Github : https://github.com/csarron/PuMer
Paper : https://aclanthology.org/2023.acl-long.721/
이전 글 👉🏻 [논문 읽기 #3] PuMer: Pruning and Merging Tokens for Efficient Vision Language Models
💡 로 표시된 부분은 제가 이해한 내용을 적은 부분입니다. 오류가 있다면 댓글로 남겨주세요 🙏🏻
Evaluation Setup
Backbone Vision-Language Models
ViLT
-
텍스트를 인코딩하기 위해 BERT 임베딩을 사용하고 이미지 패치를 텍스트와 동일한 공간으로 매핑하기 위해 선형 레이어를 사용하는 최근에 개발된 효율적인 VL 모델이다.
-
텍스트 및 이미지 토큰을 연결하고 12개의 레이어 트랜스포머 인코더를 사용하여 cross-modal fusion을 수행한다.
-
비교적 가벼운 모델이며 110백만 개의 매개변수를 가지고 있다.
METER
-
RoBERTa를 텍스트 인코더로, CLIP을 이미지 인코더로 사용하고 텍스트와 이미지 모달리티를 fusion하기 위해 12개의 BERT-스타일 cross-attention 레이어를 사용하는 최첨단 VL 모델이다.
-
큰 모델이며 330백만 개의 매개변수를 가지고 있다.
Evaluation Tasks
Image-Text Retrieval
이미지-텍스트 검색에는 두 가지 하위 작업이 포함되어 있다.
- 이미지-텍스트 검색 (IR)
- 텍스트-이미지 검색 (TR)
PuMer를 파인튜닝하고 Flickr30K에서 평가했다.
Visual Question Answering (VQAv2)
시각적 질문 응답(VQAv2) 데이터셋은 MSCOCO 및 현실 세계의 장면에서 얻은 다양한 개방형 질문 100만 개 이상을 포함하고 있다.
- 비전, 언어 및 상식 지식을 이해하고 있는지 파악
Visual Entailment (VE)
시각적 엔테일먼트(VE)는 시각적 추론 작업으로, 스탠포드 자연 언어 추론 코퍼스와 Flickr30k에서 추출한 57만 개의 문장 이미지 쌍으로 구성되어 있다.
- 이미지 전제가 텍스트를 의미적으로 포함하는지 예측
Natural Language for Visual Reasoning (NLVR2)
시각적 추론 (NLVR2) 코퍼스는 인간에 의해 작성된 언어적으로 다양한 영어 문장 10만 개 이상을 가지고 있으며 시각적으로 복잡한 이미지 쌍에 기반한다.
- 두 입력 이미지에 대한 문장이 사실인지 예측
Baselines
DynamicViT
MLP로 매개변수화된 여러 예측 모듈을 디자인하여 비전 트랜스포머에서 어떤 이미지 토큰을 제거할지 예측한다.
- 공정한 비교를 위해 ViLT 모델의 원래 DynamicViT 설정(제거 레이어 및 비율)을 사용한다.
ToMe
비전 트랜스포머에서 토큰 병합을 사용하여 토큰 수를 줄인다. ToMe를 PuMer와 유사한 속도 향상을 보장하도록 구성하고 그들의 정확도를 비교한다.
DynamicViT와 ToMe 모두 비전 트랜스포머를 위해 설계되었으며 이미지 모드에서 작동하므로 이미지와 텍스트 토큰을 구분하지 않는다.
반면 PuMer는 텍스트를 사용하여 이미지 제거를 안내하고 병합 모달리티를 인식하는 보다 일반적인 토큰 축소 프레임워크다.
Smaller Resolution (SmRes)
입력 이미지를 작은 해상도로 다운샘플링하고 VL 모델을 파인튜닝한다.
더 작은 입력 이미지를 사용하면 VL 모델의 계산 양이 직접 감소한다.
Evaluation Metrics
Accuracy Metrics.
VQAv2 데이터 세트에 대한 VQA 정확도 및 VE 및 NLVR2 데이터 세트에 대한 정확도를 측정한다.
텍스트 검색 (TR) 및 이미지 검색 (IR) 작업의 경우 정확도는 Top1-recall을 나타낸다.
이전 연구에서는 모델이 훈련 및 검증 세트를 결합하여 훈련되었지만, 최신 결과를 얻는 것이 목표가 아니므로 두 VL 모델을 훈련 세트에서 훈련하고 테스트 세트에서 결과를 보고한다.
모든 정확도 숫자는 3 번의 실행을 통해 얻은 평균 값이다.
Efficiency Metrics.
추론 처리량 측정
-
GPU 하드웨어에서 VL 모델의 실제 추론 처리량 (초당 예제)을 측정하고 원래의 파인튠된 모델과 비교하여 증가한 추론 처리량을 보고한다.
-
GPU 메모리가 부족할 때까지 배치 크기를 늘리고, 단일 GPU에서 30 초 동안 가장 큰 추론 처리량을 제공하는 배치 크기로 추론을 실행한다.
메모리 양 측정
-
모델 추론 단계에서 사용되는 최대 메모리 양을 측정하고 원래의 파인튠된 모델과 비교하여 메모리 감소 비율을 보고한다.
-
추론 메모리 풋 프린트의 경우 원래 VL 모델과 PuMer 버전에 동일한 배치 크기를 사용하고 최대 메모리 차이를 보고한다.
ViLT 모델의 경우 GTX 1080 Ti GPU를 사용하고 32에서 시작하여 8 단계로 배치 크기를 증가시키고, METER 모델의 경우 A40 GPU를 사용하고 16에서 시작하여 8 단계로 배치 크기를 증가시켰다.
이 두 실행 시간 메트릭은 실제 효율성을 반영하며 FLOPs 복잡성 메트릭 을 사용하는 대신 리소스 소비를 비교하는 데 더 정확하게 사용된다.
Experimental Results
Main Results
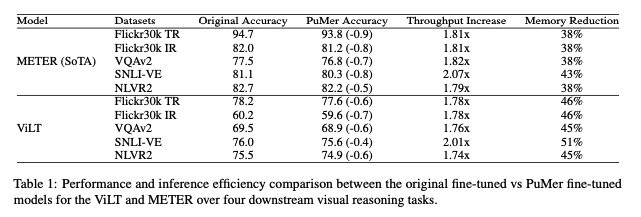
PuMer is faster and remains accurate.
전반적으로 VL 작업에서 ViLT 및 METER 모델 모두에서 1.7배 ∼ 2배 이상의 추론 처리량 증가와 메모리 풋 프린트 감소율이 35% ∼ 51%를 관찰했다.
중요한 것은 PuMer의 작업 성능이 정확도에서 <1% 정도의 감소만 있으면서 원래 파인튠된 VL 모델과 경쟁력을 유지했다.
PuMer is more accurate and faster than previ- ous token reduction methods.
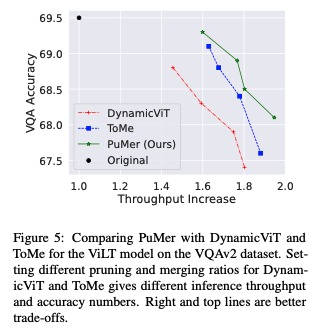
PuMer는 이전의 토큰 감소 방법보다 정확하고 빠르다. 위 그래프는 VQAv2 데이터 세트에서 ViLT 모델에 적용된 PuMer, DynamicViT 및 ToMe의 정확도 대 추론 처리량 증가 트레이드 오프를 나타낸다.
유사한 추론 처리량 증가가 주어진 경우, PuMer는 DynamicViT 및 ToMe와 비교하여 최고의 정확도를 제공한다.
마찬가지로 정확도 감소 제약 (예: <1%)이 주어진 경우, PuMer는 더 큰 추론 처리량 증가를 제공한다.
PuMer provides larger efficiency gains over smaller resolution baselines.
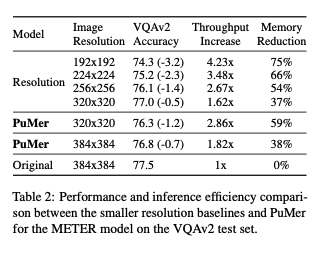
PuMer는 작은 해상도 베이스라인보다 효율성 향상이 더 크다.
VQAv2 데이터 세트에서 METER 모델에 대한 PuMer와 입력 이미지를 작은 해상도로 다운샘플링하는 경우의 결과를 보여준다. 작은 해상도 입력 이미지를 사용하면 추론 처리량이 향상되고 메모리 풋프린트가 감소하지만 정확도가 크게 감소한다. 가장 가까운 해상도는 320x320이며 PuMer보다 0.2% 정확하지만 추론 처리량이 20% 낮다.
PuMer는 다운샘플링 전략과 별개이며, 작은 이미지에 PuMer를 적용하면 추가적인 효율성 향상이 가능할 수 있다. 입력 이미지 해상도 320x320의 경우, PuMer는 0.7% 정확도 감소로 METER 추론 처리량을 1.76배 향상킨다.
Memory Footprint
특정 프로세스, 애플리케이션 또는 시스템이 메모리 내에서 사용하는 메모리 양을 나타낸다.
프로그램이 실행될 때 해당 프로그램이 시스템의 메모리 자원을 어떻게 사용하는지를 측정하는 데 도움이 된다.
Ablation Study
Ablation Study
모델이나 알고리즘의 어떤 "특성"을 제거하고 그것이 성능에 어떤 영향을 미치는지를 관찰하는 연구를 의미한다.
출처 : https://www.quora.com/In-the-context-of-deep-learning-what-is-an-ablation-study
Effectiveness of PuMer Components.
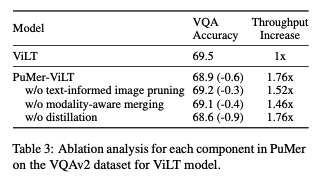
PuMer 구성 요소의 효과적인 작동을 보여주기 위해 PuMer의 세 가지 구성 요소를 삭제하는 실험을 수행했다.
- text-informed image pruning
- modality-aware merging
- distillation
위 표는 각 구성 요소가 VL 작업 정확도와 모델 추론 효율성에 어떤 영향을 미치는지를 보여준다.
텍스트 기반 이미지 가지치기 또는 모드 별 병합을 개별적으로 적용하면 모델 추론 처리량을 향상시키면서 정확도 감소가 적었음을 볼 수 있다. 그러나 두 기술을 함께 적용하면 작업 성능을 크게 잃지 않으면서 더 큰 추론 효율성을 제공한다.
지식 증류 없이도 PuMer는 정확하고 빠르며, 지식 증류를 추가하면 성능 간격이 더욱 줄어든다.
Token Reduction Design Choices.
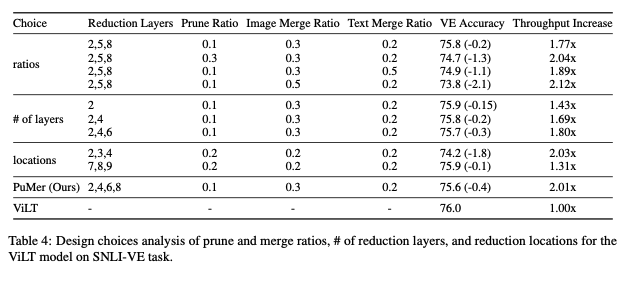
다양한 위치와 비율의 축소 조합이 유사한 추론 속도 향상을 얻을 수 있다.
-
초기 레이어에서 토큰을 감소시키고 비율을 낮게 유지하고, 나중에 레이어에서 높은 비율로 가지치기하는 것과 유사한 계산 효율성을 얻을 수 있다.
-
위 표에서 4개 레이어(2번째, 4번째, 6번째, 8번째)에서의 연속적인 축소가 더 높은 정확도와 속도 향상을 제공하는 것을 볼 수 있다.
-
"ratios" 행에서는 더 많은 토큰을 축소(가지치기 또는 병합)하면 더 큰 추론 처리량 향상이 있지만 상당한 정확도 감소(1% 이상)가 발생하는 것을 볼 수 있다.
-
"locations" 행에서는 초기 레이어에서 토큰을 축소하면 큰 추론 처리량 향상이 있지만 정확도가 1.8% 감소하는 반면, 나중 레이어에서 토큰을 축소하면 약간 더 정확하지만 처리량에 미미한 이점을 제공한다.
전반적으로, SNLI-VE 작업의 ViLT의 경우, 이미지와 텍스트에 대해 가지치기 비율이 0.1이고 병합 비율이 각각 0.3과 0.2인 4층 계단식 토큰 감소 전략을 선택하고, 정확도와 속도 균형을 맞추기 위해 감소 위치를 더 균일하게 분산시킨다.
SNLI-VE
"Visual Entailment (VE)" 작업을 위해 제안된 데이터셋이다.
VE
전제가 자연어 문장이 아니라 이미지에 의해 정의되는 이미지-문장 쌍으로 이루어진 작업이다. 목표는 이미지가 문장을 의미적으로 포함하는지 여부를 예측하는 것이다.
출처 : https://paperswithcode.com/task/visual-entailment#:~:text=Visual%20Entailment%20(VE)%20%2D%20is,image%20semantically%20entails%20the%20text.
Conclusion
대규모 비전 언어 모델은 텍스트와 이미지 토큰 간의 복잡한 교차 모달 상호 작용 덕분에 시각적 추론 작업에서 효과적이다. 그러나 이러한 교차 모달 상호 작용은 모든 이미지 및 텍스트 토큰이 많은 레이어에서 처리되기 때문에 계산적으로 비용이 많이 든다.
PuMer라는 토큰 축소 프레임워크는 텍스트 기반 이미지 가지치기 및 모달리티 인식 병합 기술을 사용하여 교차 모달 레이어 내부의 이미지 및 텍스트 토큰을 효과적으로 축소한다.
중복되는 이미지 및 텍스트 정보를 점진적으로 제거하며 작업 성능 하락을 최소화하면서 VL 모델을 더 빠르게 실행할 수 있게 한다. 또한, 훈련이 쉽고 시각 및 언어 모델의 훈련 및 추론 속도를 다양한 하향식 시각적 추론 작업에서 가속화할 수 있다.
Limitations
PuMer는 교차 모달 인코더 레이어가 비교적 가벼운 VL 모델에는 적용되지 않는다. ALBEF 및 X-VLM과 같은 VL 모델의 경우 비전 인코더가 교차 모달 인코더보다 훨씬 계산 비용이 많이 든다.
따라서 이러한 모델의 종단 간 추론 속도 향상은 미미하다. 비전 인코더 내부의 이미지 토큰을 줄이면 모델 효율성을 더 향상시킬 수 있으나, 이에 대한 탐구는 향후 연구에 남겨두었다.
