는 것을 말한다.
출처: https://dhhwang89.tistory.com/134
movement pruning을 사전 훈련된 BERT에 적용하여 다양한 미세 조정 작업에 대한 결과를 관찰했다. 매우 희소한 범위에서(남은 가중치의 15% 미만), magnitude pruning 및 L0 정규화와 같은 다른 1차 방법과 비교하여 상당한 향상을 관찰했다.
모델은 자연어 추론 (MNLI) 및 질문 응답 (SQuAD v1.1) 에서 원래 BERT 성능의 95%를 달성했다. magnitude pruning과 movement pruning 간의 차이를 분석한 결과, 두 방법은 movement pruning이 최종 작업에 더 잘 적응할 수 있는 능력을 더 크게 보여줬다.
2. Related Work
magnitude pruning 이외에도 일반적인 모델 가중치 절단을 위한 다양한 방법들이 존재한다.
Parallel score matrices to augment the weight matrices
가중치 행렬을 보강하기 위해 병렬 점수 행렬을 사용하는 것은 본 논문의 접근 방식과 가장 유사한 방법이다. 이는 합성곱 네트워크에 적용된 적이 있다.
하지만 이 방법은 모델의 가중치를 고정하고 점수를 업데이트하여 좋은 희소한 서브네트워크를 찾는 방식으로 동작하며, 본 논문의 방법과는 다르다.
Using higher-order information to select prunable weights
이전 연구들 중 많은 작업에서는 pruning 가능한 가중치를 선택하기 위해 상위의 정보를 사용해왔다.
-
손실의 헤시안을 활용하여 삭제할 가중치를 선택하는 방법이다. 본 논문의 방법은 중요도 점수가 표준 미세 조정의 부산물로 얻어지기 때문에 비용이 많이 드는 2차 도함수의 계산을 필요로하지 않는다.
-
기울기의 절대값이나 제곱값을 사용하는 방법 또한 제안되었다. 이에 반해 본 논문에서는 알고리즘에서 움직임의 방향을 보존하는 것이 유용하다는 것을 발견했다.
Compressing pretrained language models
전이 학습을 위해 사전 훈련된 언어 모델을 압축하는 것은 연구 분야에서 인기 있다. 다른 접근 방식에는 knowledge distillation 및 structured pruning 등이 포함된다.
본 논문의 핵심 방법은 외부 교사 모델이 필요하지 않으며 개별 가중치를 대상으로 한다. 또한 교사가 있다면 접근 방식을 더 개선할 수 있음을 보여준다.
iterative magnitude pruning with rewinding, weight redistribution
최근의 연구는 반복적인 크기기반 가지치기를 반복하는 방식, 가중치 재배치 및 모델을 처음부터 다시 만드는 방식들이 있다.
이는 본 논문의 (미세 조정 단계에 중점을 둔) 전이 학습의 맥락에서 프레임을 구성하는 방식과는 다르다.
Quantization
양자화는 다양한 최신 대규모 아키텍처에 적용되어 높은 메모리 압축 비율을 제공하지만 성능 손실이 거의 없다.
이전 연구에서 보여주듯이 양자화와 pruning은 상호 보완적이며 성능/크기 비율을 더 개선하기 위해 결합될 수 있다.
3. Background: Score-Based Pruning
먼저 다양한 신경망 가지치기 전략을 논의하기 위한 표기법을 정립한다.
-
W ∈ R^n×n : 일반적인 모델의 가중치 행렬 (정방 행렬을 고려하지만 어떤 모양이든 될 수 있다)
-
S ∈ R^n×n : 관련된 중요도 점수의 병렬 행렬
-
M ∈ {0, 1}^n×n : 마스크
-
a = (W ⊙ M)x : 입력 x에 대한 추론
-
Topv : S에서 v%의 최상위 값을 선택하는 함수
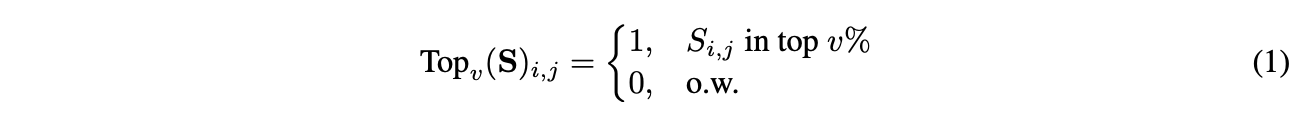
크기 기반의 가중치 가지치기는 중요도의 척도로서 각 가중치의 절대값에 기초하여 마스크를 결정한다.
-
S = |W_{i,j}| (1 ≤ i,j ≤ n) : 중요도 점수 S
-
M = Topv(S) : 마스크 (식 (1))
이 기본 설정에는 여러 확장이 있다.
-
iterative magnitude pruning :
모델은 먼저 수렴할 때까지 훈련되고 가장 낮은 크기의 가중치가 제거된다. 그런 다음 제거된 가중치를 0으로 고정한 채로 희소화된 모델을 다시 훈련한다. 이 루프는 원하는 희소 수준에 도달할 때까지 반복된다.
-
automated gradual pruning :
본 논문에서 중점을 둔 방법이다.- 가지치기된 모델 업데이트 : 마스크가 적용된 가중치가 훈련 전체 기간 동안 업데이트 되도록 허용함으로써 magnitude pruning을 보완한다. 이는 모델이 이전 마스킹 선택에서 회복될 수 있도록 한다.
- 점진적인 희소성 레벨 증가 : cubic sparsity scheduler를 이용하여 훈련 중에 sparsity 수준 v를 점진적으로 증가시킬 수 있다. 초기 값 v_i에서 N 단계의 웜업 이후에 최종 값 v_f까지 n 가지치기 단계 동안 희소성 수준이 증가한다.
따라서 모델은 공동으로 가지치기와 훈련이 이루어진다.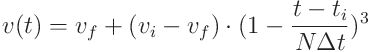 v(t) : t 단계에서의 sparsity 수준.
v(t) : t 단계에서의 sparsity 수준.
- 가지치기된 모델 업데이트 : 마스크가 적용된 가중치가 훈련 전체 기간 동안 업데이트 되도록 허용함으로써 magnitude pruning을 보완한다. 이는 모델이 이전 마스킹 선택에서 회복될 수 있도록 한다.
4. Movement Pruning
magnitude pruning은 실행중인 모델의 0차 정보(절대값)를 활용하는 것으로 볼 수 있다. 본 논문에서는 1차 정보에서 중요도를 도출하는 movement pruning에 중점을 둔다. 직관적으로 0에서 멀리 떨어진 가중치를 선택하는 대신 훈련 과정 중 0에서 멀어지는 연결을 유지한다.
두 가지 버전의 movement pruning을 고려한다:
1. hard
magnitude pruning과는 달리 훈련 중에 가중치 W와 중요도 점수 S를 모두 학습한다. Topv 함수를 사용하여 마스크를 계산한다:
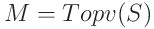
순방향 패스에서 모든 i에 대해 a_i를 계산한다:
Topv의 기울기가 정의된 모든 위치에서 0이기 때문에, straight-through estimator로 값을 근사화한다. 역방향 패스에서는 Topv가 무시되고 기울기가 "straight-through"하여 S로 이동한다. 손실 L에 대한 S_i,j의 기울기 근사치는 다음과 같다:
이는 순방향 패스에서 가중치가 마스크로 가려져 있더라도 가중치의 점수가 업데이트된다는 것을 의미한다.
2. soft
이진 마스크 함수를 기반으로 한 완화된 movement pruning도 고려한다. 여기서는 하이퍼파라미터 v를 고정된 전역 임계값 τ로 대체하여 이진 마스크를 제어한다. 마스크는 다음과 같이 계산된다:
희소성 수준을 제어하기 위해 중요도 점수가 시간이 지남에 따라 감소하도록 장려하는 정규화 항을 추가한다:
여기서 계수 lambda_mvp는 패널티 강도와 따라서 희소성 수준을 제어한다.
Method Interpretation
movement pruning에서 L에 대한 W_i,j의 기울기는 표준 기울기 도출에 따라 다음과 같다:
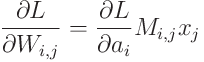
이것을 식 (2)에 결합하면 다음과 같다(간결함을 위해 이진 마스크 항 M_{i,j}을 생략):
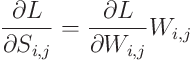
식 (2)의 기울기 업데이트에서 다음과 같을 때, 즉 두 가지 경우에서 발생한다:
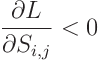
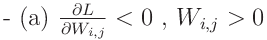
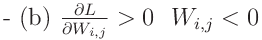
훈련 중에 W_i,j가 양수인 동안 증가하거나, 음수인 동안 감소한다. 이는 W_i,j가 0에서 멀어지는 경우 S_i,j가 증가한다는 것을 의미한다. 역으로, dL/dS_i,j > 0일 때 S_i,j가 감소하며, 이는 W_i,j가 0으로 수축하는 것을 의미한다.
magnitude pruning이 0과의 거리 |W_i,j|를 최대화하는 가장 중요한 가중치를 선택하는 반면, movement pruning은 0에서 가장 멀어지는 가중치 S_i,j를 선택한다.
이러한 이유로 magnitude pruning은 0차 방법으로 볼 수 있으며, movement pruning은 1차 신호에 기반한다. 실제로, S는 움직임의 누적으로 볼 수 있다.
식 (2)에 따르면 T 번의 기울기 업데이트 후에는 다음과 같다:
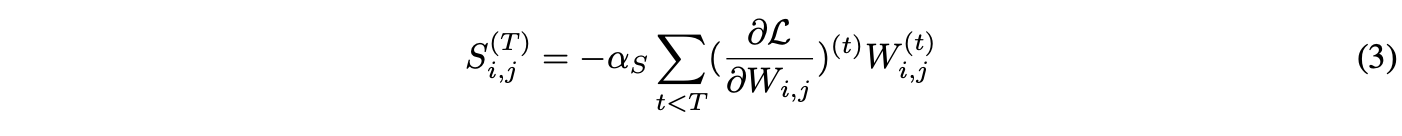
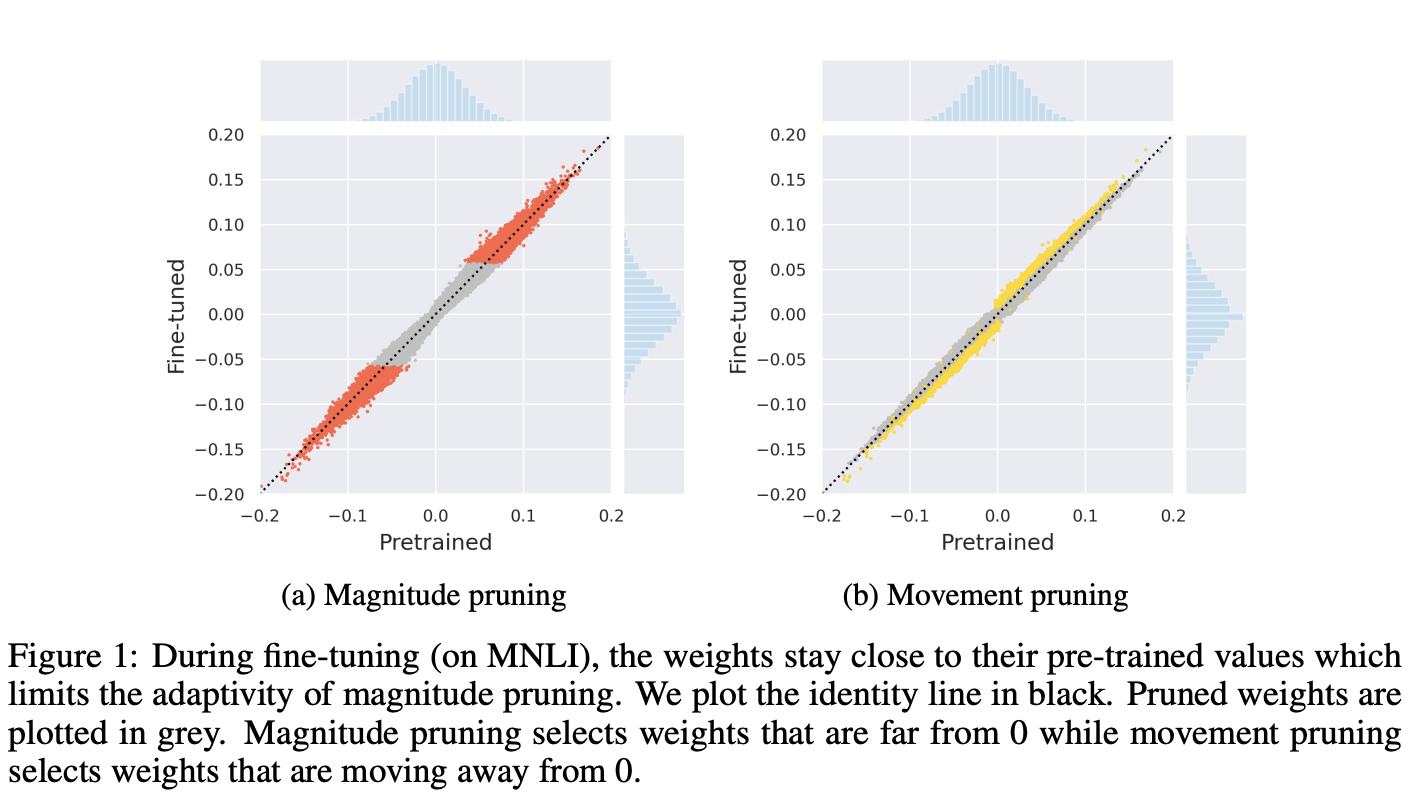
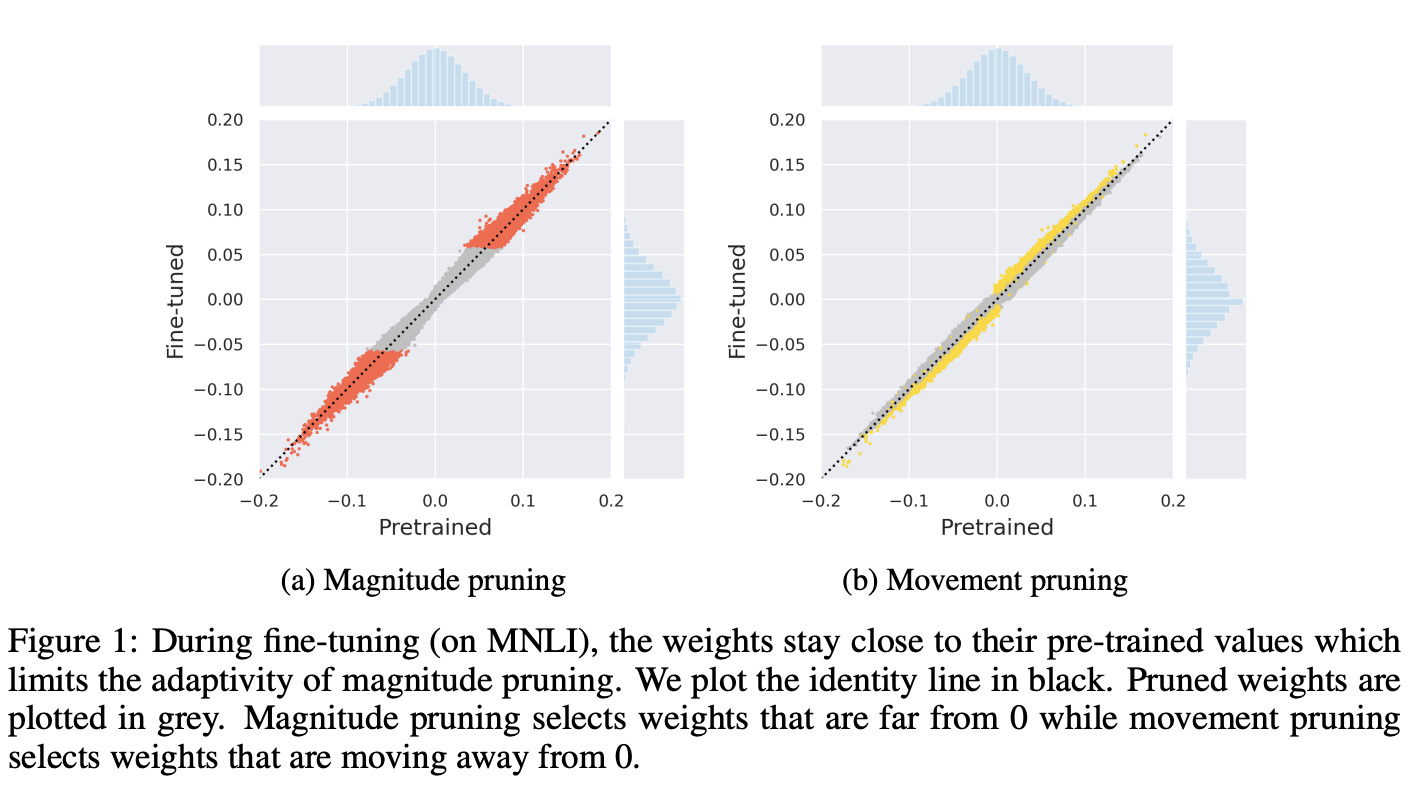
Figure 1은 이 차이를 실험적으로 나타내며, fine-tuning 중에 가중치 값과 사전 훈련된 값 간의 비교를 보여준다. fine-tuned된 가중치는 초기 사전 훈련된 값과 절대값으로 비교했을 때 근접하다.
-
magnitude pruning의 경우, 초기 사전 훈련된 값 주변의 안정성은 사전 훈련된 값에서 가장 작은 절대값을 갖는 가중치가 작아진 채로 절단될 가능성이 높기 때문에 fine-tuning이 시작되기 전에 이미 이를 높은 신뢰도로 알 수 있음을 의미한다.
-
movement pruning에서는 사전 훈련된 가중치가 이러한 pruning 결정에 대한 인식을 갖지 않는다. 선택은 fine-tuning 중에 이루어지며(0에서 멀어지면서), 낮은 값뿐만 아니라 높은 값도 절단될 수 있기 때문이다. 이는 과제별 데이터를 기반으로 절단할 수 있기 때문에 중요하다.
L0 Regularization
마지막으로, movement pruning은 또 다른 움직임 기반 pruning 접근 방법인 L0 regularization based pruning과 유사한 업데이트를 제공한다.
L0는 hard-concrete 분포를 사용하며 하이퍼파라미터 b > 0, l < 0, 및 r > 1을 사용하여 모든 i, j에 대해 마스크 M을 샘플링한다:
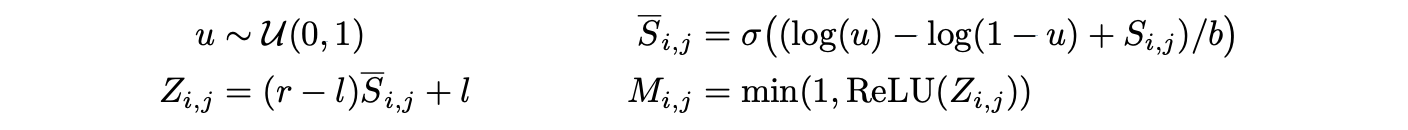
L0 노름의 기대값은 hard-concrete의 매개변수를 포함하는 닫힌 형태를 가지며 다음과 같다:
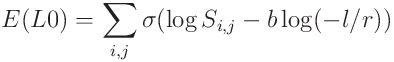
따라서 모델의 가중치 및 점수는 훈련 손실 L과 예상된 L0 패널티의 합을 최소화하도록 end-to-end로 최적화될 수 있다. 계수 lambda_l0는 L0 패널티 및 간접적으로 희소성 수준을 제어한다.
기울기는 유사한 형태를 가진다:
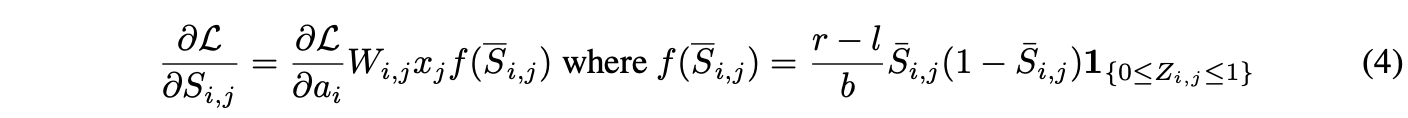
테스트 시에는 마스크의 비확률적인 추정이 사용되며, 가중치에 0을 곱하면 간단히 버릴 수 있다:

 Table 1은 각 절단 방법의 특성을 강조하고 있다. 주요 차이점은 마스킹 함수, 절단 구조 및 최종 기울기 형태에 있다.
Table 1은 각 절단 방법의 특성을 강조하고 있다. 주요 차이점은 마스킹 함수, 절단 구조 및 최종 기울기 형태에 있다.
