Github : https://github.com/FranxYao/FlanT5-CoT-Specialization
Paper : https://arxiv.org/abs/2301.12726
💡 로 표시된 부분은 제가 이해한 내용을 적은 부분입니다. 오류가 있다면 댓글로 남겨주세요 🙏🏻
Abstract
모델 특화를 제안하여 모델의 능력을 특정 작업에 특화시킨다.
가설
-
큰 모델(일반적으로 100B 이상으로 간주됨)은 강력한 모델 능력을 갖고 있지만 여러 작업에 분산되어 있다.
-
작은 모델(일반적으로 10B 이하로 간주됨)은 모델 용량이 제한적이지만 용량을 특정 대상 작업에 집중시킬 경우 모델이 상당히 향상된 성능을 달성할 수 있다.
모델 능력의 두 가지 중요한 측면
-
언어 모델의 다차원 능력 사이에 매우 복잡한 균형 및 교역이 존재한다.
-
일반적인 능력 감소를 대가로 10B 미만의 모델의 특화된 다단계 수학 추론 능력을 향상시킬 수 있다.
또한 더 나은 일반화를 위한 중요한 설계 선택 사항에 대한 포괄적인 논의를 제공하며, 튜닝 데이터 형식, 초기 모델 체크포인트 및 새로운 모델 선택 방법을 다룬다.
1. Introduction
작은 모델에 대한 CoT 추론 문제를 모델 특화를 통해 다룬다.
가설
-
대규모 모델(≥ 100B)은 강력한 모델 능력을 갖고 있지만 여러 작업에 분산되어 있다.
-
작은 모델(≤ 10B)은 모델 용량이 제한적이지만, 모델의 능력을 특정 작업에 집중시키면 모델은 어느 정도 향상된 성능을 보일 수 있다.
작은 모델의 chain-of-thought 능력에 관한 연구가 있지만, 이러한 연구는 일반적인 능력에 중점을 두고 있어서 모델의 능력이 집중되지 않았다.
실험 결과, 일반적인 작업에서 능력이 감소하는 대가로 작은 FlanT5 모델의 CoT 추론 스케일링 곡선을 크게 높일 수 있다는 것을 보여준다.
이로 인해 수학 추론 작업 4개의 그룹(1개는 분배, 3개는 분배 외)에 대한 평균 +10 정확도 향상을 달성했다.
이것은 모델의 능력을 일반적인 능력에서 특정 작업의 CoT에 집중시킬 수 있다는 것을 의미한다.
접근 방식은 대규모 교사 모델(GPT-3.5 code-davinci-002 Chen et al., 2021)의 GSM8K 데이터의 chain-of-thought 추론 경로를 fine-tune하는 것이며, 그런 다음 세 가지 보류 중인 수학 추론 데이터의 평균 성능에 대한 모델 선택을 수행하여 분배에서의 일반화를 보장한다.
따라서 지식 전이(distillation) 자체는 잘 연구된 분야이지만, 본 논문의 프로세스에는 여러 가지 주의할 점이 있다.
-
교사 모델 코드-davinci-002와 학생 모델 FlanT5은 서로 다른 토크나이저를 사용하므로, 토크나이저 정렬 문제를 동적 프로그래밍을 사용하여 해결한다.
-
지식 전이는 FlanT5와 T5(원래 pretrained 모델) 사이에서 지시어 튜닝 체크포인트에서 다른 성능을 나타낸다. 특화된 FlanT5이 더 나은 성능을 보이지만 특화된 T5이 더 많은 정확도 향상을 달성한다.
-
훈련의 마지막 단계에서 모델의 분배 내성 및 분배 외성 (OOD) 성능이 다르게 변동하므로, 더 나은 OOD 일반화를 원한다면 모델 선택은 튜닝 데이터의 검증 부분이 아닌 보류 중인 수학 데이터에서 수행되어야 한다.
-
지식 전이/특화 과정 중에 여러 가지 교환점이 발생한다. 지식 전이를 시작하면 BigBench Hard 테스트 그룹(일반 능력의 측정)에서 모델은 즉시 CoT 프롬프팅 능력을 모두 잃고, 점진적으로 대부분 답변 전용 프롬프팅 능력을 잃어버린다. 튜닝에 사용하는 데이터 형식은 모델 능력과 밀접한 관련이 있으며, 컨텍스트 예제는 컨텍스트 및 제로샷 성능을 모두 활성화하지만 제로샷 예제는 모델의 컨텍스트 능력을 잃고 제로샷 능력을 향상시킨다.
이러한 결과는 언어 모델의 chain-of-thought 추론 행동을 여러 가지 측면에서 더 깊이 이해하게 도와준다.
이전 가설은 CoT가 작은 규모에서 거의 플랫한 스케일링 곡선을 가진다고 주장했다. 그러나 이 연구에서는 모델의 용량을 특정 능력에 집중시킴으로써 스케일링 곡선을 높일 수 있다는 것을 보여준다. 이것은 chain-of-thought가 작은 모델에서는 제한적일 수 있지만, 모델을 특화시킨 후에는 스케일링 곡선이 로그-선형으로 변화하여 대규모 모델과 유사한 성능을 나타낼 수 있다는 것을 나타낸다.
이전의 언어 모델 행동 관찰은 여러 차원을 가로지르는 모델 능력의 복잡한 교환점과 균형을 나타낸다. 이 연구에서는 모델의 능력을 일반적 능력에서 특정 능력으로 어떻게 이동시키는지에 대한 자세한 설명을 제공하며, 어떤 비용으로 어떤 이점을 얻을 수 있는지 명확하게 보여준다.
고전적인 모델 선택 이론은 동일한 데이터 세트의 검증 부분에서 모델을 선택한다. 그러나 이 연구에서는 다양한 수학 추론 데이터 세트의 성능을 기반으로 모델을 선택함으로써 단일 데이터 세트에 대한 과적합을 방지한다.
Background
Large Language Models’ Abilities

LLMs를 훈련하는 새로운 접근 방식은 먼저 기본 모델을 훈련한 다음, 기본 모델의 능력을 명령 튜닝을 통해 끌어내는 것이다.
- GPT-3 → InstructGPT
- PaLM → FlanPaLM
- OPT → OPT-IML
기본 모델의 경우, 처음에는 모델 크기가 100B보다 작은 경우 chain-of-thought 성능 곡선이 거의 제로라고 보여주었다.
그러나 이후 연구에서 CoT 데이터가 명령의 한 종류로 포함되면 CoT를 활성화할 수 있다는 가설을 업데이트하면서, 그들의 모델 능력이 여러 가지 차원에 분산되어 있기 때문에 그들의 모델 성능이 좋지 않은 것으로 나타났다.
이 연구는 모델의 능력을 특정 능력에 집중시킴으로써 CoT 성능을 상당히 향상시킬 수 있다는 것을 보여준다.
Specialized Language Models
현대 언어 모델은 다양한 작업에 뛰어난 능력을 보이지만, 최근 연구는 모델이 특정 작업에 중점을 두는 경향이 있다는 것을 밝혔다.
예를 들어, 어떤 모델은 코드 작업에 더 특화되어 있고, 다른 모델은 텍스트 작업에 뛰어난 성과를 보일 수 있다.
큰 모델의 경우, 이러한 특화 작업과 일반 작업 사이에서 균형을 맞출 수 있지만, 작은 모델은 한 가지 특정 능력을 위해 일반 능력을 모두 포기해야 한다.
특화 모델을 만들기 위한 주요 방법은 모델을 관련 데이터로 미세 조정하는 것이다. 그러나 이 작은 모델은 미세 조정 데이터에만 지나치게 적응하고, 데이터 분포가 변할 때 일반화하는 데 어려움을 겪을 수 있다.
이에 대한 커뮤니티의 가설은 모델 크기와 명령 튜닝과 관련이 있으며, 모델이 훈련 데이터 외부에서 얼마나 잘 수행되는지에 영향을 미친다.
본 논문은 언어 모델이 어떻게 일반 능력을 특화된 능력으로 교환하고, 모델 크기와 명령 튜닝이 모델이 다양한 작업에서 어떻게 성능을 향상시킬 수 있는지에 대해 보여준다.
Distillation and Data Augmentation
우리가 code-davinci-002에서 생성된 데이터를 사용하여 작은 FlanT5를 튜닝하는 방식은 별도의 지식 추출(distillation) 또는 데이터 증강(data augmentation)으로 볼 수 있다.
여기서 주목해야 할 점은 생성된 데이터를 모델 특화의 도구로 사용하며, 특화 데이터는 인간 주석과 같은 다른 출처에서도 나올 수 있다는 것이다.
본 논문의 주요 관심사는 특화 중 능력 교환을 연구하는 것이며, 지식 추출 또는 데이터 증강 문헌에 직접적으로 기여하는 것이 아니다.
Most closely related works
-
FlanT5 (Chung et al., 2022)와 UL2 (Tay et al., 2022)는 작은 모델의 CoT 능력에 대한 첫 번째 연구로, 그러나 그들은 일반적인 CoT에 중점을 두었으며, 본 논문에서는 일반 능력을 수학 CoT로 교환하는 방식을 연구했다.
-
언어 모델의 self-improvement에 관한 연구는 CoT 데이터 증강을 사용하지만 큰 모델에만 관련되며 모델 능력 사이의 교환을 보여주지 않는다. 본 논문에서는 작은 모델에 중점을 두고 능력 향상에 대한 비용을 명확하게 보여준다.
Specializing Multi-Step Reasoning
본 논문의 목표는 작은 모델의 chain-of-thought 수학 추론을 어떻게 개선할 수 있는지 연구하는 것이다.
가장 다양한 수학 추론 문제 중 하나인 GSM8K를 시드 데이터셋으로 사용했다.
그러나 모델이 OOD(Out-of-Distribution) 데이터에 일반화되는지를 보여주기 위해 세 가지 추가 수학 데이터셋(MultiArith, ASDiv 및 SVAMP)의 모델 성능을 테스트한다.
또한 모델의 일반 추론 능력과 목표 능력 간의 교환을 보여주며 BigBench Hard를 사용하여 모델의 일반적인 추론 능력을 테스트했다.
기본 모델로 T5 (원시 사전 훈련 체크포인트)와 FlanT5 (명령 튜닝 체크포인트) 를 사용하고, 지식 추출/특화 데이터 생성을 위해 code-davinci-002를 사용했다.
Distillation from Code-Davinci-002
훈련용 질문 데이터 세트가 주어진 경우, code-davinci-002를 사용하여 40개의 새로운 CoT 솔루션을 생성한 다음 올바른 답변으로 이어지는 것을 훈련 데이터로 사용했다. 하나의 솔루션은 답변과 답변을 찾기 위한 중간 단계를 설명하는 CoT 체인을 포함한다.
일반적인 파인튜닝 설정과 더불어 입력으로 질문을 사용하고 출력으로 [CoT, 답변] 쌍을 사용하는 설정 이외에도 세 가지 추가 데이터 형식을 고려했다.
-
in-context 답변만 사용하지 않고 질문 앞에 4개의 in-context 예제를 덧붙인 형식이다. 이전 연구에서 in-context 예제를 사용하면 모델의 인-컨텍스트 학습 능력이 향상된다는 것을 보여줬기 때문이다.
-
in-context chain-of-thought
in-context 예제 및 출력에 CoT를 추가한 형식이다. -
zero-shot answer-only
질문을 직접 입력하고 답변을 출력한다. 답변만 데이터를 사용하는 이유는 이전 연구에서 성능을 향상시킨다는 것을 보여주기 때문이다.
우리의 실험에서는 in-context 데이터가 제로 샷 능력을 유발하지만 제로 샷 데이터는 in-context 학습 능력을 희생시킨다는 것을 보여준다.
또한, 계산기 추가 (Cobbe et al., 2021)나 자체 일관성 디코딩 (Wang et al., 2022)과 같은 기술들이 성능을 더욱 향상시킬 수 있다.
이러한 기술들은 본 논문의 지식 추출과는 관련이 없으며, 미래의 작업을 위해 이러한 기술을 통합할 수 있을 것이다.
훈련 목표 측면에서, 지식 추출 문헌에서는 일반적으로 두 가지 유형의 추출 방법이 있다:
-
샘플 일치(sample matching)
학생 모델을 선생님이 생성한 데이터로 훈련한다. 본 논문의 경우, 샘플 일치는 코드-다빈치-002가 생성한 데이터에 대한 학생의 가능성을 직접 최적화하는 것을 의미한다.
-
분포 일치(distribution matching)
여기서 학생의 출력 분포(본 논문의 경우 단계별 자기 회귀 분포)와 선생의 분포 간의 KL 발산을 최소화한다.
일반적으로 분포 일치가 샘플 일치보다 빠르게 수렴하고, 더 나은 성능을 달성하는 것으로 나타나므로 본 논문에서는 훈련 목표로 분포 일치를 사용했다.
분포 일치에는 분포 매개 변수를 저장하는 추가적인 어려움이 있다.
각 단계에서 우리는 어휘 V에서 정의된 전체 분포를 저장해야 하므로 데이터 집합의 크기는 샘플 일치보다 |V| 배 크다.
그러나 OpenAI API는 각 디코딩 단계에서 가장 가능성 높은 5개의 토큰에만 액세스를 허용하며 전체 어휘에 대한 확률 분포를 제공하지 않는다.
단계별 분포는 주로 상위 5개 토큰을 다루지만 대부분의 경우 그들의 확률 합이 1에 가까워 전체 어휘 분포의 좋은 근사치가 된다.
본 논문에서는 상위 5개 토큰에 없는 토큰의 확률을 0으로 설정한다.
Aligning tokenizers by dynamic programming
두 분포를 일치시킬 때의 문제 중 하나는 GPT 토크나이저와 T5 토크나이저 사이의 정렬이 잘못될 수 있다는 것이다. 따라서, 동적 프로그래밍을 사용하여 이 문제를 해결한다.
구체적으로, 두 토큰 시퀀스 [s1:L, t1:N] 가 주어지면, 한 시퀀스를 다른 시퀀스로 편집하는 데 드는 총 비용을 최소화하는 정렬을 찾는 것을 목표로 한다.
일반적으로 생물 정보학에서 시퀀스 정렬에 사용되는 동적 프로그래밍 알고리즘 및 신호 처리에서 사용되는 동적 타임 래핑과 유사한 알고리즘을 사용했다.
재귀 함수 :
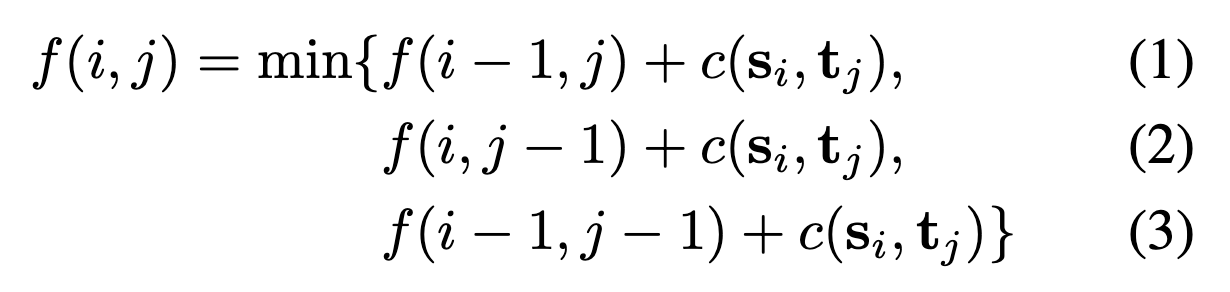
f(i, j) : s1:i와 t1:j를 정렬하는 데 드는 총 비용
c(si, tj) : 토큰 si와 tj 사이의 미리 정의된 문자열 편집 거리
해당 알고리즘은 두 시퀀스의 토큰 간의 일대일 대응을 강제하지 않으며, s의 하나의 토큰이 t의 여러 토큰과 일치하거나 그 반대가 가능하다.
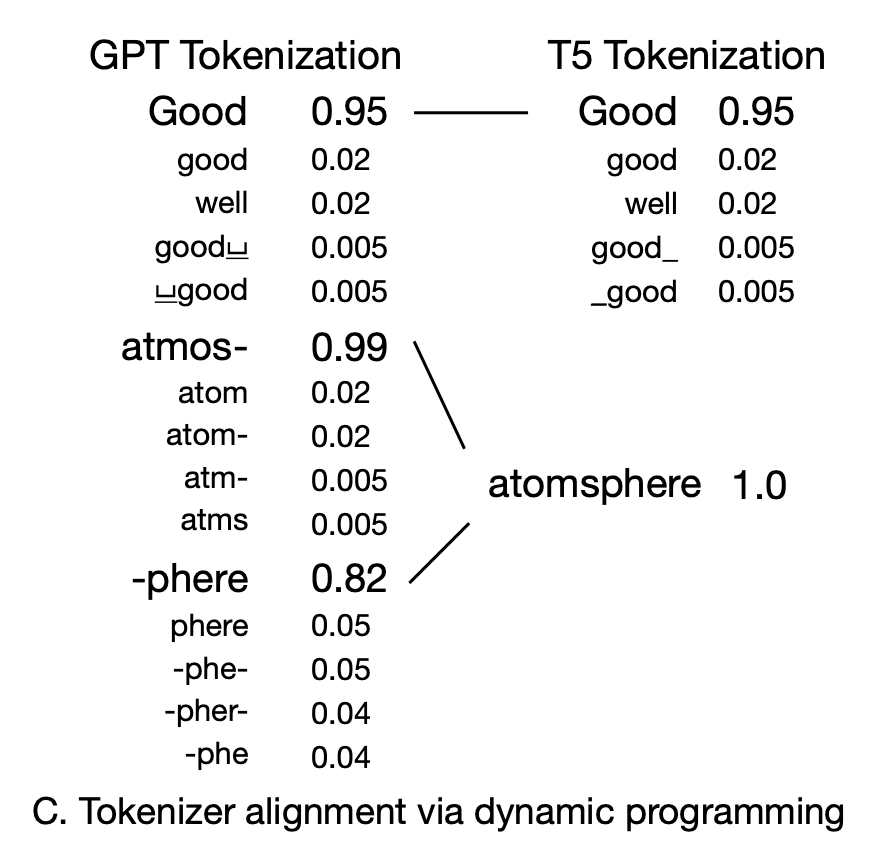
GPT 토큰과 T5 토큰 간에 일대일 대응이 있는 경우 GPT 분포를 T5 분포로 사용한다.
일대일 대응이 아닌 경우, 예를 들어 두 개의 T5 토큰이 하나의 GPT 토큰에 매핑되거나 두 개의 GPT 토큰이 하나의 T5 토큰에 매핑되는 경우 (그림 하단), 해당 GPT 분포를 사용하지 않고 T5 분포를 원핫으로 설정한다.
또한, 다른 토크나이저에 의해 생성된 시퀀스를 정렬하는 것은 현대 NLP의 일반적인 문제이지만 이에 접근하는 기존 라이브러리에 대한 정보는 없다.
Experiments
-
대규모 모델이 다양한 작업에서 우수한 성과를 내지만 작은 모델의 능력은 일반적 능력에서 특화된 목표 능력으로 옮길 수 있다는 주요 가설을 확인한다.
구체적으로, FlanT5-Base / Large / XL / XXL의 CoT 수학 성능을 개선할 수 있음을 보여준다.
이 과정에서 일반 능력, 즉 BigBench Hard에서의 모든 CoT 능력 및 대부분의 답변 전용 능력을 잃는 대가를 지불한다.
-
작은 모델의 스케일링 동작을 연구하고 목표 능력을 향상시키는 방법이 T5와 FlanT5 모두의 스케일링 곡선을 높이는 방법을 보여준다.
이로써 이전에 작은 모델이 평평한 스케일링 곡선을 나타낸다는 믿음을 수정한다.
특화 이후에 그들의 스케일링 곡선이 로그 선형으로 변환되지만 평평하지 않다는 것을 볼 수 있다.
-
특화의 동작과 일반화 동작을 보여준다.
모델의 목표 성능은 조금씩 증가하지만 튜닝 과정 중에 일반 능력이 점차 감소하며, 분포 중앙, OOD 성능 및 in-context, 제로-샷 성능 간의 트레이드오프가 존재한다.
Further Design Choices Analysis
두 가지 설계 선택 사항에 대한 더 자세한 연구를 수행했다.
-
분포 일치 대 샘플 일치를 사용한 증류에서, 분포 일치가 빠른 수렴을 제공하고 샘플 일치에 비해 더 낮은 손실을 갖는 것을 확인했다.
이 두 방법은 검증 성능 측면에서 큰 차이가 없었지만 분포 일치는 빠른 수렴을 제공하므로 모델이 커지고 튜닝이 비용이 많이 드는 경우 먼저 고려될 수 있다.
분포 일치
FlanT5의 단계별 자기 회귀 분포와 GPT의 자기 회귀 분포 간의 KL 발산을 최소화한다.
샘플 일치
GPT에서 생성된 추론 경로의 가능성을 최대화한다.
-
데이터 형식의 영향과 특화된 모델의 다른 동작을 다루었다.
in-context 데이터 형식은 zero-shot 능력을 보존하면서 in-context 학습 능력을 유지한다.
zero-shot 데이터 형식은 zero-shot 성능을 향상시키지만 in-context 학습 능력을 상실하는 경향이 있다.
따라서 실제로는 튜닝 시 다양한 데이터 형식을 혼합하거나 사용 사례에 따라 다른 형식의 비율을 조절하는 것을 권장한다.
Conclusion
이 연구에서는 작은 언어 모델을 다단계 추론을 수행하는 데 전문화시키는 문제를 다루었다.
작은 모델의 능력을 일반적인 방향에서 목표 수학 추론 작업으로 집중시킬 수 있다는 것을 보였다.
특화 이후, 모델의 성능이 모델 규모가 증가함에 따라 부드럽게 증가하는 로그-선형 스케일링 곡선을 나타내며, 이로써 작은 모델의 스케일링 곡선은 증가하지 않는 평평한 곡선을 가진다는 이전 가설의 수정 사항임을 밝혔다.
또한, 기본 모델로서 명령어 조정된 체크포인트를 사용하는 중요성을 강조했다.
모델 특화 중에 여러 가지 트레이드오프가 발생하는데, 이는 BBH 성능 손실, 분포 일치 및 샘플 일치의 균형, in-context 학습 및 zero-shot 일반화 능력의 균형 등을 포함한다.
